AI/추천 시스템
Side Information과 이를 사용하는 추천 시스템
- -
Side-information을 사용하는 추천 시스템
기존 CF(Collaborative Filtering)의 한계
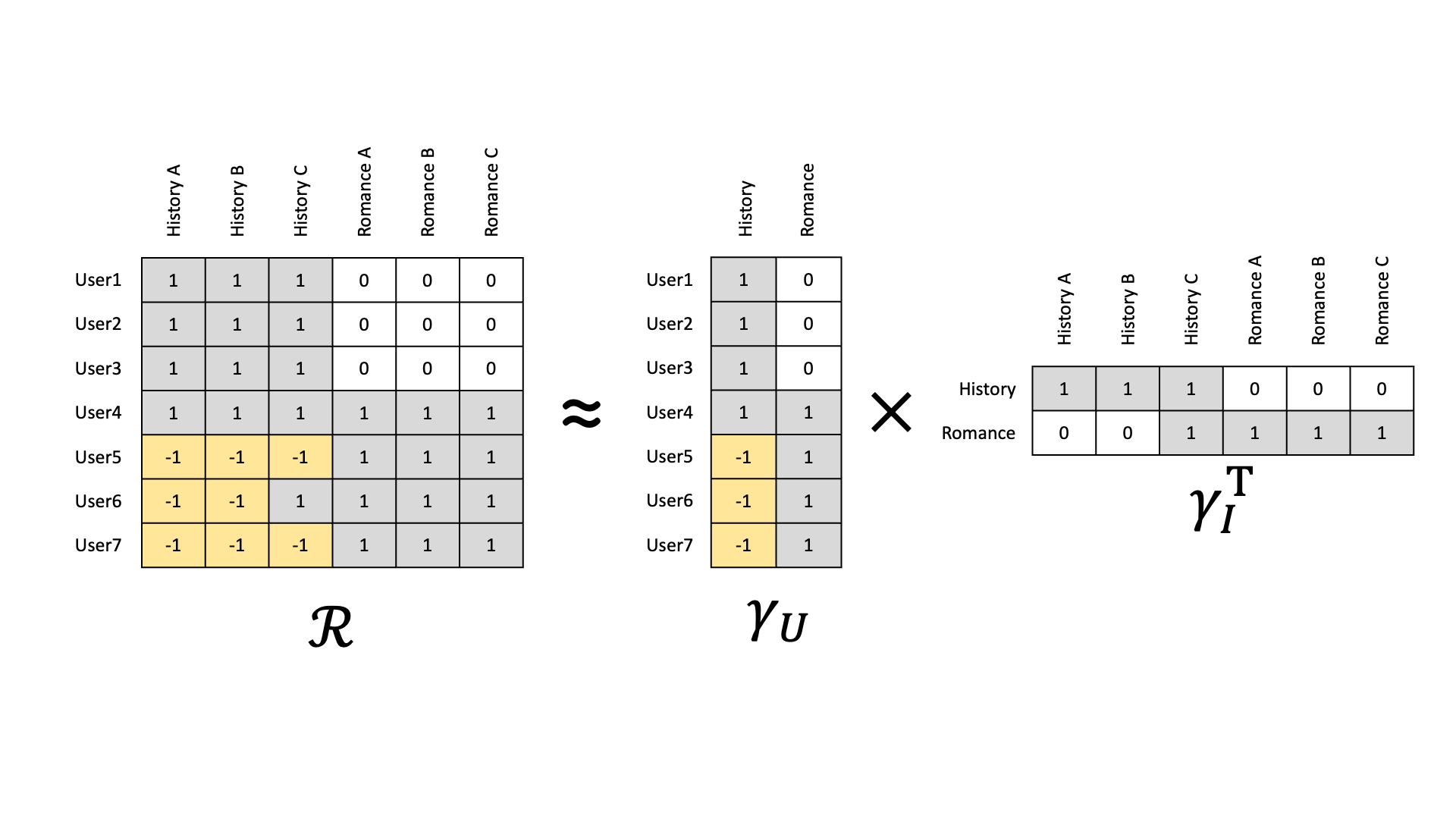
지금까지 논의한 CF의 기본적인 가정은 상호작용 데이터로부터 사용자와 아이템 간의 숨겨진 패턴을 찾아내고 이를 추천에 활용하는 것이다.
즉, 상호작용 데이터로부터 학습된 잠재적인 사용자($\gamma_u$) 또는 아이템 feature($\gamma_i$)가 기존에 존재하는 명시적인 feature를 대체할 수 있다는 접근 방식이다.
그러나 이러한 CF의 기본적인 가정이 성립하지 않는 추천 시나리오도 존재한다.
추천 결과가 왜 이렇게 나오는지에 관한 interpretability를 요구하는 시나리오, user-item 추천이 아닌 친구 추천 또는 데이터 앱 매칭 등 social recommendation, 광고 예산 등 제약 조건을 준수해야 하는 online advertising과 같은 다른 시나리오에서는 앞서 논의한 CF의 기본 가정이 잘 들어맞지 않는 경우가 많다.
Cold-Start Problem
상호작용 데이터가 충분치 않아서 사용자와 아이템의 latent factor를 잘 학습할 수 없는 경우를 의미한다.
즉, 수집된 상호작용 데이터가 매우 적거나 존재하지 않는 사용자 또는 아이템에 관해 올바른 추천을 제공하기 어려운 상황을 뜻한다.
그래서 새로운 사용자에 관해서는 가장 인기 있는 아이템이 추천 결과로 나올 수 있다.
특히, 상호작용 데이터만을 사용하는 CF가 이러한 문제를 자주 겪는다고 알려져 있다.
이를 완화하려면 Content-based method처럼 사용자 또는 아이템의 side-information을 활용하는 것이 필요하다.
Temporal Evolution
기존 CF에서 $R_ui \approx f(u,i) = a + \beta_u + \beta_i + \gamma_u + \gamma_i$인 compatibility function은 시간의 흐름에 따른 사용자의 선호도 및 아이템 특성의 변화를 반영하고 있지 않다.
Content-based Method
Content-based method는 다양한 종류의 feature, content 등 side-information을 활용하여 cold-start problem을 완화할 수 있다.
사용자의 입장에서 사용할 수 있는 side-information에는 성별, 나이, 직업, 거주지 등의 인구 통계학적 정보, 친구 관계, 사용자가 직접 작성한 리뷰 또는 댓글 등의 텍스트 정보가 있다.
반면에 아이템 입장에서 사용할 수 있는 side-information에는 추천 시스템 적용 도메인에 따라 다양한 콘텐츠를 지니고 있는데, 예를 들어 영화에서는 영화 장르, 감독, 배우 등이 해당된다.
Content-based method는 아이템의 feature가 풍부한데 반해 관련된 상호작용 데이터가 매우 적은 상황에서 주로 활용할 수 있다.
이러한 방법은 이력이 존재하지 않는 새로운 아이템의 추천 시나리오에 효과적이지만, 직관을 벗어나지 않는 비교적 뻔한 추천 결과를 보여줄 수 있어서 새로운 사용자를 대상으로 하는 추천에는 여전히 한계가 존재한다.
사용자와 아이템과 연관된 historical interaction data가 없는 상황에서 추천은 pairwise preference regression으로 해결할 수 있다.
$$ s_{u, i} = x_u W z_i^T = \sum_{a=1}^{|x_u|} \sum_{b=1}^{|z_i|} x_{u, a} z_{i, b} W_{a, b} $$
$s_{u,i}$: 사용자 $u$와 아이템 $i$의 compatibility
$x_{u, a}$: 사용자 $u$의 $a$번재 벡터
$z_{i, b}$: 아이템 $i$의 $b$번째 벡터
$W_{a, b}$: $x_{u, a}$와 $z_{i, b}$의 상호작용을 표현하는 가중치
위처럼 사용자 feature와 아이템 feature 간의 상호작용을 bilinear regression form 형태로 나타낼 수 있다.
CF와 Content-based Method(CB)는 각각의 장단점으로 인해 서로 보완적인 특성을 지니며, 두 방법의 장점을 모두 취하고자 이 두 가지를 함께 활용하는 hybrid method를 사용하기도 한다. 일반적으로 CB는 개별 방법으로 따로 쓰이기보다는 다른 방법과 결합하여 쓰이는 경향이 있다.
Context-aware Recommendation
Context-aware Recommendation
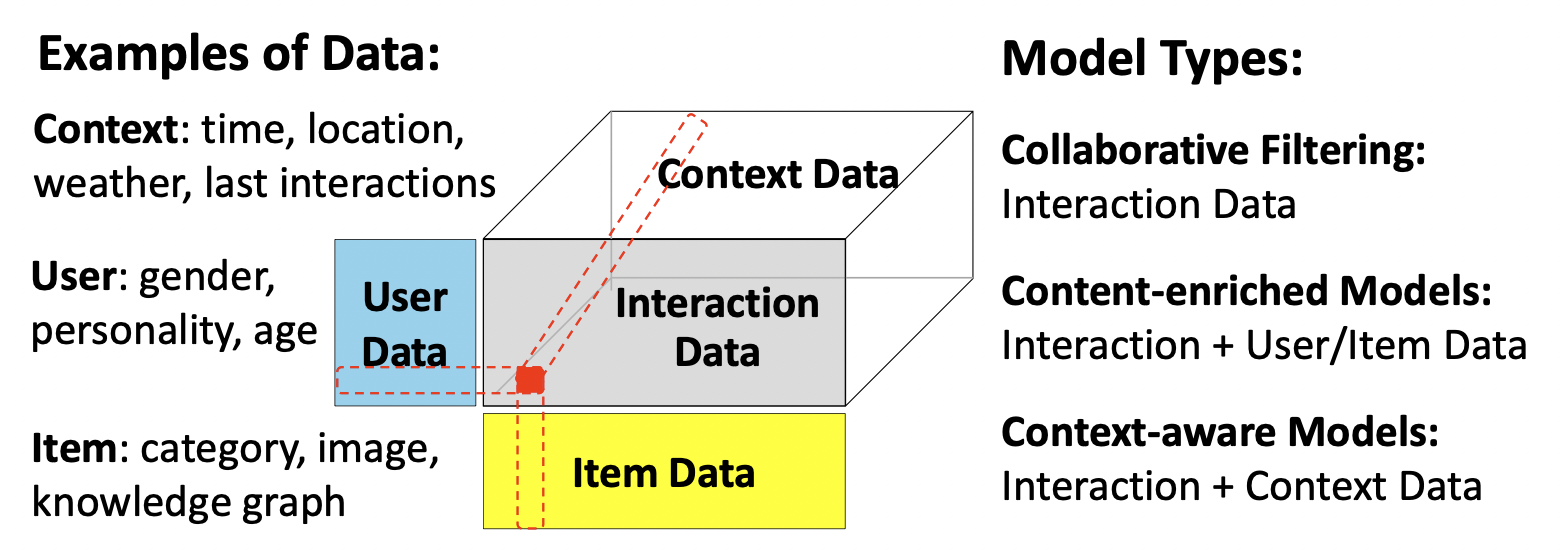
[출처] https://arxiv.org/pdf/2104.13030.pdf, A Survey on Accuracy-oriented Neural Recommendation: From Collaborative Filtering to Information-rich Recommendation
Context-aware Recommendation은 추천이 이루어지는 특정한 상황(맥락)을 나타내는 추가 정보에 따라 추천 결과를 생성하거나 조정한다.
이러한 추가 정보를 context라고 부르며, time, location, social information 등이 이러한 context에 해당된다.
Content-based 방법은 단순히 아이템 또는 유저의 다른 부가적인 속성 또는 정보를 content로 사용하는 것이지만, Context-aware 방법은 해당 유저 또는 아이템이 추천되는 context를 고려하는 것이다.
Context도 어떻게 보면 content-based에서의 side-information 또는 content의 일종이라고 볼 수도 있다.
딥 러닝을 Netflix 추천 시스템에 적용한 경험에 대한 회고를 담은 논문을 살펴보면, context의 중요성을 강조하고 있다.
수많은 다른 종류로 이루어진 type의 feature를 추가했을 때 비로소 DL 모델이 좋은 성능을 보이기 시작한다는 내용이 언급되어 있다.
특히 discrete하고 continuous한 time context를 추가했을 때 ranking에서 더 좋은 성능을 보였음을 말하고 있다.
Context-aware Recommendation의 사례
Factorization Machine
FM(Factorization Machine)에 관한 자세한 내용은 아래 포스트를 참고하면 된다.
추천 시스템 - Context 기반 추천 모델인 FM(Factorization Model)과 FFM(Field-aware Factorization Machine)
2022년 3월 14일(월)부터 18일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거
glanceyes.tistory.com
Factorization Machine은 일반화된 latent factor model의 일종이며, MF를 확장하여 사용자와 아이템 간의 상호작용 뿐만이 아니라 임의의 feature 쌍의 pairwise interaction을 모델링한다.
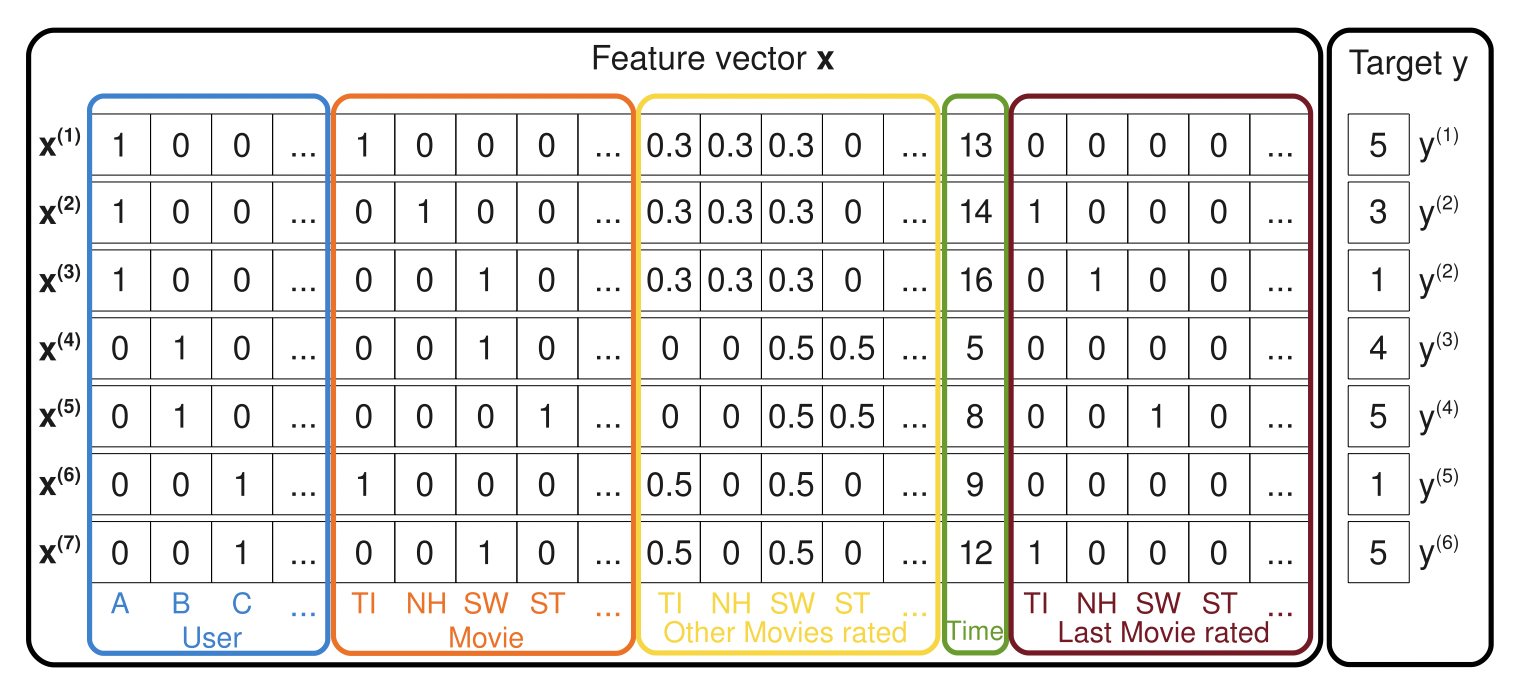
[출처] https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf, Factorization Machines
$$ \hat{y}(\mathbf{x}) := w_0 + \sum_{i=1}^F w_i x_i + \sum_{i=1}^F \sum_{j=i + 1}^F \left< \gamma_i, \gamma_j \right> x_i x_j $$
$\sum_{i=1}^F w_i x_i $: bias term이며, MF에서의 $\beta_u + \beta_i$를 포함하고 있다.
$\sum_{i=1}^F \sum_{j=i + 1}^F \left< \gamma_i, \gamma_j \right> x_i x_j$: feature interaction term이며, MF에서의 $\gamma_i \cdot \gamma_j$를 포함하고 있다.
예를 들어, $u$가 사용자, $i$가 아이템, $p$가 아이템의 가격, $y$가 평점이라고 할 때, FM을 사용하여 $y$ 값을 예측하는 식을 정리하면 다음과 같다.
$$ \hat{y}(\mathbf{x}) := \alpha + \beta_u + \beta_i + p(i) \cdot \beta_p + \gamma_u \cdot \gamma_i + p(i) \cdot \gamma_u \cdot \gamma_p + p(i) \cdot \gamma_i \cdot \gamma_p $$
$\alpha$: global한 offset parameter이다.
$\beta_u$: 사용자 $u$가 높은 평점을 주는 경향이 있는지를 의미하는 bias 값이다.
$\beta_i$: 아이템 $i$가 높은 평점을 받는 경향이 있는지를 의미하는 bias값이다.
$p(i) \cdot \beta_p$: 높은 가격의 아이템 $i$가 높은 평점을 받는 경향이 있는지를 의미하는 bias 값이다.
Wide & Deep Model
Wide & Deep 모델과 DeepFM에 관한 자세한 내용은 아래 포스트를 참고하면 된다.
https://glanceyes.tistory.com/entry/추천-시스템-CTR를-딥러닝으로-예측하는-Wide-Deep-모델과-DeepFM
CTR를 딥러닝으로 예측하는 Wide & Deep 모델과 DeepFM
2022년 3월 14일(월)부터 18일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거
glanceyes.tistory.com
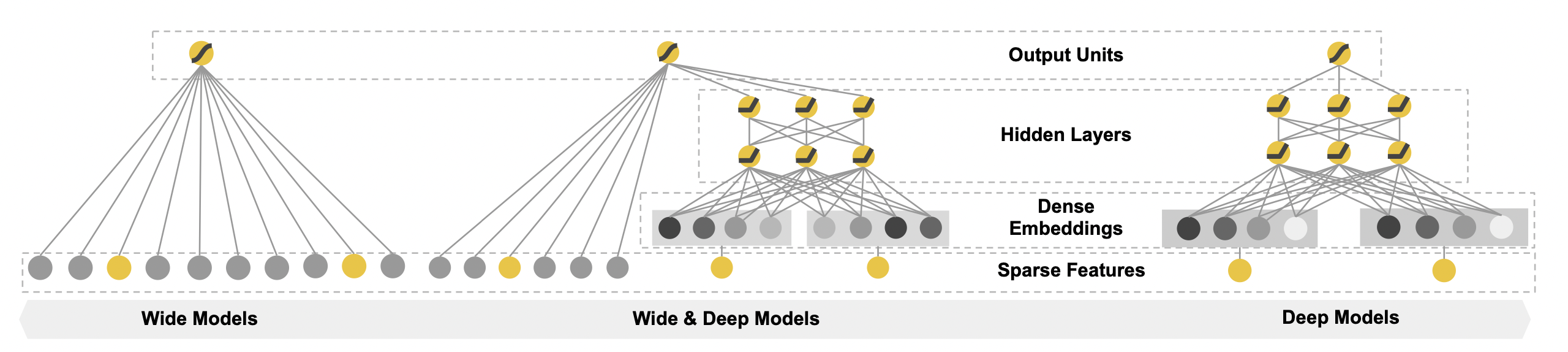
[출처] https://dl.acm.org/doi/pdf/10.1145/2988450.2988454, Wide & Deep Learning for Recommender Systems
Wide Component와 Deep Component를 결합한 모델이며, 다양한 side-information을 자연스럽게 통합할 수 있다.
대표적으로 Wide & Deep Model로 구글 플레이 스토어에서 앱을 추천하는 사례가 논문에 나왔으며, 여기서는 사용자의 나이, 앱 설치 횟수, 참여 세션의 개수, 디바이스 정보 등 앱 설치 상황에서 발생할 수 있는 다양한 context를 새로운 앱 추천에 활용하고 있다.
Wide Component에서는 cross-product transformation(linear regression)을 사용하여 특정 패턴에 관한 memorization을 주로 담당하는 역할을 한다.
그러나 이러한 memorization으로 인해 특정 패턴이 기억되면 overfitting이 되어서 다른 새로운 데이터에 관한 추천에서 좋지 않은 결과를 낼 수도 있다.
Deep Component에서는 일반화된 데이터의 관계를 학습할 수 있어서 generalization의 장점이 있다.
그러나 과도한 generalization으로 인해 사용자의 기호에 맞지 않은 아이템이 추천되는 underfitting의 문제가 발생할 수 있다.
DeepFM
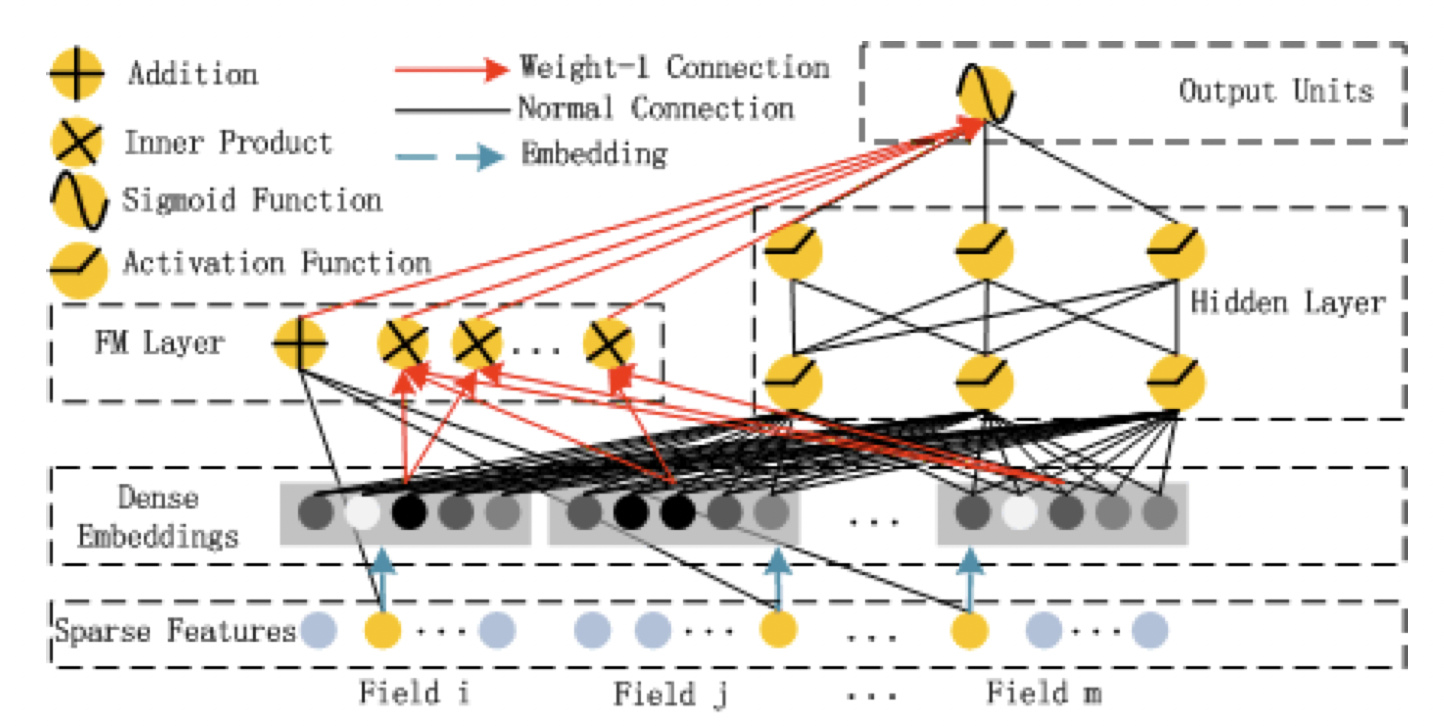
[출처] https://arxiv.org/pdf/1703.04247.pdf, DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM은 wide component로 Factorization Machine을 사용하고, deep component로 DNN을 사용하여 이를 결헙한 형태이다.
Wide & Deep Model과는 다르게 DeepFM에서는 wide compoent와 deep componet가 서로 입력값을 공유한다는 특징이 있으며, wide component 연산에서 FM을 사용함으로써 feature engineering이 필요하지 않게 된다.
Context를 효과적으로 융합하여 사용하기
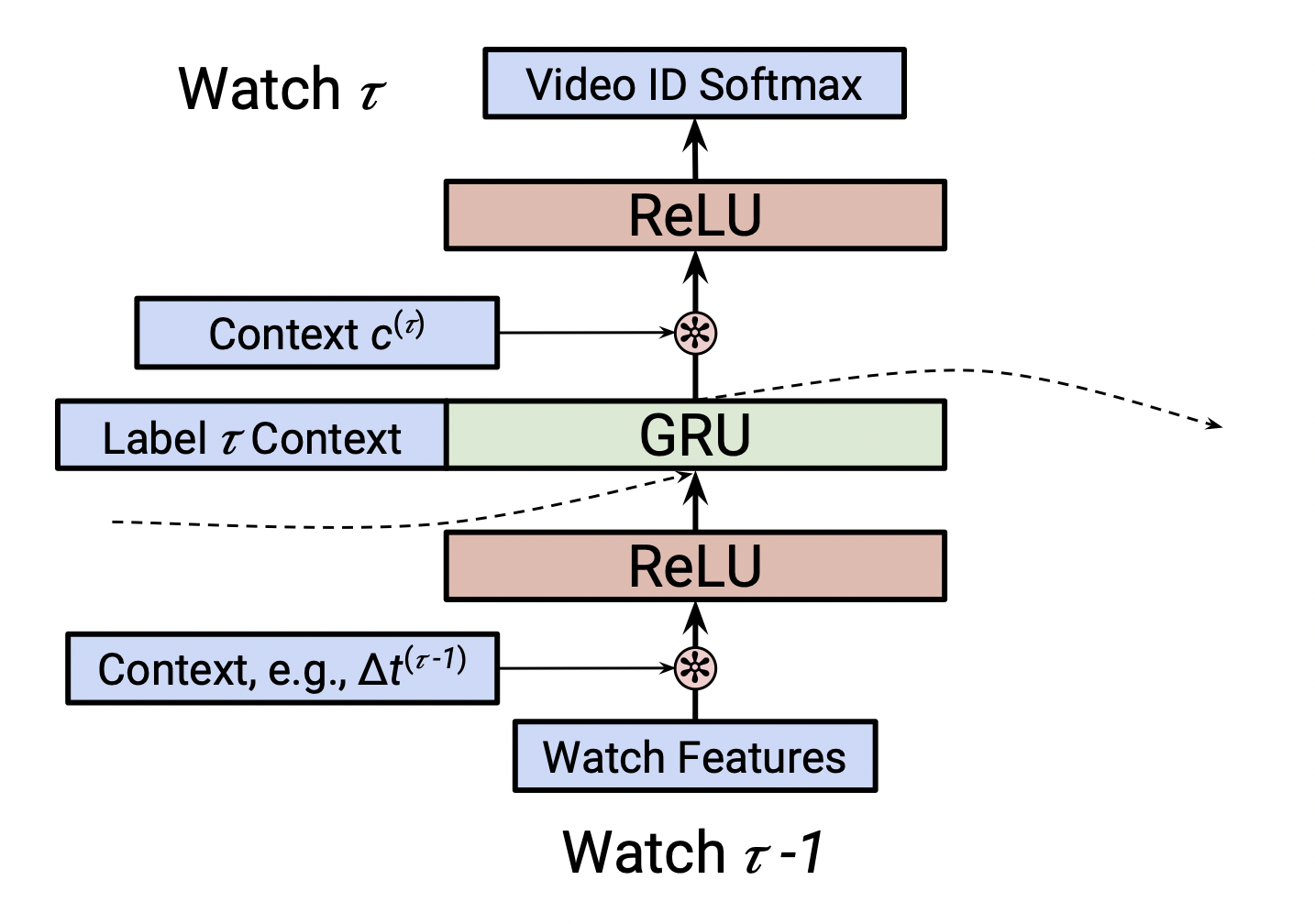
[출처] https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/46488.pdf, Latent Cross: Making Use of Context in Recurrent Recommender Systems
2018년에 Google Youtube Recommender 팀은 여러 개의 context를 효과적으로 융합하기 위한 방법으로서 latent cross(element wise product, Hadamard product) 방법을 제안했다.
기존 MLP에서 사용하던 단순한 concatenation을 사용하지 않고 element-wise product를 대신 사용하는 것이다.
이는 concatenation이 이론적으로는 임의의 관계를 근사할 수 있지만, 시뮬레이션 실험 결과 생각만큼 효율적이지 않다는 결과가 나왔기 때문이다.
Hidden representation인 $h$와 context vector인 $w$ 사이의 latent cross fusion을 적용하는 식은 다음과 같다.
$$ h' = (\mathbf{1} + w) \odot h $$
Time과 device라는 여러 context vector를 사용하면 다음과 같이 정리할 수 있다.
$$ h' = (\mathbf{1} + w_{time} + w_{device}) \odot h $$
이때 중요한 점은 hidden representation $h$와 context vector인 $w$의 dimension이 동일해야 하는 가정을 만족해야 한다.
이 아이디어는 context vector인 $w$가 0을 평균으로 갖는 Gaussian 분포로 초기화된다고 하면, hidden representation에 관해 $w$가 일종의 mask나 attention mechanism으로 해석할 수 있다는 것이다.
만약 context의 의미가 없으면 $w$를 zero-vector로 초기화하여 latent cross의 결과를 단순히 identity mapping 하는 것과 같이 원래의 $h$가 나올 수 있도록 한다.
위에서와 같이 input이 아니라 Hidden representation으로 나온 output에 latent cross를 적용하는 방식을 Post-fusion이라고 한다.
아래는 Transformer에 Post-fusion을 적용한 예시이다. (SIGIR 2021 Workshop on E-commerce Data Challenge)
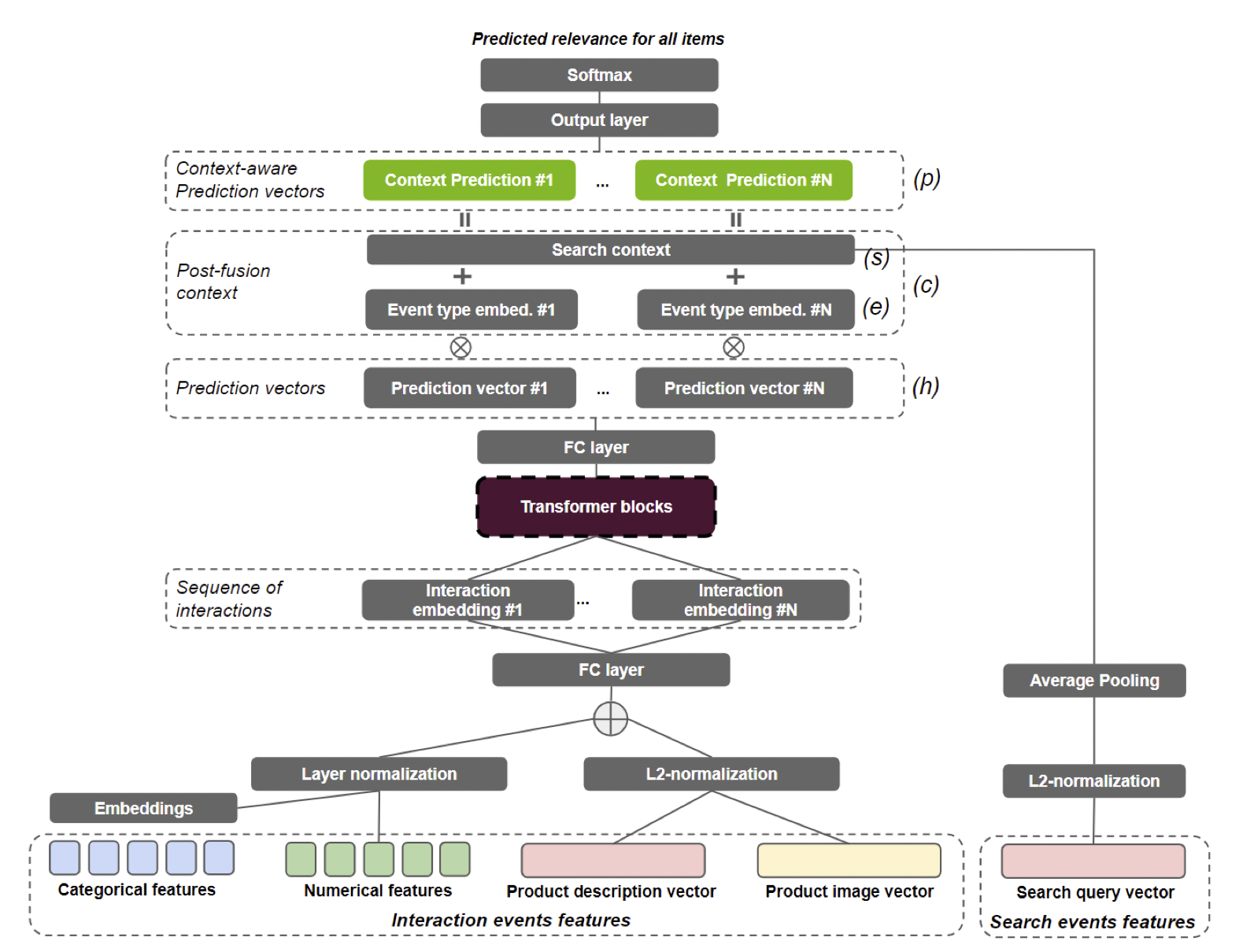
[출처] https://arxiv.org/pdf/2107.05124.pdf, Transformers with multi-modal features and post-fusion context for e-commerce session-based recommendation
고차원의 Side-information
Textual Content
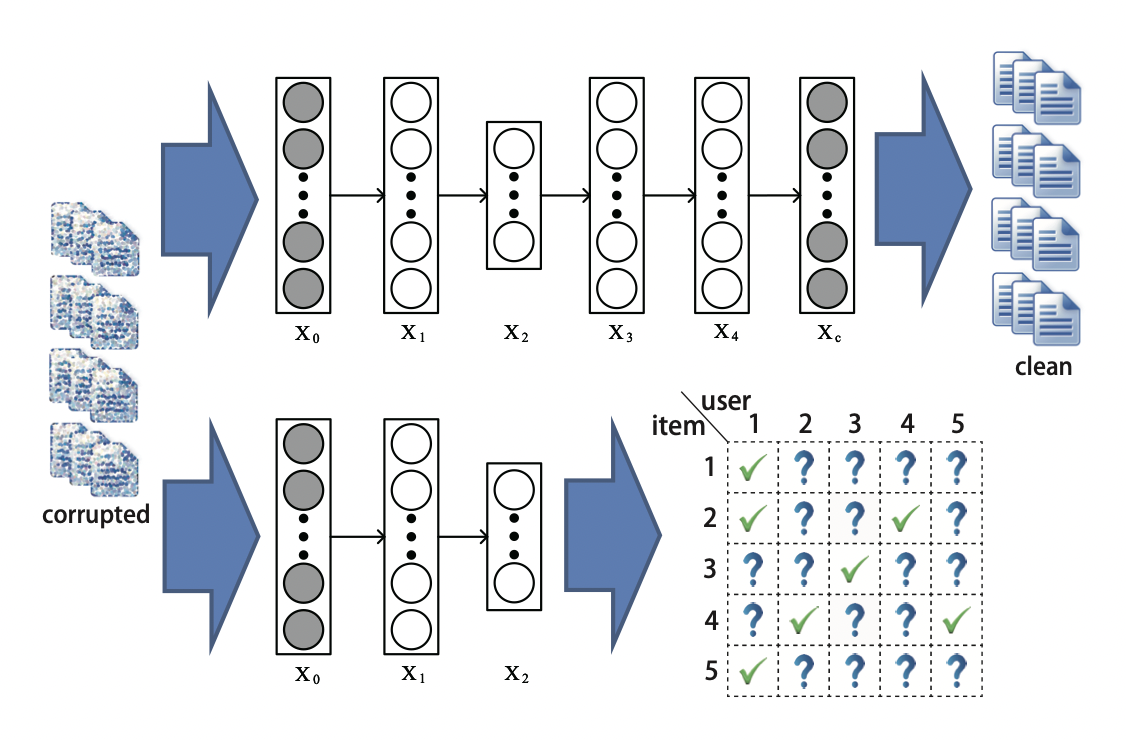
[출처] https://arxiv.org/pdf/1409.2944.pdf, Collaborative Deep Learning for Recommender Systems
Collaborative Deep Learning(CDL)은 문서와 단어로 이루어진 bag-of-words인 textual content를 활용한 Top-K Ranking 추천 모델이다.
이는 구체적으로 MF와 Stacked Denoising AutoEncoder(SDAE)를 결합한 형태이다.
SDAE는 Auto-encoder를 stack처럼 여러 개 쌓고, input에 noise corruption을 사용해서 denoising 효과를 노리는 모델이다.
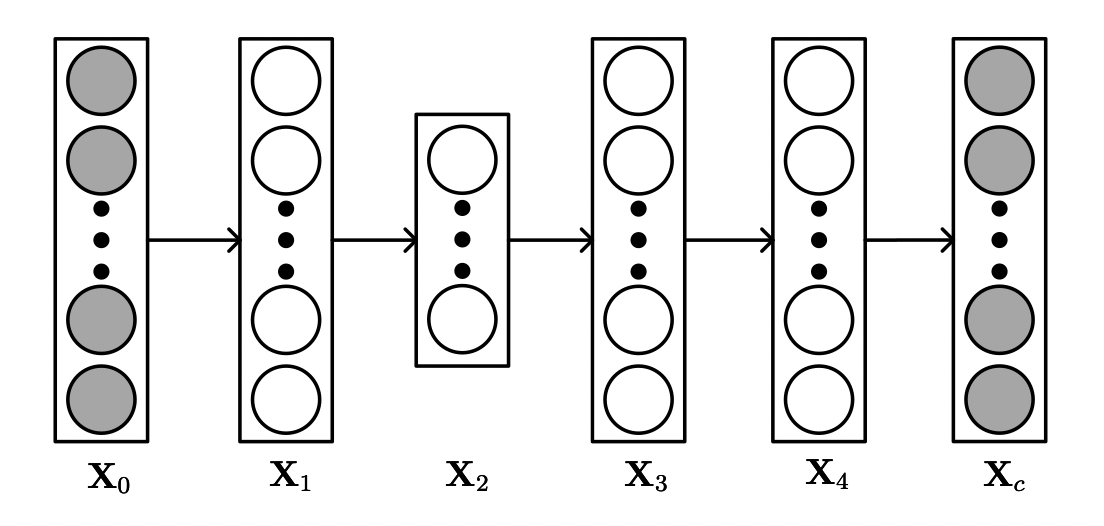
[출처] https://arxiv.org/pdf/1409.2944.pdf, Collaborative Deep Learning for Recommender Systems
Bag-of-words인 input $X_c$가 SDAE를 통과하여 reconstruction 되고, input과 output을 비교하면서 optimize 되는 특징이 있다.
주목해야 할 점은 SDAE의 information bottleneck(중간 부분)에서 얻은 값과 아이템의 속성을 의미하는 $\gamma_I$를 연결한다는 특징이다.
CDL과 유사하게 주로 아이템의 review data 등 textual content를 side-information으로 활용한 연구가 여러 개 존재한다.
평점 행렬인 $R$과 Bag-of-words 행렬인 $W$를 input으로 사용하고, 서로 공유하는 파라미터인 $\gamma_i$를 통해 서로 다른 두 가지 정보를 적절하게 융합한다는 아이디어에서 나온 것이다.
결과적으로 $\gamma_i$는 상호작용 데이터의 패턴 뿐만이 아니라 아이템 content의 패턴도 학습할 수 있다.
Visual Content
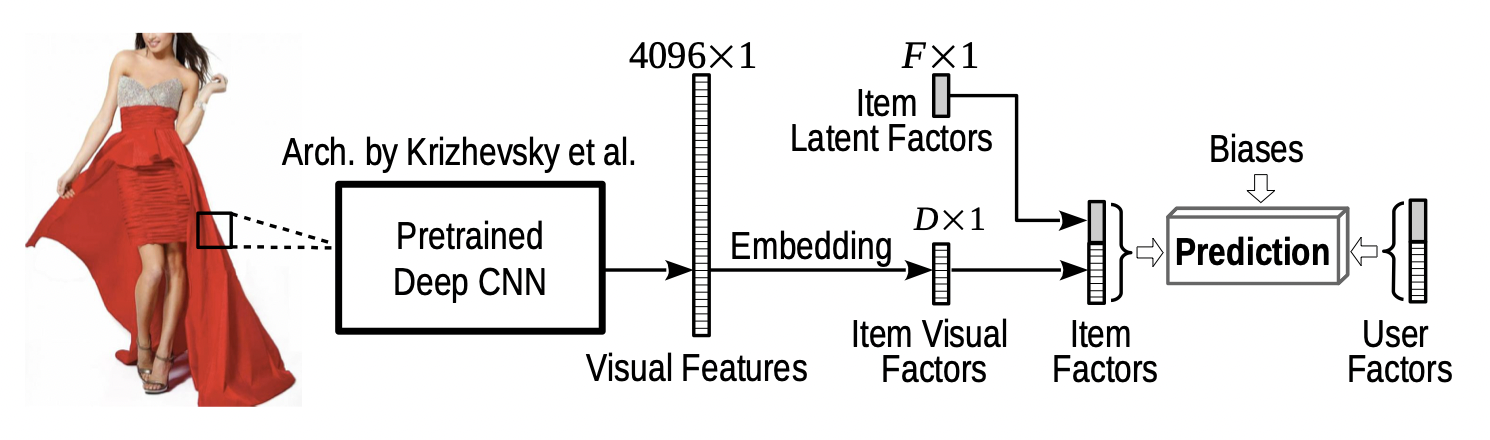
[출처] https://arxiv.org/pdf/1510.01784.pdf, VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback
Visual BPR(VBPR)은 아이템의 visual content를 활용한 모델이며, BPR-MF와 Visual signal을 결합한 형태로 볼 수 있다.
$$ \hat{x}_{uij} = \hat{x}_{u,i} - \hat{x}_{u, j} $$
Input으로는 implicit feedback을 사용하며, 아이템 콘텐츠로는 product의 이미지 데이터를 사용한다.
기존에 성능이 좋다고 알려진 pretrained CNN을 활용해서 아이템 별로 visual feature를 뽑은 이후에 아이템의 visual factor로 임베딩하고, 원래 사용하던 아이템의 latent factor와 결합하여 전체 아이템 vector를 생성할 수 있다.
$$ \hat{x}(u,i) = \alpha + \beta_u + \beta_i + \gamma_u^T \gamma_i + \theta_u^T (\mathbf{E}f_i) + \beta'^T f_i $$
$\gamma_u^T \gamma_i$는 기존에 사용했던 non-visual 데이터를 의미하는 사용자와 아이템의 preference를 뜻한다.
$f_i$는 이미지에서 관측한 visual feature를 의미하는데, $\theta_u^T (\mathbf{E}f_i)$는 visual feature와 사용자의 factor를 결합한 형태로 해석할 수 있다.
이때 visual feature와 사용자의 factor가 서로 차원이 다르므로 이를 맞춰주기 위해 $\mathbf{E}$라는 행렬을 사용한다.
Audio Content

[출처] https://proceedings.neurips.cc/paper/2013/file/b3ba8f1bee1238a2f37603d90b58898d-Paper.pdf, Deep content-based music recommendation
Deep Content-based Music Recommendation에서는 MF와 함께 Audio 시그널을 활용했다.
여기서는 audio signal을 처리하기 위해 CNN을 사용했는데, audio의 spectrogram 데이터를 바탕으로 CNN를 적용함으로써 최종 결과를 MF의 아이템 vector와 결합하는 구조를 가지고 있다.
Audio signal를 Deep Content-based Music Recommendation 모델에 통과한 결과를 t-SNE(t-distributed Stochastic Neighbor Embedding)로 2차원 상에 도식화해 보면 비슷한 장르의 음악끼리 묶이는 것을 볼 수 있다.
Social Networks와 Groups
아이템의 content 이외에도 사용자도 마찬가지로 social networks라는 그들만의 content를 지니고 있을 수 있는데, 이를 content로 활용함으로써 cold-start problem을 완화하고 추천 결과의 interpretability를 높일 수 있다.
자신의 의견이나 행동 등이 주변 사람들로부터 영향을 받는다는 social trust의 아이디어에 기반하고 있다.
사용자와 아이템 간의 상호작용 행렬인 $R$ 뿐만이 아니라 사용자와 사용자 간의 social link 정보를 가진 행렬 $A$를 추가적인 input으로 활용하게 된다.
행렬 $R$과 사용자 인접 행렬인 $A$를 사용자라는 공통의 요소이자 파라미터인 $\gamma_u$로 묶어서 목적함수를 설계할 수 있다.
Group-aware Recommendation에서는 사용자 그룹에서 집단적으로 추천이 이루어지는 시나리오에 적용할 수 있는 방법이다.
이때 사용자의 개개인 뿐만이 아니라 사용자가 속한 그룹과의 관련성을 함께 고려해야 한다.
그룹을 고려한 추천을 위해서는 추천되는 아이템이 사용자가 속한 그룹의 관심사와 관련성이 있어야 하며, 그룹 내의 사용자들 간의 선호도가 크게 다르지 않아야 한다.
그룹 $G$에 속한 사용자와 아이템 $i$ 간의 compatibility function을 구현하면 다음과 같다.
$$ rel(G, i) = \frac{1}{|G|} \sum_{u \in G} f(u, i) $$
또한 아이템 $i$에 관해 그룹 $G$에 속한 사용자들 간의 선호도가 크게 다르지 않아야 한다는 선호도의 일관성을 나타내는 함수는 다음과 같이 정의할 수 있다.
$$ dis(G, i) = \frac{2}{|G|(|G| - 1)} \sum_{(u,v) \in G, u \neq v} |f(u, i) - f(v, i)| $$
결과적으로 $rel(G, i)$ term과 $(1 - dis(G, i))$ term 각각에 가중치를 곱하여 합한 결과를 가지고 그룹 $G$에 어떠한 아이템을 추천하는 게 좋은지를 구하게 된다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech RecSys Track
'AI > 추천 시스템' 카테고리의 다른 글
| 신경망을 사용한 Matrix Factorization 모델과 NeuMF(Neural Collaborative Filtering) (1) | 2022.07.10 |
|---|---|
| 추천 시스템의 평가 방법과 실험에서의 데이터 분할 전략 (0) | 2022.04.26 |
| Deep Learning 기반의 Collaborative Filtering (0) | 2022.04.18 |
| 추천 시스템에서의 Implicit Feedback (0) | 2022.04.18 |
| Embarrassingly Shallow Autoencoders for Sparse Data: EASE 모델이 희소 데이터에 강한 이유 (4) | 2022.04.16 |
Contents
소중한 공감 감사합니다.