AI/추천 시스템
추천 시스템의 평가 방법과 실험에서의 데이터 분할 전략
- -
추천 시스템을 어떻게 평가할 수 있을까?
추천 시스템 평가 방법
사용자 스터디
사용자를 모집해서 시스템과 상호작용하게 한 후 피드백을 수집하는 것이다.
활발한 사용자 참여에 바탕을 두고 있기 때문에 오히려 실제 사용자와 동떨어진 active한 사용자만 반영하게 되어 bias로 작용할 수도 있다.
균일한 집단을 만들기 위해서는 주의 깊은 실험 설계가 요구되며, 많은 시간과 비용이 소모되어서 현실적으로 적용하기가 쉽지 않다.
Online 평가
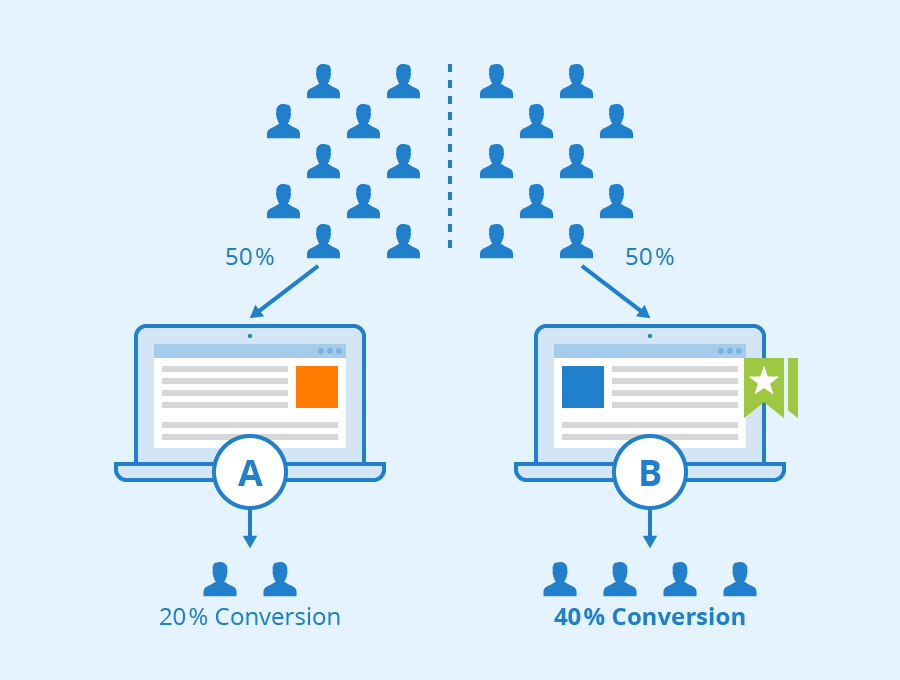
[출처] https://www.seobility.net/en/wiki/AB_Testing, Seobility
주로 A/B Testing이라고 불리는 형태로 이뤄지며, 시스템에 추천 알고리즘을 배포하여 사용자들의 실제 반응을 수집하여 비교한다.
사용자 스터디와 달리 샘플 수집으로부터 발생하는 bias에 덜 민감하다는 특징이 있다.
추천의 장기적인 상과를 직접적으로 평가하기 위한 가장 정확한 방식이나, 개발 및 배포에 이르기까지 시간이 오래 걸리며 통계적으로 유의미한 샘플을 모으기 위해서 많은 사용자 traffic이 요구된다는 단점이 있다.
예를 들어, A/B Testing을 위해 일정 기간동안 사용자를 50:50:의 비율로 나눈 뒤, 첫 번째 그룹에는 A의 결과를, 두 번째 그룹에는 B의 결과를 보여주고 각 그룹의 전환율(conversion rate)을 비교할 수 있다.
그러나 사용자 비율을 50:50으로 계속 유지하지 않고 A와 B의 성능을 관측하면서 multi-armed bandit에서처럼 exploration & exploitation을 통해 각 bucket의 비중을 조정하여 불필요하게 낭비되는 traffic을 줄일 수도 있다.
Offline 평가
이미 수집된 historical datasets를 활용하여 알고리즘의 성능을 평가하는 방법이다.
실제 사용자의 traffic이 없어도 테스트가 가능하다는 장점으로 인해 가장 널리 사용되는 평가 방법이다.
주로 accuracy 관련된 지표로 평가를 수행하지만, 학계와 산업계에서는 accuracy가 실제 사용자가 느끼는 추천의 효용을 잘 반영하는가에 대한 논란의 여지가 있다.
Accuracy 지표만으로는 serendipity(또 다른 즐거움)와 novelty(새로움) 등 추천 시스템의 중요한 특성을 포착할 수 없다는 단점이 있다.
또한 데이터 수집 이후, 시간의 흐름에 따라 사용자의 선호도나 아이템의 특성이 변화하는 것을 반영할 수 없다.
Historical dataset을 training set, validation set, testing set인 세 가지로 나누고, validation set은 training set으로 모델을 학습시킬 때 파라미터를 어떻게 튜닝하고 어떠한 모델을 선택할지를 결정하는 지표로서 사용한다.
최종적인 모델로부터 평가를 하는 과정에서는 testing set을 통해 학습시킨 모델의 evaluation을 수행한다.
추천 시스템 평가 기준
잘 알려진 RMSE, Precision, Recall 등 accuracy 외에도 diversity, serendipity, novelty, robustness 및 scalability 등 다양한 기준이 존재한다.
Accuracy
관측되지 않은 test set을 바탕으로 추천 결과를 얼만큼 정확히 맞출 수 있는지를 의미하는 지표이며, 추천 시스템에서 가장 널리 활용되는 기준이다.
평점 예측에서는 RMSE, MAE 등의 지표를, Top-K ranking 문제에서는 Precision@K, Recall@K, NDCG, MRR 등의 지표를 사용한다.
광고 분야에서는 때로 가격 등 외부 요소를 고려하여 profit을 최대화 하는 전략을 취하기도 한다.
그러나 accuracy가 사용자가 체감하는 추천 시스템의 실제 효용을 충분히 반영하는지는 불명확하다.
Coverage
전체 사용자와 아이템 중에서 추천 시스템이 놓치고 있는 부분이 없는지를 판단하는 평가 기준이다.
전체 사용자 및 아이템 중에서 한 번이라도 추천 결과과 생성된 사용자 또는 추천 결과에 포함된 아이템의 비율을 의미한다.
예를 들어, 총 100명의 사용자 중에서 추천 결과가 생성된 사용자가 90명이면, user-space coverage는 $\frac{90}{100} = 0.9$이다.
또한 총 50개의 아이템 카탈로그 중에서 추천 결과에 포함된 아이템의 개수가 30개이면, item-space coverage는 $\frac{30}{50} = 0.6$이다.
Coverage는 accuracy와 상충하는 trade-off 관계가 있다고 알려져 있다.
직관적으로 이해하면, 대개 사용자는 전체 아이템 카탈로그 대비 굉장히 적은 비율의 아이템을 사용하므로 이러한 상황에서 accuracy를 높이기 위해 coverage가 줄어들 수 밖에 없다.
Confidence
추천 결과를 제공하는 시스템의 신뢰성을 의미하는데, 예를 들면 평점 예측 문제에서 예측된 평균값이 같더라도 표준 편차가 적은 추천 시스템일수록 더 높은 confidence 값을 갖는다.
Trust
사용자가 추천 결과에 관해 가지고 있는 믿음을 의미하며, 동일한 추천 결과에 관하여 사용자는 왜 이러한 추천 결과가 나왔는지에 관한 explanation(설명)과 함께 제공하는 결과를 더 신뢰할 것이다.
사용자가 이미 알고 있거나 좋아하는 것으로 알려진 뻔한 아이템을 다시 추천하는 것은 새로움 측면에서는 유용하지 않을지 몰라도 trust를 증가시키는 효과가 있어서 trust와 novelty 사이에는 trade-off 관계가 있다.
Novelty
사용자가 잘 알지 못하거나 이전에 본 적 없는 새로운 추천을 사용자에게 제공할 가능성을 의미한다.
Novelty가 높은 추천은 종종 사용자가 이전에는 알지 못햇던 취향에 대한 새로운 발견을 제공한다.
그러나 사용자의 알려진 취향을 바탕으로 제공하면서 novelty가 낮은 뻔한 추천은 사용자의 추천 결과에 대한 trust를 향상시킬 수는 있으나, 전환율 향상의 측면에서는 유용한 전략이 아닐 수도 있다.
Serendipity
"Lucky discovery"를 통해 성공적인 추천 결과로부터 사용자가 느끼는 놀라움(unexpectedness)의 정도를 의미한다.
Serendipity는 novelty 뿐만이 아니라 relevance 특성에다가 unexpectedness을 함께 고려하는 특성이라고 볼 수 있다.
Diversity
추천 결과가 얼마나 다양한 아이템들로 이루어졌는지를 의미한다.
보통 높은 diversity는 높은 novelty, serendipity, coverage 특성을 갖게 된다.
한 마디로 요약하자면, "네가 뭘 좋아하는지 몰라서 다양하게 준비해 봤어."를 의미한다고 볼 수 있다.
Robustness & Stability
추천 시스템에 가해질 수 있는 적대적인 공격(adversarial attacks)에 대한 견고함과 안정성을 평가하는 기준이다.
예를 들어, 평점 예측 문제에서는 가짜로 평점을 매기는 행위 등 공격에 관해 얼마나 robust한지를 의미한다.
Scalability
추천 시스템이 대용량 데이터와 트래픽을 효과적이고 효율적으로 처리할 수 있는지를 평가한다.
Scalability를 평가할 수 있는 요소에는 training time, inference(prediction) time (= serving latency), memory requirements 등이 있다.
평가를 위한 실험 설계
데이터 분할
모델의 일반화 성능을 높이기 위해서 전체 데이터셋을 효과적으로 train, validation, test으로 나누는 작업을 의미한다.
이때 분할한 데이터셋은 disjoint하여 서로 겹치지 않도록 해야 한다.
Train set은 모델의 학습을 위해, validation set은 모델을 선택하고 파라미터를 튜닝하기 위해, test set은 선택된 모델에 대한 평가를 진행할 때 사용한다.
Train set과 validation set은 모델의 학습 과정에서 여러 번 재사용될 수 있지만, Test set은 평가 프로세스의 마지막에 한 번만 사용된다는 점에 유의한다.
데이터 분할 전략의 중요성
데이터 분할 전략은 모델의 학습(원인)과 성능(결과)에 모두 영향을 끼치는 confounding variable(교란 변수)이다.
이러한 모델의 학습과 성능에 모두 영향을 끼치는 데이터 분할을 적절히 통제하지 못하면, 모델의 학습과 성능 간의 왜곡된 연관관계가 도출될 수 있다.
추천 시스템에서는 데이터 및 평가 전략이 충분히 표준화되지 않았으므로 올바른 데이터 분할 저략을 사용하는 것이 추천 시스템에서는 매우 중요하다.
예를 들어, 추천 시스템은 미래에 사용자가 좋아할 만한 콘텐츠를 추천해야 하는데, 이를 위해서는 데이터의 time stamp를 고려하여 모델 학습 시에 미래에 대한 데이터가 포함되지 않도록 적절히 데이터 분할을 수행해야 한다.
즉, 미래에 대한 데이터 포함될 수 있는 future data leakage 문제를 고려하여 적절히 데이터를 분할해야 한다.
다양한 데이터 분할 전략

[출처] https://arxiv.org/pdf/2010.11060.pdf, A Critical Study on Data Leakage in Recommender System Offline Evaluation
Leave One Last
사용자 별로 시간 순서대로 interaction을 나열한 후, 마지막 interaction을 testing set으로, 마지막에서 두 번째 interaction을 validation 출처et으로, 나머지를 training set으로 사용하는 방법이다.
Leave One Basket이라고 마지막 하나만을 분할하는 게 아니라 basket 크기만큼 분할하는 방법도 있다.
학습을 위한 training data의 양을 최대화할 수 있다는 장점이 있지만, 사용자 당 하나의 interaction만 test에 사용하므로 전체 성능을 충분히 반영하지 않을 수 있다는 단점이 있다.
또한 global timeline을 고려하지 않으므로 future data leakage가 발생할 수 있다.
예를 들어, 아이템이 인기를 끌기 전 시점에서 모델이 해당 품목의 인기를 학습하는 현상이 생길 수 있다.
Temporal Split
Temporal User Split
사용자 별로 시간 순서에 따라 interaction을 나열한 뒤 일정 비율로 training set, validation set, testing set으로 분할한다.
Leave One Last와 다른 점은 validation set과 testing set을 뒤의 하나만 분할하는 것이 아니라 정해진 비율로 분할하는 것이다.
마찬가지로 사용자마다 timeline이 서로 다를 수 있음을 고려하지 않기 때문에 future data leakage가 발생할 수 있다.
Temporal Global Split
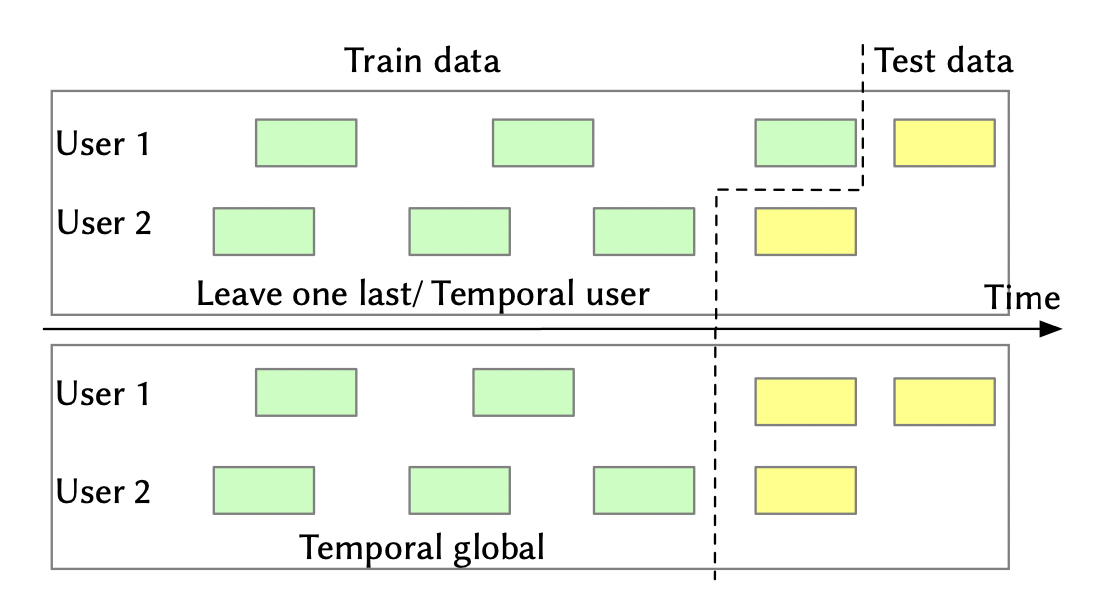
[출처] https://arxiv.org/pdf/2007.13237.pdf, Exploring Data Splitting Strategies for the Evaluation of Recommendation Models
사용자 별로 시간 순서에 따라 interaction을 나열한 뒤 fixed time point를 기준으로 validation set과 testing set을 분할하는 방법이다.
이때 fixed time point는 사용자마다 공유하는 time point이다.
Fixed time point를 기준으로 그 이전을 train_valid, 그 이후를 test set으로 분할한다.
그 다음에 train_valid의 일정 비율을 valid set으로 사용하고 나머지를 train set으로 사용한다.
Future data leakage가 발생하지 않아서 현실과 가장 유사한 평가 환경을 제공한다는 장점이 있다.
그러나 다른 전략에 비해 학습에 사용할 수 있는 interaction의 수가 적다는 단점이 있다.
Random Split
각 사용자 별로 interaction을 시간 순서에 관계 없이 random하게 training, validation, testing set으로 구분하는 방법이다.
랜덤하게 선택된 하나의 아이템을 testing set으로 할당하고, 나머지 부분에서 랜덤하게 선택된 다른 하나의 아이템을 validation set으로 할당한 뒤, 나머지를 train set으로 사용한다.
사용하기 쉬워서 과거에 많이 사용되었고, 많은 수의 training data를 얻을 수 있는 장점이 있다.
그러나 시간 순서를 고려하지 않고 데이터를 분할하기 때문에 어떻게 분할했는지 그 데이터를 공개하지 않는 이상 재현하기 어렵다는 단점이 있다.
User Split
Cold-start problem에 대응할 수 있는 strong generalization 성능을 평가하기 위해 사용자를 기준으로 서로 겹치지 않도록 training, validation, testing set으로 분할한다.
학습된 모델이 새로운 사용자에 대한 추천 결과를 생성할 수 있는 user-free model에만 평가가 가능하다는 단점이 있으며, future data leakage가 존재한다.
절대적으로 좋은 하나의 데이터 분할 전략은 없으므로 상황에 맞는 적절한 전략을 취해야 하지만, 최근에는 보다 현실적인 평가를 위해서 Temporal Global Split을 권장하는 추세이다.
Accuracy 기반 Offline 평가의 한계
Feedback Loop
추천 시스템에서는 추천 시스템이 사용자에게 어떠한 아이템을 추천하고, 이를 바탕으로 사용자가 아이템에 관한 행위를 한 데이터가 남으며, 쌓인 데이터를 가지고 다시 추천 시스템을 학습시키기 떄문에 feedback loop 현상이 발생할 수 있다.
이러한 feedback loop로 인해 다양한 bias가 증폭될 수 있으므로 accuracy 기반의 offline 평가는 부정확한 상대평가로 이어질 수 있다.
즉, offline 결과와 online 결과의 불일치가 발생하고 강화될 수 있다.
Data Bias와 Selection Bias
Data Bias
Training 데이터의 분포와 testing 데이터의 분포가 다른 현상을 의미한다.
Selection Bias
Data bias의 일종으로, 사용자들이 일부의 아이템만 자발적으로 선별하여 평가하기 때문에 발생하는 현상이다.
사용자가 자발적으로 아이템을 선택하여 평가했을 때의 나오는 결과와, 랜덤으로 아이템을 선별했을 때 나오는 사용자의 평가가 다를 수 있음을 의미한다.
Bias를 줄일 수 있는 방안
- Implicit feedback을 사용하여 selection bias를 어느 정도 완화할 수 있다.
- Temporal global split을 data splitting 전략으로 사용하는 것이다.
- Offline 평가와 Online 평가 전략의 장점을 취하여 보완하는 전략을 사용하는 것이다. Counterfactual evaluation, offline A/B testing이 여기에 해당된다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech RecSys Track
'AI > 추천 시스템' 카테고리의 다른 글
| GNN(Graph Neural Network)의 정의와 특징 그리고 추천시스템에서의 GNN 계열 모델 (1) | 2023.01.02 |
|---|---|
| 신경망을 사용한 Matrix Factorization 모델과 NeuMF(Neural Collaborative Filtering) (1) | 2022.07.10 |
| Side Information과 이를 사용하는 추천 시스템 (1) | 2022.04.20 |
| Deep Learning 기반의 Collaborative Filtering (0) | 2022.04.18 |
| 추천 시스템에서의 Implicit Feedback (0) | 2022.04.18 |
Contents
소중한 공감 감사합니다.