Data Science/데이터 시각화
Matplotlib의 Pyplot 모듈로 Scatter Plot 그리기
- -
2022년 2월 3일(목)부터 4일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
Scatter Plot
Scatter Plot
점을 사용하여 두 feature간의 관계를 알기 위해 사용하는 그래프이다.
산점도 등의 이름으로도 사용된다.
직교 좌표계에서 $x$축 또는 $y$축에 feature 값을 매핑해서 사용한다.
.scatter() 메소드를 사용한다.
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111, aspect=1)
np.random.seed(970725)
x = np.random.rand(20)
y = np.random.rand(20)
ax.scatter(x, y)
ax.set_xlim(0, 1.05)
ax.set_ylim(0, 1.05)
plt.show()
Scatter Plot의 요소
다음과 같은 요소를 통해 점에 다양한 varation을 줄 수 있다.
- 색 (
color) - 모양 (
marker)- 예)
marker = '^'로 지정하면 삼각형으로 모양을 바꿀 수 있다.
- 예)
- 크기 (
size)
fig = plt.figure(figsize=(7, 7))
# 관계를 보기에 적합하도록 서브플롯의 가로축과 세로축의 스케일을 1:1로 맞추기 위해 aspect의 파라미터를 1로 설정하여 넘긴다.
ax = fig.add_subplot(111, aspect=1)
np.random.seed(970725)
x = np.random.rand(20)
y = np.random.rand(20)
s = np.arange(20) * 20
ax.scatter(x, y,
s= s,
c='white', # 색 지정
marker='o', # 마커 모양 지정
linewidth=1,
edgecolor='black')
plt.show()

2차원 데이터를 표현해서 $N$차원 데이터로 확장할 수 있다.
Scatter Plot의 목적
상관 관계(양의 상관관계, 음의 상관관계)가 존재하는지 확인하기 위해 사용한다.
또는 다음과 같은 특성을 파악하기 위해 사용하기도 한다.
- 군집 (Cluster)
- 값 사이의 차이 (Gap in Variables)
- 이상치 (Outliers)
Scatter Plot 사용 시 유의점
Overplotting
점끼리의 중복이나 점의 테두리로 인해 점이 많아질수록 점의 분포를 파악하기 힘들다.
이를 해결하는 방법은 다음과 같다.
- 투명도 조정
- 색이 진하면 점들이 많이 밀집되어 있음을 의미한다.
- 지터링 (jittering)
- 점의 위치를 약간씩 변경한다.
- 2차원 히스토그램
- 히트맵을 사용하여 시각화를 깔끔하게 한다.
- Contour Plot
- 등고선처럼 표현한다.
- 등고선이 좁을수록 데이터가 조밀함을 의미한다.
점의 요소와 인지
- 색
- 연속은 gradient, 이산은 개별 색상으로 표시한다.
- 마커
- 모양은 거의 구별하기 힘들므로 마커만 사용하는 건 좋지 않다.
- 모양에 따라 크기가 고르지 않아서 Principle of Proportional Ink에 위배된다.
- 크기
- 흔히 버블 차트(Bubble Chart)라고 부른다.
- 구별하기는 쉽지만 오용하기 쉽고, 크기 비교가 어렵다.
- 관계보다는 각 점간 비율에 초점을 둔다면 괜찮다.
인과관계와 상관관계
인과관계(casual relation)와 상관관계(correlation)은 엄연히 다름으로 분석과정에서 반드시 고민해 보는 게 필요하다.
인과관계는 항상 사전 정보와 함께 가정으로 제시해야 한다.
상관관계는 heatmap으로도 표현할 수 있다.
추세선
추세선을 사용하면 scatter의 패턴을 유추할 수 있다.
단, 추세선이 2개 이상이면 가독성이 떨어질 수 있다는 점을 유의한다.
Scatter Plot과 Grid는 서로 상성이 좋지 않으므로 Grid는 지양하고, 사용한다면 색은 무채색으로 최소한으로 사용한다.
범주형이 포함된 관계에서는 heatmap 또는 bubble chart를 사용하는 것이 권장된다.
Scatter Plot 사용 예시
마커 변형하기
조건에 따라 점(marker)의 색을 구분지을 수 있다.
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
slc_mean = iris['SepalLengthCm'].mean()
swc_mean = iris['SepalWidthCm'].mean()
ax.scatter(x=iris['SepalLengthCm'],
y=iris['SepalWidthCm'],
# 조건에 따라 점의 색을 구분지을 수 있다.
c=['royalblue' if yy <= swc_mean else 'gray' for yy in iris['SepalWidthCm']]
)
plt.show()
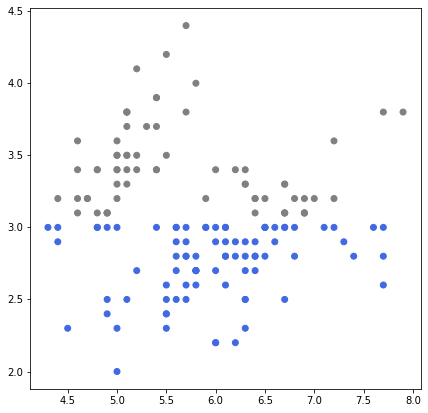
굳이 색을 직접 지정할 필요 없이 loop으로 여러 번 scatter plot을 그려줘도 된다.
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
for species in iris['Species'].unique():
iris_sub = iris[iris['Species']==species]
ax.scatter(x=iris_sub['SepalLengthCm'],
y=iris_sub['SepalWidthCm'],
label=species)
ax.legend()
plt.show()
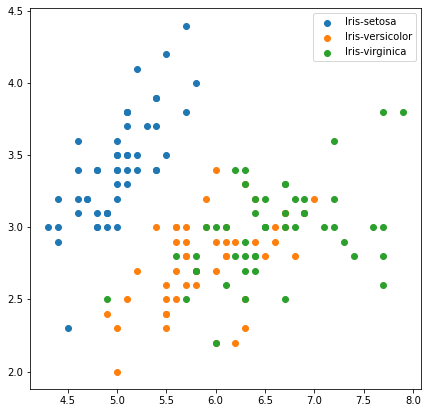
군집 구분을 위한 선 사용하기
fig = plt.figure(figsize=(7, 7))
ax = fig.add_subplot(111)
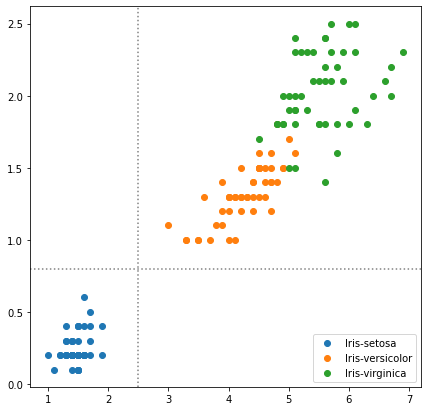
for species in iris['Species'].unique():
iris_sub = iris[iris['Species']==species]
ax.scatter(x=iris_sub['PetalLengthCm'],
y=iris_sub['PetalWidthCm'],
label=species)
# 선은 직접 지정해야 한다.
ax.axvline(2.5, color='gray', linestyle=':')
ax.axhline(0.8, color='gray', linestyle=':')
ax.legend()
plt.show()
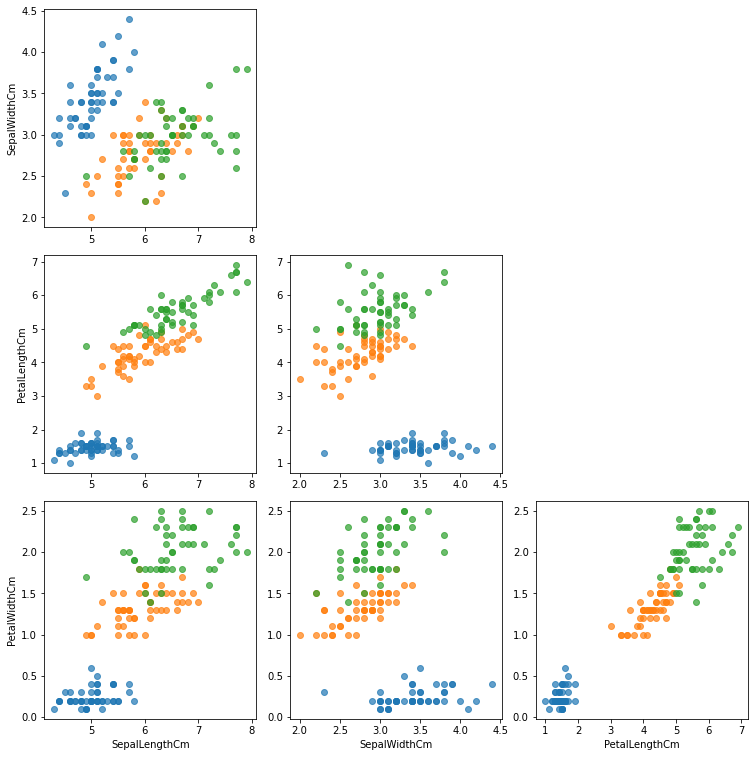
각 Feature 간의 관계를 모두 Scatter Plot으로 그리기
fig, axes = plt.subplots(4, 4, figsize=(14, 14))
feat = ['SepalLengthCm', 'SepalWidthCm', 'PetalLengthCm', 'PetalWidthCm']
for i, f1 in enumerate(feat):
for j, f2 in enumerate(feat):
if i <= j :
# 해당되지 않은 서브 플롯은 그리지 않기
axes[i][j].set_visible(False)
continue
for species in iris['Species'].unique():
iris_sub = iris[iris['Species']==species]
axes[i][j].scatter(x=iris_sub[f2],
y=iris_sub[f1],
label=species,
alpha=0.7)
if i == 3: axes[i][j].set_xlabel(f2)
if j == 0: axes[i][j].set_ylabel(f1)
plt.tight_layout()
plt.show()
'Data Science > 데이터 시각화' 카테고리의 다른 글
| Matplotlib 모듈로 그린 Chart에서 Color 사용하기 (0) | 2022.02.15 |
|---|---|
| Matplotlib 모듈로 그린 Chart에서 Text 사용하기 (0) | 2022.02.15 |
| Matplotlib의 Pyplot 모듈로 Line Plot 그리기 (0) | 2022.02.15 |
| Matplotlib의 Pyplot 모듈로 Bar Plot 그리기 (0) | 2022.02.15 |
| Python과 Matplotlib (0) | 2022.02.15 |
Contents
소중한 공감 감사합니다.