AI/추천 시스템
Word2Vec을 응용한 Item2Vec
- -
2022년 3월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해나갈 예정입니다. 강의 자료의 저작권은 네이버 커넥트재단 부스트캠프 AI Tech에 있습니다.
Word2Vec
Word2Vec에 관한 개념은 이 포스트에 적은 내용을 바탕으로 한다.
https://glanceyes.tistory.com/entry/Word-Embedding과-Word2Vec
Word Embedding을 위한 Word2Vec과 GloVe
Word Embedding 자연어가 단어라는 정보의 기본 단위로 이루어지는 sequence라고 볼 때, 각각의 단어를 특정한 차원으로 이루어진 공간 상의 한 점 또는 그 점의 좌표를 나타내는 벡터로 변환해주는 기
glanceyes.tistory.com
임베딩(Embedding)
주어진 데이터를 낮은 차원의 벡터(vector)로 만들어서 표현하는 방법이다.
Sparse Representation
아이템의 전체 가짓수와 차원의 수가 동일하다.
이진값(0 또는1)으로 이루어진 벡터로 표현하는 것을 one-hot encoding 또는 multi-hot encoding이라고 한다.
아이템 개수가 많아질수록 벡터의 차원이 한없이 커지고 공간이 낭비된다.
Dense Representation
아이템의 전체 가짓수보다 훨씬 작은 차원으로 표현한다.
이진값이 아닌 실수값으로 이루어진 벡터로 표현한다.
워드 임베딩(Word Embedding)
NLP에서 텍스트 분석을 위해 단어(word)를 벡터로 표현하는 방법이다.
One-hot encoding으로 표현된 sparse representation을 dense representation으로 바꾸는 것을 의미한다.
비슷한 의미를 가진 단어일수록 embedding vector가 서로 가까운 위치에 분포해서 단어 간 의미적인 유사도를 구할 수 있다.
임베딩으로 표현하기 위해서는 학습 모델이 필요하다.
Matrix Factorization도 one-hot encoding된 유저, 아이템의 데이터를 latent hot vector로 바꾸는 임베딩으로 볼 수도 있다.
이때 데이터로부터 학습한 행렬이 유저, 아이템의 임베딩이라고 볼 수 있다.
워드 임베딩의 특징
Input과 Output 사이에 하나의 레이어만 있는 간단한 뉴럴 네트워크 language 모델이다.
대량의 문서 데이터셋을 vector 공간에 투영하면 압축된 형태의 많은 의미를 갖는 dense vector로 표현 가능하다.
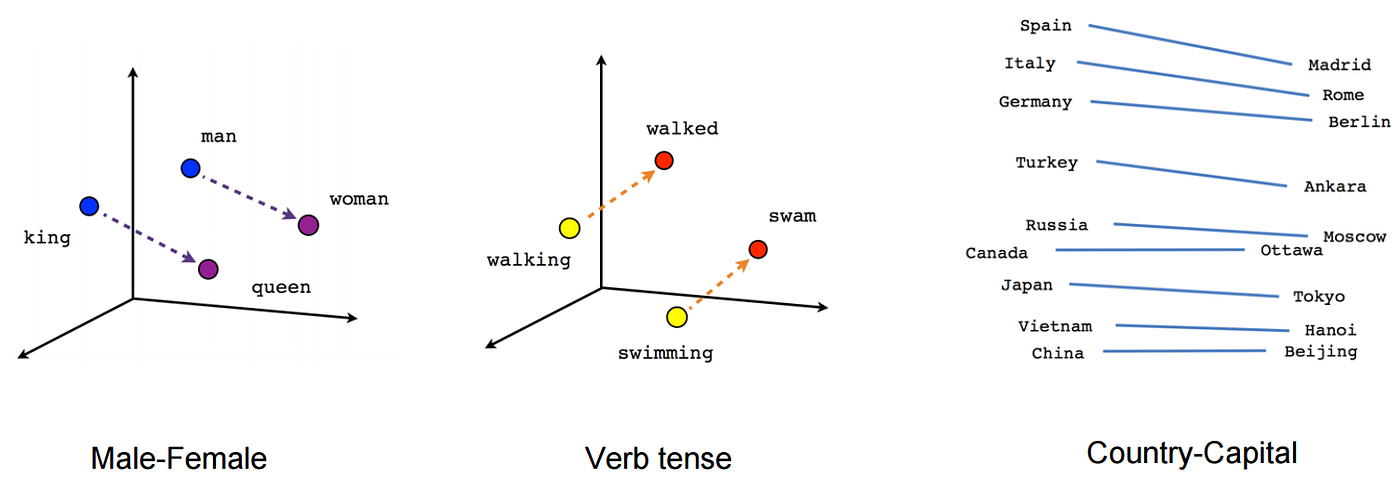
[출처] https://towardsdatascience.com/mapping-word-embeddings-with-word2vec-99a799dc9695
Word2Vec 학습 방법
Continuous Bag of Words (CBOW)
주변에 있는 단어를 가지고 중간에 있는 단어를 예측하는 방법이다.
물리적으로 가까이 위치한 단어는 서로 연관성이 있는 것이다.
단어를 예측하기 위해 앞뒤로 몇 개의 단어를 사용할 것인지 정해야 한다.
Window의 크기가 $n$이라면 실제 예측하기 위해 참고하는 단어는 2$n$개이다.
가운데를 기준으로 앞뒤 각각 $n$개의 단어가 Input($x$)이 되고, 가운데 단어가 Output($y$)이 된다.
단어의 총 개수가 $V$이고, 임베딩 벡터의 사이즈가 $M$이면 학습 파라미터는 input layer를 projection layer로 바꿔주는 가중치인 $W_{V \times M}$, projection layer를 output layer로 바꿔주는 가중치인 $W'_{M \times V}$가 있다.
여러 입력 벡터를 가지고 projection layer의 임베딩 벡터로 변환시킬 때 벡터의 평균을 이용할 수 있다.

[출처] https://commons.wikimedia.org/wiki/File:Cbow.png
위의 이미지에서는 임베딩 벡터의 차원 크기가 $M$이 아닌 $N$으로 고려하여 모식화한 그림이다.
예측값 $\hat{y}$와 one-hot encoding된 $y$의 차이를 최소화하도록 모델을 학습시키는 것이 목표이다.
Skip-Gram
CBOW의 입력층과 출력층이 반대로 구성된 모델이다.
가운데 단어가 input, window에 포함된 주변 단어가 output이 된다.

[출처] https://commons.wikimedia.org/wiki/File:Skip-gram.png
그래서 CBOW에서 input layer에서 projection layer로 갈 때처럼 벡터의 평균을 구하는 과정이 없다.
일반적으로 CBOW보다 Skip-Gram의 embedding의 표현력이 더 좋다고 알려져 있다.
Skip-Gram with Negative Sampling(SGNS)
가운데 단어와 주변에 있는 각각의 단어를 모두 입력 값으로 바꾸고, window에 포함되어 있으면 1, 그렇지 않으면 0이라는 레이블을 지니는 binary classification 문제로 바꾼 것이다.
Skip-Gram에서 사용한 데이터를 그대로 바꿔주면 레이블이 모두 1이 되는데, 이는 Skip-Gram에서 주변에 있지 않은(window에 포함되지 않는) 데이터는 사용하지 않았기 때문이다.
그래서 가운데 단어를 중심으로 주변에 있지 않은(window에 포함되지 않는) 단어도 강제로 sampling 해야 하는데, 이를 Negative Sampling이라고 한다.
Negative 샘플링을 몇 개로 해야할지는 하이퍼파라미터로 정할 수 있으며, positive sample 하나 당 몇 개를 샘플링할지를 정한다.
학습 데이터가 적은 경우 5~20, 충분히 큰 경우 2~5 정도가 적당하다고 알려져 있다.
중심 단어와 주변 단어가 임베딩 파라미터를 따로 가지며, 각각 서로 다른 lookup table을 통해 임베딩된다.
- 중심 단어 임베딩 벡터를 기준으로 주변 단어 임베딩 벡터들과의 내적의 sigmoid를 예측값으로 하여 0과 1을 분류한다.
- 역전파를 통해 중신 단어와 주변단어의 임베딩이 업데이트되면서 모델이 수렴한다.
- 최종 생성된 워드 임베딩 벡터가 중심 단어와 주변 단어 2개이므로 선택적으로 하나만 사용하거나 평균을 사용한다. 중심 단어와 주변 단어 임베딩 벡터 각각에는 모든 단어가 포함되어 있을 것이므로 하나만 사용하거나 평균을 구해서 사용해도 된다.
Item2Vec
Word2Vec의 SGNS에서 영감을 받아 Item-based CF에 Word2Vec을 적용하는 것이다.
MF에서도 유저와 아이템을 임베딩하는 것처럼, 단어가 아닌 추천 아이템을 Word2Vec을 사용하여 임베딩한다.
유저가 소비한 아이템 리스트를 문장으로, 아이템을 단어로 가정하여 Word2Vec를 사용한다.
Item2Vec은 유저와 아이템 관계를 사용하지 않으므로 유저에 대한 식별 없이 세션 단위로도 데이터 생성이 가능하다.
SGNS 기반의 Word2Vec을 사용하여 아이템을 벡터화하는 것이 최종 목표이다.
SVD 기반의 MF를 사용한 IBCF보다 Word2Vec이 더 높은 성능과 양질의 추천 결과를 제공한다고 알려져 있다.
유저 또는 세션별로 소비한 아이템 집합을 생성한다.
Item2Vec은 시퀀스를 집합으로 바꾸면서 공간적, 시간적인 정보가 사라지지만, 대신에 집합 안에 존재하는 아이템은 서로 유사하다고 가정한다.
공간적 정보를 무시하므로 동일한 아이템 집합 내 아이템 쌍들은 모두 SGNS의 Positive Sample이 된다.
기존의 Skip-Gram이 주어진 단어 앞뒤로 $n$개의 단어를 사용한 것과는 달리 모든 단어 쌍을 사용한다.
'AI > 추천 시스템' 카테고리의 다른 글
| 딥 러닝을 사용한 추천 시스템과 대표적인 예시인 유튜브 영상 추천 (0) | 2022.03.13 |
|---|---|
| ANN(Approximate Nearest Neighbor)과 ANNOY (0) | 2022.03.13 |
| Bayesian Personalized Ranking(BPR) (0) | 2022.03.13 |
| 모델 기반 CF와 SVD를 응용한 MF(Matrix Factorization) (3) | 2022.03.13 |
| Collaborative Filtering(협업 필터링)기반 추천 모델 (0) | 2022.03.11 |
Contents
소중한 공감 감사합니다.