AI/추천 시스템
딥 러닝을 사용한 추천 시스템과 대표적인 예시인 유튜브 영상 추천
- -
2022년 3월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
딥 러닝을 사용한 추천 시스템
추천 시스템에서 딥러닝을 활용하는 이유
Nonlinear Transformation
DNN은 data의 non-linearity를 효과적으로 나타낼 수 있다.
복잡한 유저-아이템 상호작용 패턴을 효과적으로 모델링하여 user의 선호도를 예측할 수 있다.
Representation Learning
DNN은 raw data로부터 feature representation을 학습해 사람이 직접 feature design을 하지 않아도 된다.
텍스트, 이미지, 오디오 등 다양한 종류의 정보를 추천 시스템에 활용할 수 있다.
Sequence Modeling
DNN은 자연어 처리, 음성 신호 처리 등 sequential modeling task에서 성공적으로 적용된다.
추천 시스템에서 next-item 예측, 같은 세션에서 진행하는session-based 추천에 사용될 수 있다.
Flexibility
Tensorflow, PyTorch 등 다양한 DL 프레임워크가 오픈되어 있다.
추천시스템 모델링 flexibility가 높으며, 더 효율적으로 서빙할 수 있다.
MLP를 사용한 추천 시스템
다층 퍼셉트론(MLP)
퍼셉트론으로 이루어진 layer 여러 개를 순차적으로 이어 놓은 feed-forward neural network이다.
선형 분류만으로 풀기 어려웠던 문제를 비선형적으로 풀 수 있다.
Neural Collaborative Filtering
MF의 한계를 지적하여 신경망 기반의 구조를 사용해 더욱 일반화된 모델을 제시할 수 있다.
MF의 한계
M에서는 user와 item 각각의 embedding의 선형 조합을 구하므로 user와 item 사이의 복잡한 관계를 표현하는 것에 한계를 가진다.
Neural CF 모델 구조(MLP 부분)
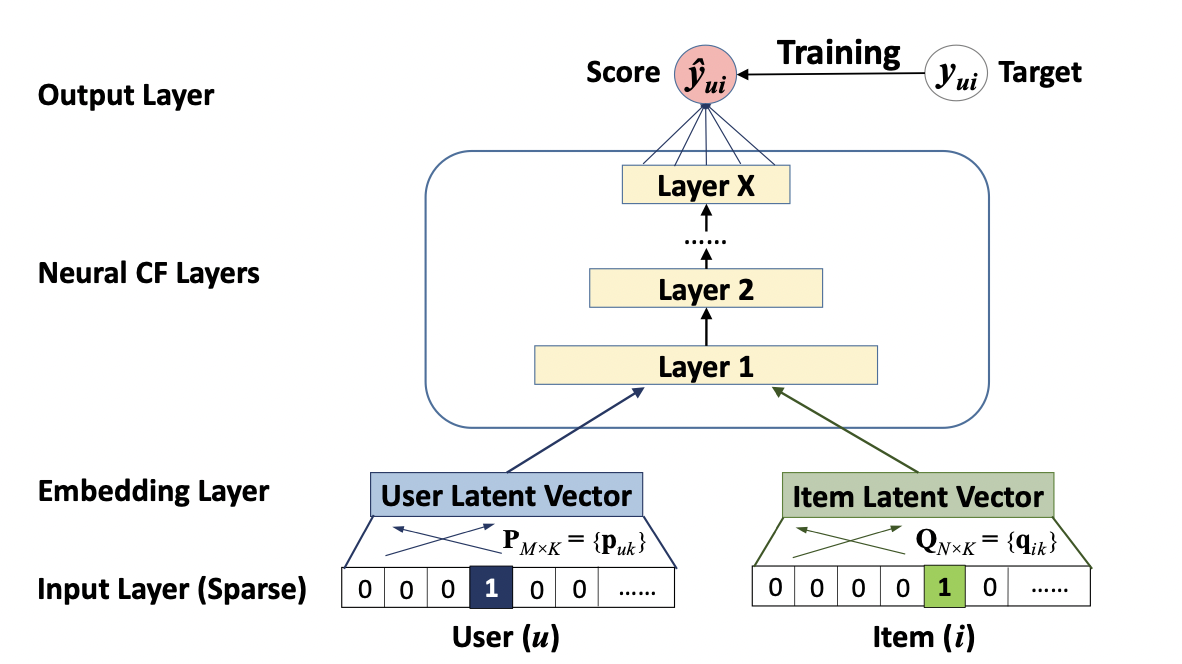
[출처] https://arxiv.org/pdf/1708.05031.pdf, Neural Collaborative Filtering
Input Layer
one-hot encoding 된 유저 또는 아이템 벡터: $v_u$
Embedding Layer
유저 또는 아이템의 latent vector: $P^T v_u$ 또는 $Q^T v_i$
Neural CF Layers
$\phi_X(\cdots \phi_2(\phi_1(P^T v_u, Q^T v_i)) \cdots)$
Output Layer
Output layer는 Logistic 또는 Probit 함수를 사용한다.
유저와 아이템 사이의 관련도
$\hat{y}_{ui} = \phi_{out}(\phi_X(\cdots \phi_2(\phi_1(P^T v_u, Q^T v_i)) \cdots)),\; \hat{y}_{ui} \in [0, 1]$
최종 모델 (Neural Matrix Factorization)
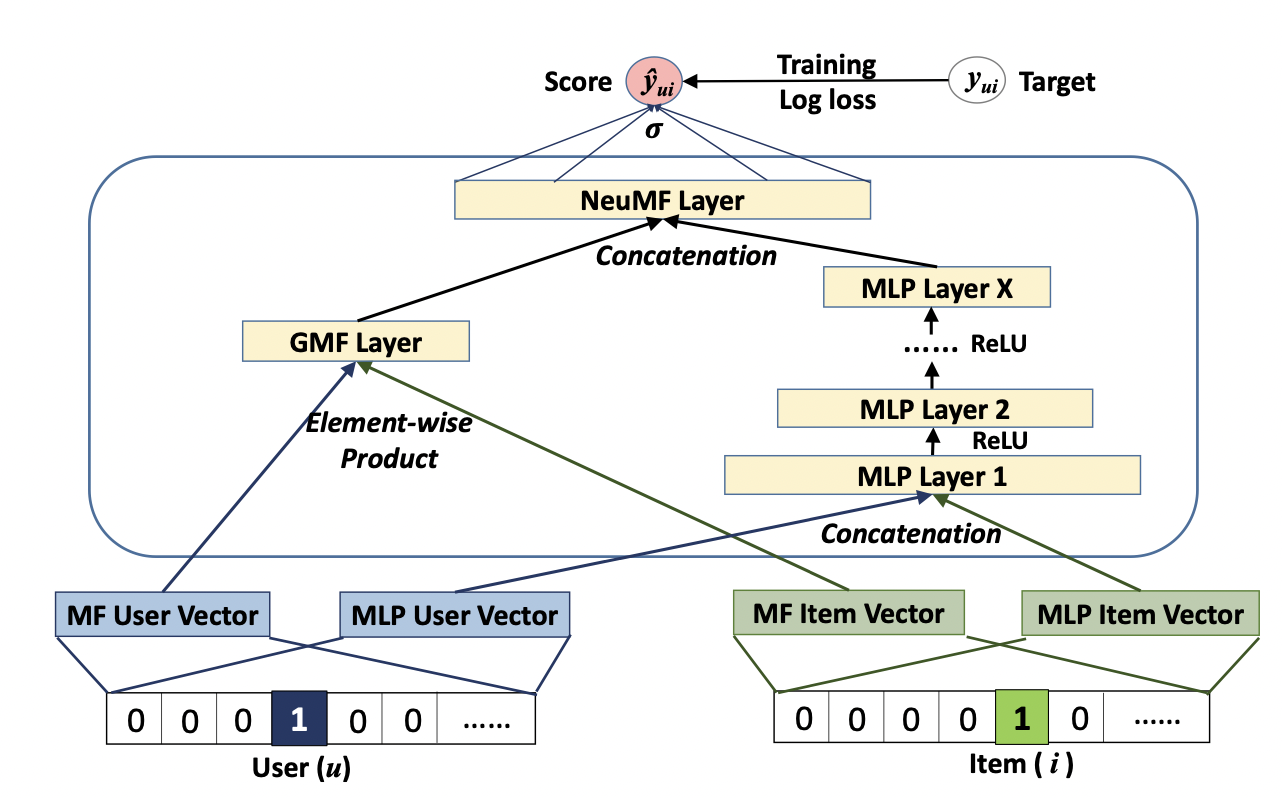
[출처] https://arxiv.org/pdf/1708.05031.pdf, Neural Collaborative Filtering
GMF(Generalized Matrix Factorization) Layer와 MLP의 output을 concatenate한 후 최종적으로 NeuMFLayer를 통과하여 예측한다.
즉, GMF와 MLP를 앙상블하여 사용하는 것이다.
GMF와 MLP는 서로 다른 embedding layer를 사용한다.
유튜브 추천 문제에서 쓰이는 Deep Neural Networks
유튜브 추천 문제 특징
- Scale
- 매우 많은 유저와 아이템
- 제한된 컴퓨팅 파워
- 효율적인 서빙에 특화된 추천 알고리즘 필요
- Freshness
- 잘 학습된 콘텐츠와 새로 업로드 된 콘텐츠를 실시간으로 적절히 조합해야 한다.
- Noise
- 높은 sparsity, 다양한 외부 요인으로 유저의 행동을 예측하기 어렵다.
- Implicit Feedback 활용이 요구된다.
- 낮은 품질의 메타데이터를 잘 활용해야 한다.
2단계 추천 시스템
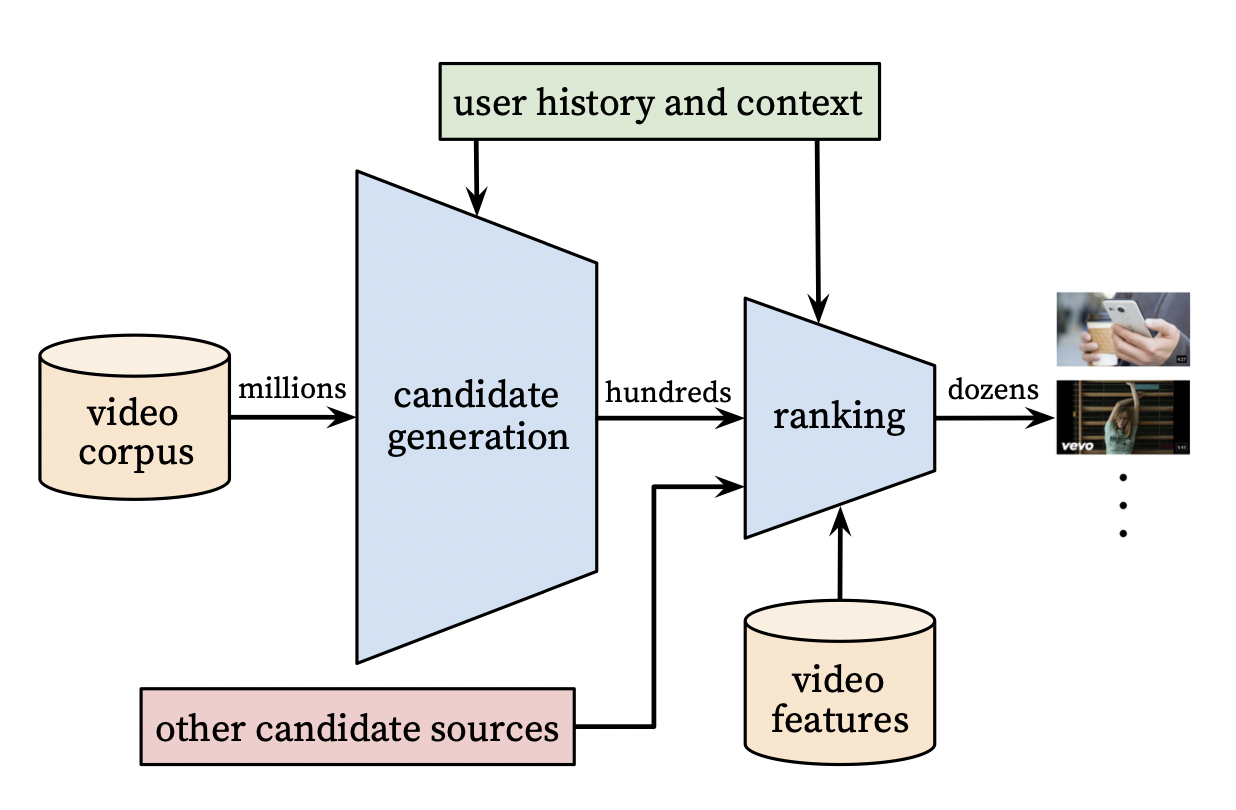
[출처] https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/45530.pdf, Deep Neural Networks for YouTube Recommendations
유튜브의 추천 시스템을 요약하면 크게 Candidate Generation과 Ranking 2단계로 구성되어 있다고 할 수 있다.
Candidate Generation
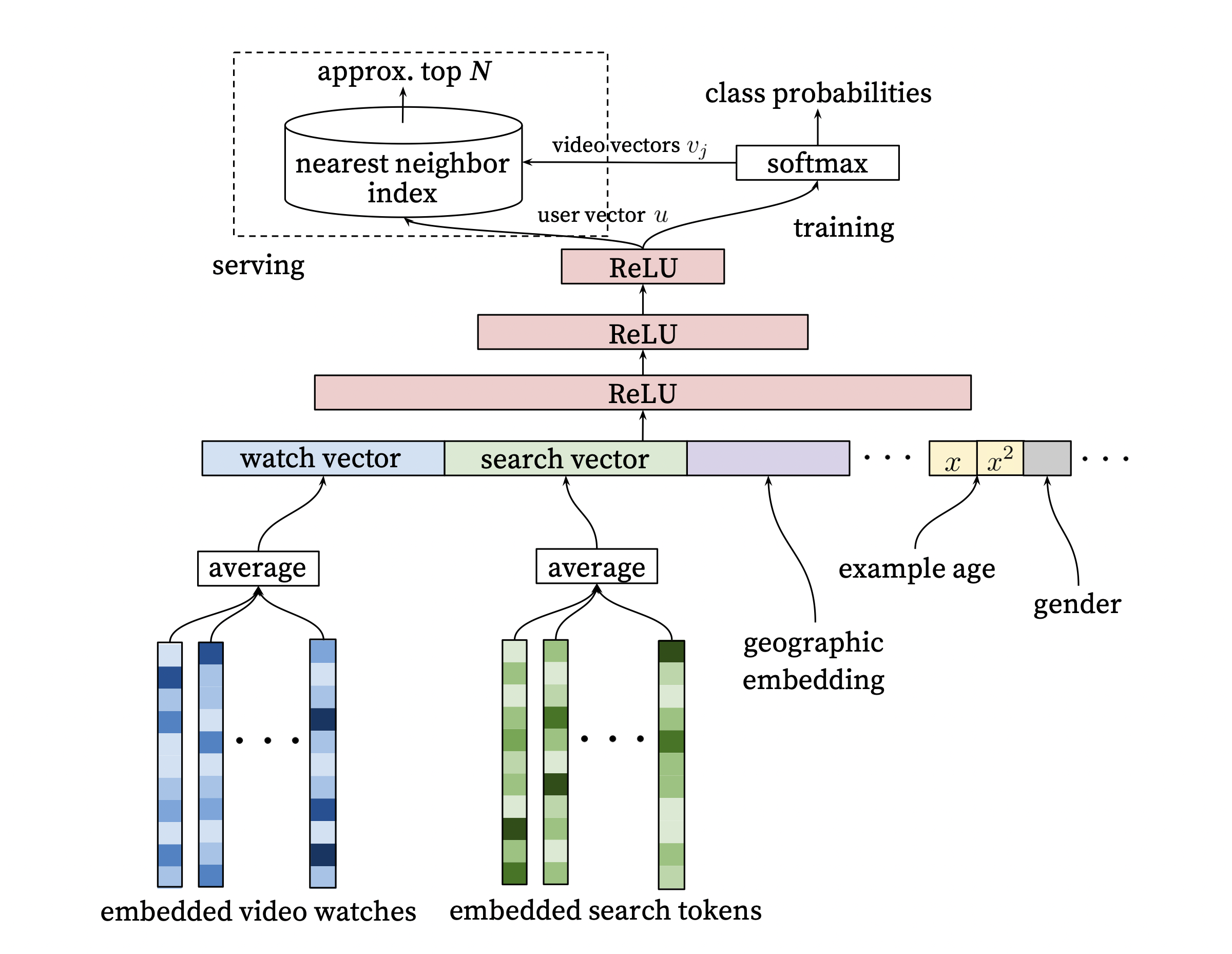
[출처] https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/45530.pdf, Deep Neural Networks for YouTube Recommendations
주어진 사용자에 관해 Top N의 수백개의 추천 아이템을 생성한다.
유저를 Input으로 하여 상위 N개의 비디오를 추출한다.
Watch Vector and Search Vector
Watch Vector는 유저의 과거 시청 이력, Search Vector는 유저의 검색 이력에 대한 임베딩 벡터이다.
마지막에 본 비디오나 유저의 마지막 검색어가 너무 큰 영향력을 갖지 않도록 평균을 낸다.
Demographic & Geographic features
성별 등의 인구통계학 정보와 지리적 정보를 feature로 포함한다.
Example Age features
모델이 과거 데이터 위주로 편향되어 학습되는 문제를 방지하고자 하는 것이다.
시청 로그가 학습 시점으로부터 경과한 정도를 feature로 포함한다.
Bootstraping 현상을 방지하고 Freshness를 제고한다.
위의 다양한 feature vector를 한 번에 concatenate한 후 $n$개의 dense layer를 거쳐서 user vector를 생성한다.
최종 output layer는 여러 비디오의 확률에 대한 softmax function이 된다.
Serving
특정 시간($t$)에 유저 $U$가 $C$라는 context를 가지고 있을 때, 비디오($i$) 각각을 볼 확률을 계산하는 것이 목표이다.
$$ P(w_t = i | U, C) = \frac{e^{v_i u}}{\sum_{j \in V} e^{v_j u}} $$
유저를 input으로 하여 상위 N개의 비디오를 추출하는 것이 목적이며, 모델을 학습시킨 후 유저 벡터 $u$와 비디오 벡터 $v_j$의 내적을 계산한다.
모든 비디오에 관해 벡터 내적을 계산하는 것을 불가능하므로 Annoy, Faiss 같은 ANN 라이브러리를 사용하여 빠르게 서빙한다.
Ranking
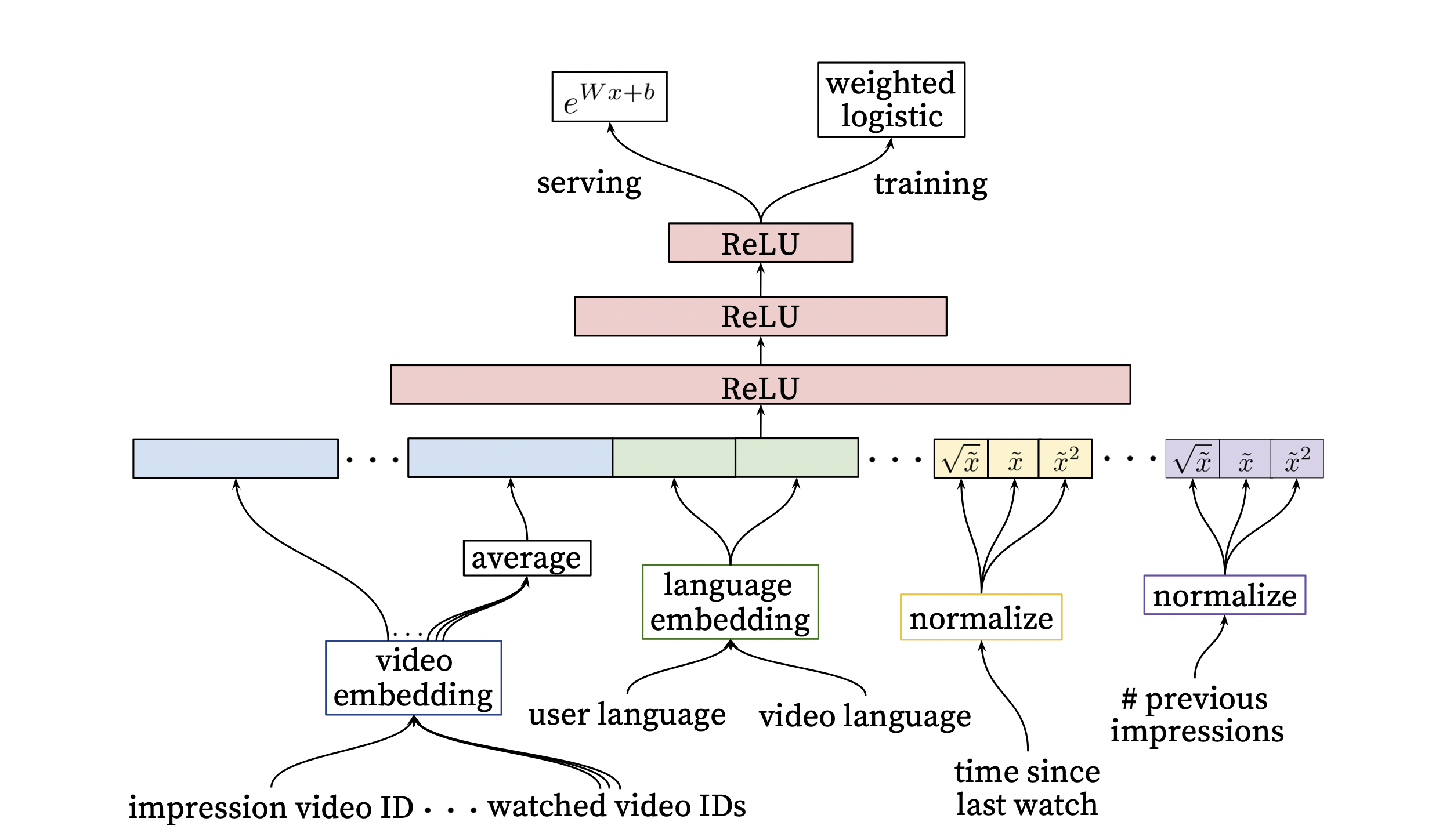
[출처] https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/45530.pdf, Deep Neural Networks for YouTube Recommendations
CG 단계에서 생성한 비디오 후보들을 input으로 하여 최종 추천될 비디오들의 순위를 매기는 문제이다.
주어진 유저-아이템 컨텍스트에 대해서 해당 아이템이 노출되었을 때 유저가 클릭한 확률을 구해야 하므로 Logistic 회귀를 사용한다.
딥러닝 모델로 유저, 비디오 feature를 좀 더 풍부하게 사용하여 스코어를 구하고, 최종 추천 리스트를 제공한다.
Loss function에 단순히 클릭 여부를 반영하는 것이 아니라 시청 시간을 가중치로 한 값을 반영한다.
유저가 특정 채널에서 얼마나 많은 영상을 봤는지, 영상의 과거 시청 여부 등 다양한 user actions feature을 사용하는데, 여기서는 DL 구조보다는 도메인 전문가의 역량이 좌우된다.
네트워크를 통과한 뒤 비디오가 실제로 시청될 확률로 매핑한다.
시청 여부만을 맞히는 CTR 예측인 $P(watch) \in [0, 1]$와 유사하다.
Loss function에서 단순히 binary가 아니라 weighted cross-entropy loss를 사용한다.
비디오 시청 시간으로 가중치를 주며, 낚시성, 광고성 콘텐츠를 업로드하는 어뷰징을 감소시킨다.
'AI > 추천 시스템' 카테고리의 다른 글
| RNN 계열의 GRU 모델을 활용한 GRU4Rec (0) | 2022.03.19 |
|---|---|
| Autoencoder를 응용한 추천 시스템 (0) | 2022.03.13 |
| ANN(Approximate Nearest Neighbor)과 ANNOY (0) | 2022.03.13 |
| Word2Vec을 응용한 Item2Vec (0) | 2022.03.13 |
| Bayesian Personalized Ranking(BPR) (0) | 2022.03.13 |
Contents
소중한 공감 감사합니다.