AI/추천 시스템
User Behavior Feature를 활용하는 DIN(Deep Interest Network)과 BST(Behavior Sequence Transformer)
- -
Deep Interest Network(DIN)
유저가 과거에 행동했던 기록인 User Behavior Feature를 처음 사용한 모델이다.
DIN의 등장 배경
더 많은 유저의 과거 행동 정보와 같은 다양한 feature를 모델에 사용하고 싶다는 아이디어에서 출발한 것이다.
기존의 딥러닝 기반 모델들은 embedding 하고 MLP를 통과시키는 유사한 패러다임을 따른다.
특히, Sparse feature들을 저차원으로 임베딩한 후 이를 fully connected layer인 MLP의 입력으로 사용한다.
그러나 이러한 방식은 사용자의 다양한 관심사를 반영할 수 없다.
사용자가 기존에 소비한 아이템 리스트를 User Behavior Feature로 만들어서 예측 대상 아이템과 이미 소비한 아이템 사이의 관련성을 학습할 수 있도로 한다.
User Behavior Feature
User Behavior Feature는 다른 feature들과는 다르게 one-hot encoding이 아니라 multi-hot encoding으로 된 것이 특징이다.
이는 유저가 과거에 소비한 아이템이 단순히 하나가 아니라 둘 이상일 수도 있어서이다.
DIN 구조
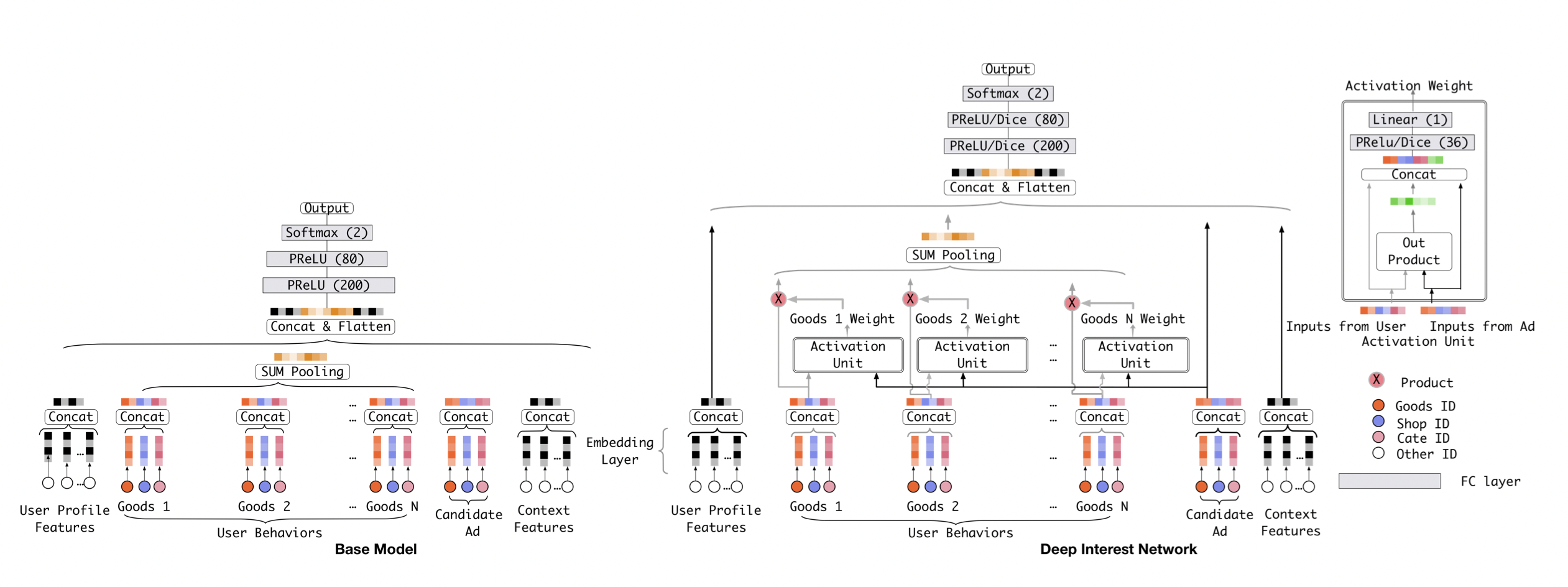
[출처] https://arxiv.org/pdf/1706.06978.pdf, Deep Interest Network for Click-Through Rate Prediction
Embedding Layer와 Fully Connected Layer는 다른 모델들과 모두 유사하지만, 그 사이의 Local Activation Layer이 존재한다.
Local Activation Layer
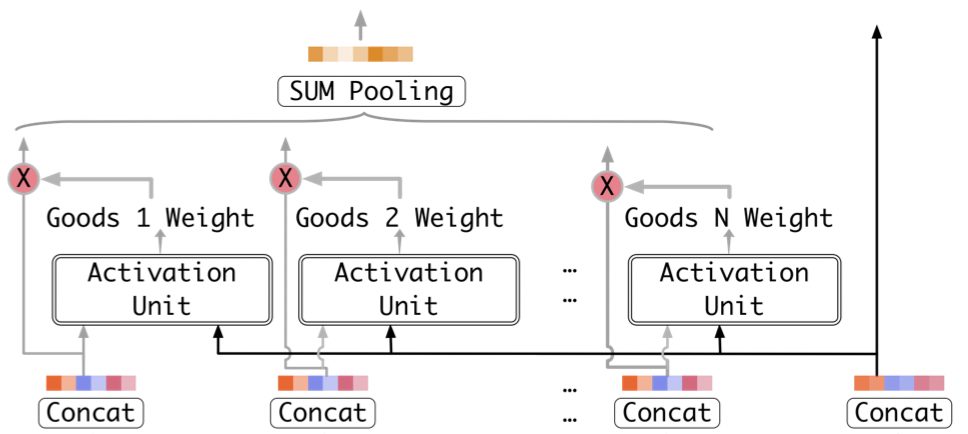
[출처] https://arxiv.org/pdf/1706.06978.pdf, Deep Interest Network for Click-Through Rate Prediction
후보군이 되는 예측 아이템을 기존에 본 아이템들의 연관성을 pairwise로 계산하여 하나의 linear한 스칼라값의 가중치로 표현한다.
이것이 바로 activation weight이며, 예측하려는 아이템과 과거의 사용자의 아이템이 얼마나 연관이 있는지를 보여주는 것이다.
어떤 한 아이템과의 연산에 의한 Weight 값이 높으면 해당 아이템과 연관성이 높으므로 과거의 정보를 많이 활용하겠다는 의미이다.
그렇지 않으면 해당 아이템이 예측하려는 아이템과 연관성이 낮으므로 최대한 덜 반영하겠다는 것이다.
예를 들어, 후보 광고에 따라서 과거 User Behavior에서 소비한 광고들의 weight 크기가 달라지는 것이다.
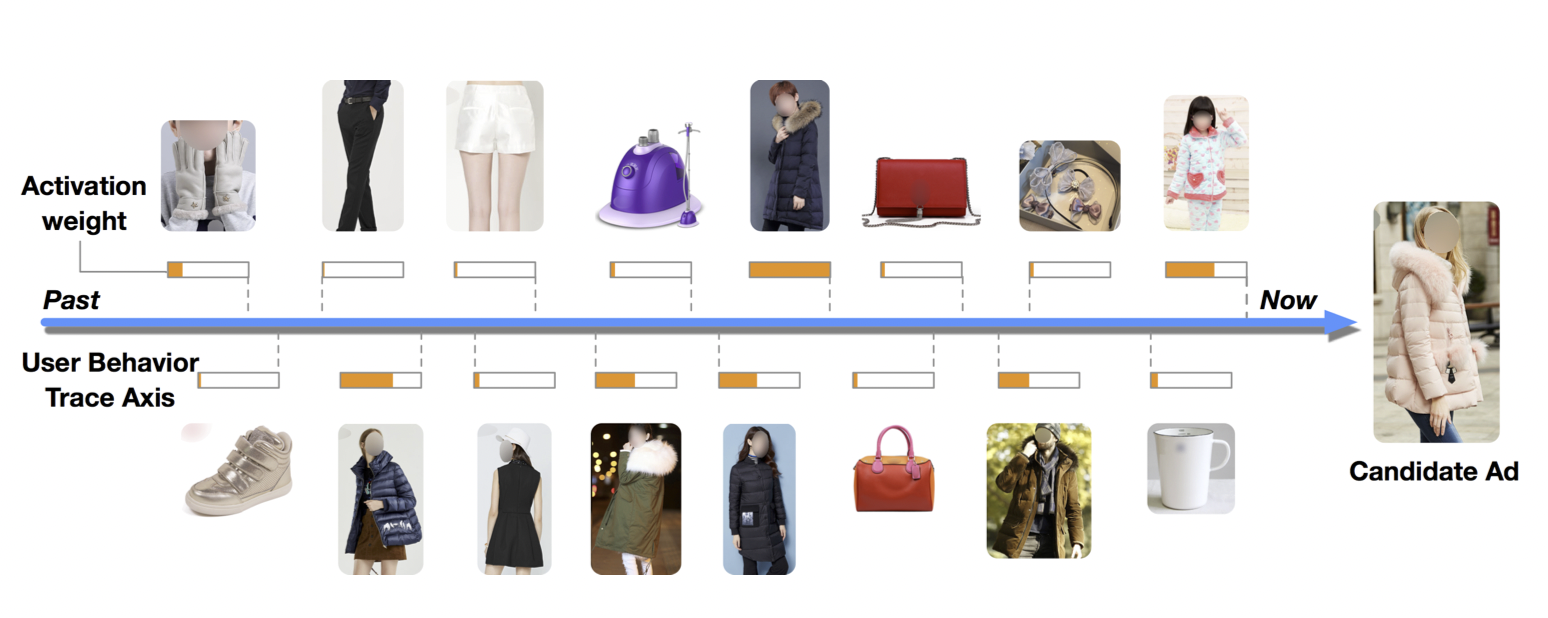
[출처] https://arxiv.org/pdf/1706.06978.pdf, Deep Interest Network for Click-Through Rate Prediction
그렇게 구한 $N$개의 임베딩이 weight와 곱해지고 나서는 전체 임베딩을 다 더하여 계속해서 같은 차원을 유지하도록 sum pooling한다.
Weighted Sum Pooling을 하여 여러 개의 표현 벡터를 가중 합한 값을 출력으로 사용한다.
이는 Transformer의 attention 매커니즘과 유사하다.
그 외의 다른 one-hot encoding된 feature들은 이 레이어를 통과하지 않고 곧바로 마지막 layer로 들어가게 된다.
다른 one-hot encoding된 feature들과 Local Activation Layer를 통과한 결과를 모두 concatenate하여 마지막에 MLP를 통과시켜서 예측 아이템의 CTR을 예측하게 된다.
후보 아이템에 따라서 과거 User Behavior에서 소비한 아이템들의 weight 크기가 달라진다.
Behavior Sequence Transformer(BST)
어떠한 순서로 유저가 행동했을 때 다음에 노출될 아이템의 CTR이 얼마일지를 더 정확하게 예측할 수 있으며, transformer를 사용한 CTR 예측 모델이다.
CTR 예측과 Transformer
CTR 예측 데이터와 NLP 번역 데이터 간의 공통점
대부분 sparse feature로 구성되어 있다.
Low-order와 high-order feature interaction이 모두 존재하여 비선형적 관계를 이룬다.
문장의 순서가 중요하듯이 사용자의 행동 순서(user behavior sequence) 또한 중요하다.
앞서 DIN에서도 transformer의 attention 역할을 하는 local activation unit을 사용했다.
그래서 NLP 분야 전반에서 강력한 성능을 보이는 Transformer 구조를 CTR 예측에도 적용해볼 수 있다.
Transformer
Transformer에 관한 자세한 내용은 이 글을 참고하면 된다.
https://glanceyes.tistory.com/entry/Deep-Learning-Transformer
Self-Attention을 사용하는 Transformer(트랜스포머)
Sequential Model Sequential Model이 어려운 이유 언어 문장을 예로 들면 완벽한 문장 구조에 대응되도록 문장을 만드는 경우는 흔치 않은데, 이러한 문제는 sequential model에 있어서 난관이다. 또한 기존 Se
glanceyes.com
https://glanceyes.tistory.com/entry/Transformer의-Multi-Head-Attention과-Transformer에서-쓰인-다양한-기법
Transformer의 Multi-Head Attention과 Transformer에서 쓰인 다양한 기법
앞서 우리는 입력으로 주어진 sequence에서 어떠한 부분에 주목할지를 예측에 반영하는 attention 기법을 배웠다. 이러한 Self-Attention에서 좀 더 나아가 head를 여러 개 사용하여 주어진 데이터를 이해
glanceyes.com
Attention Mechanism
입력 값의 어떤 부분에 주의(attention)를 기울일 것인지를 찾는 것이다.
Key-Value 쌍들이 주어질 때, 알고자 하는 Query에 대응되는 Value를 계산하는 것이다.
이는 Query와 Key들의 연관성(유사도)을 가중치로 하여 Value들의 가중 합으로 계산한다.
$$ \text{Attention}(Q, K, V) = \text{Value of} \; Q = \text{similarity}(Q, K) \times V $$
입력, 출력의 길이를 고려하지 않아도 단어 간 의존성을 파악할 수 있다.
번역 문제에서 번역할 문장의 길이를 고정하지 않아도 사용 가능한 것과 같다.
NLP에서는 주어진 단어(Query)가 전체 단어(Keys)와 각각 얼마나 관계가 있는지를 가중치로 사용하여, 전체 단어에 대응되는 값들(values)의 가중 합으로 주어진 단어에 대응되는 결과를 도출하는 것이다.
Scale Dot-Product Attention
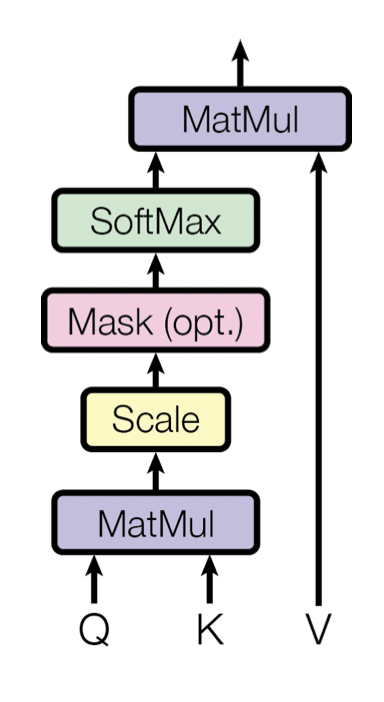
[출처] https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf, Attention is All You Need
Query와 Key 벡터를 내적한 값을 Key의 차원 크기($d_k$)에 비례하여 스케일링하고, 이를 softmax 함수에 넣어서 0과 1사이의 값으로 변환한 것을 Query와 Key 사이의 유사도로 고려한다.
$$ \text{Attention}(Q, K, V) = \text{softmax}\big{(}\frac{QK^T}{\sqrt{d_k}}\big{)}V $$
Scale dot-product attention은 self-attention에 해당된다.
여기서 self-attention인 Query, Key, Value가 모두 같은 도메인에 속하는 attention을 뜻한다.
Multi-Head Attention
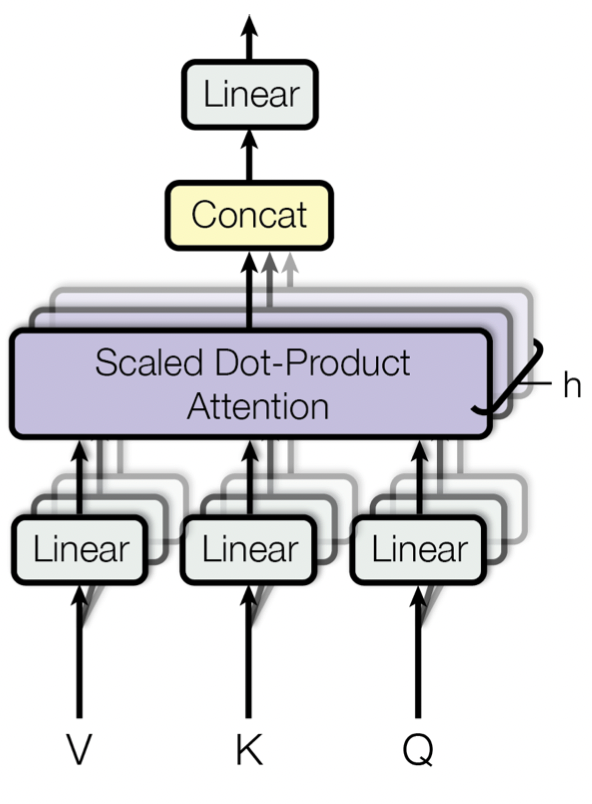
[출처] https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf, Attention is All You Need
차원이 큰 attention을 한 번에 수행하는 것보다 여러 개의 작은 attention을 병렬로 처리하는 것이 효과적이다.
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(head_1, \cdots, head_h)W_0\\ \text{where head}_i = \text{Attention}(QW_i^Q,KW_i^K, VW_i^V) $$
Transformer의 구조
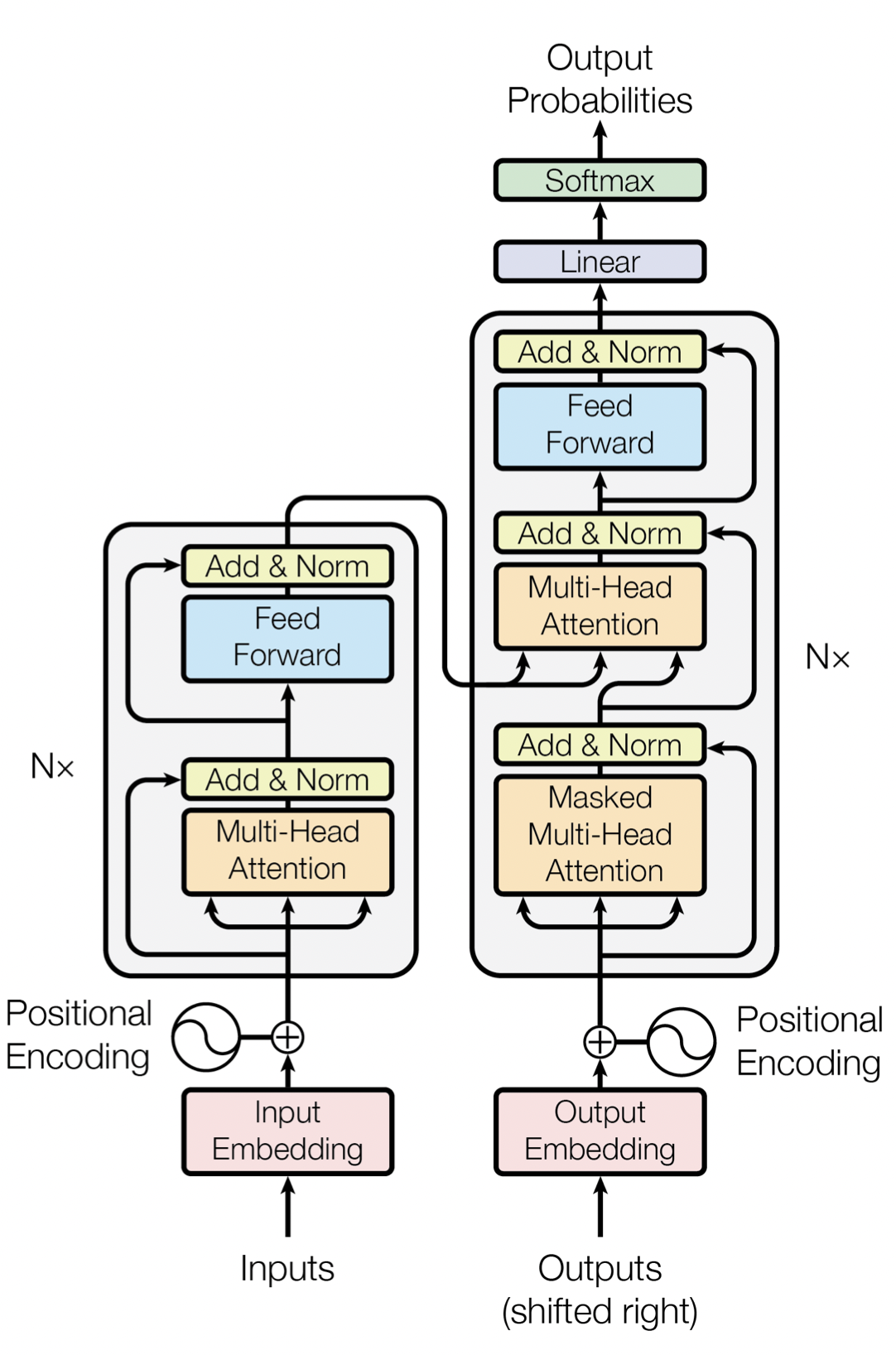
[출처] https://papers.nips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf, Attention is All You Need
Encoder-Decoder 구조
각각 여러 개의 동일한 레이어를 쌓아 구성한다.
Attention 외의 사용 기법들
- Positional Encoding
- RNN과 달리 attention만으로는 단어의 순서를 표현할 수 없다.
- $sin$, $cos$ 함수를 사용하여 단어가 등장하는 위치 정보를 feature embedding에 더해준다.
- Add & Norm
- Add: Residual Connection
- Norm: Layer Normalization
BST의 구조
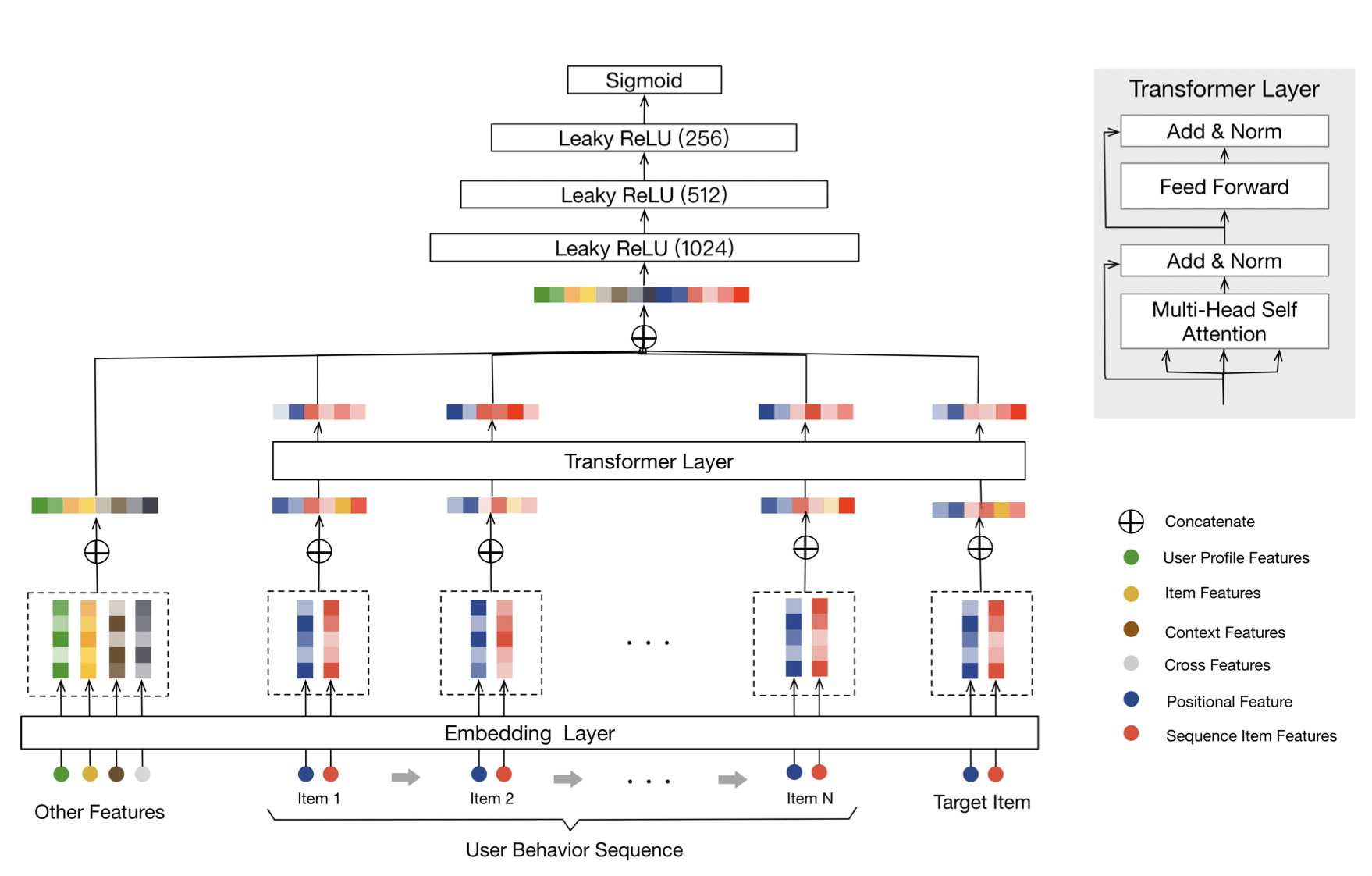
[출처] https://arxiv.org/pdf/1905.06874.pdf, Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
DIN과 큰 차이 중 하나는 User Behavior Sequence를 그대로 모델의 입력 값으로 넣어주는 것이다.
User Behavior Sequence와 Target Item을 모두 transform layer의 입력으로 넣어준다.
Transformer Layer에서는 Transformer의 decoder를 제외하고 encoder 부분만을 사용한다.
Transformer Encoder Layer
$$ \text{Attention}(Q, K, V) = \text{softmax}\big{(}\frac{QK^T}{\sqrt{d_k}}\big{)}V\\ Q = EW^Q, \qquad K = EW^K, \qquad V = EW^V $$
Transformer Layer의 입력은 User Behavior Sequence와 현재 예측하려는 Target Item이다.
입력 값은 임베딩 matrix인 $E$로 표현된다.
$$ \mathbf{S} = \text{MultiHead}(E) = \text{Concat}(head_1, \cdots, head_h)W^H\\ \text{head}_i = \text{Attention}(EW^Q, EW^K, EW^V) $$
Point-wise Feed-Forward Neural Networks
$$ \begin{align} \mathbf{F} &= \text{FFN}(\mathbf{S})\\ \mathbf{S'} &= \text{LayerNorm}(\mathbf{S} + \text{Dropout}(\text{MH}(\mathbf{S})))\\ \mathbf{F} &= \text{LayerNorm}(\mathbf{S'} + \text{Dropout}(\text{LeakyReLU}(\mathbf{S'W}^{(1)} + b^{(1)})\mathbf{W^{(2)}} + b^{(2)}) \end{align} $$
Stacking the Self-Attention Blocks
$$ \begin{align} \mathbf{S}^{(i + 1)} &= \text{MH}(\mathbf{F}^{(i)})\\ \mathbf{F}^{(i + 1)} &= \text{FFN}(\mathbf{S}^{(i + 1)}) \end{align} $$
다른 모델과의 비교
DIN
DIN에서는 Local Activation Layer를 통해 유저가 과거에 소비한 아이템과 현재 노출할 아이템의 연관성을 구한다.
이 과정에서 단순히 sum pooling을 통해 과거에 소비한 아이템을 더하는 방식을 취한다.
하지만 BST에서는 유저가 과거에 어떠한 아이템을 소비했는지 뿐만이 아니라 어떠한 순서로 소비했는지 그 sequence까지 모델의 feature로 사용해서 현재 노출할 아이템과의 관련성을 모델링한다.
이 관련성을 transformer layer를 사용하여 구한다.
Transformer
Transformer와는 다르게 BST는 dropout과 leakyReLU를 추가한다.
또한 6개를 쌓은 Transformer와는 달리 BST에서는 인코더 블럭을 1~4개 정도 쌓아서 사용한다.
한 개를 쌓았을 때 가장 좋은 예측 성능을 보인다고 알려져 있다.
Transformer는 positional encoding을 사용하지만, BST는 $pos(v_i) = t(v_t) - t(v_i)$이라는 custom positional encoding을 사용한다.
현재 예측하려고 하는 시간과 과거에 어떤 한 아이템을 소비한 시간의 차이를 사용하는 방식이다.
BST의 성능
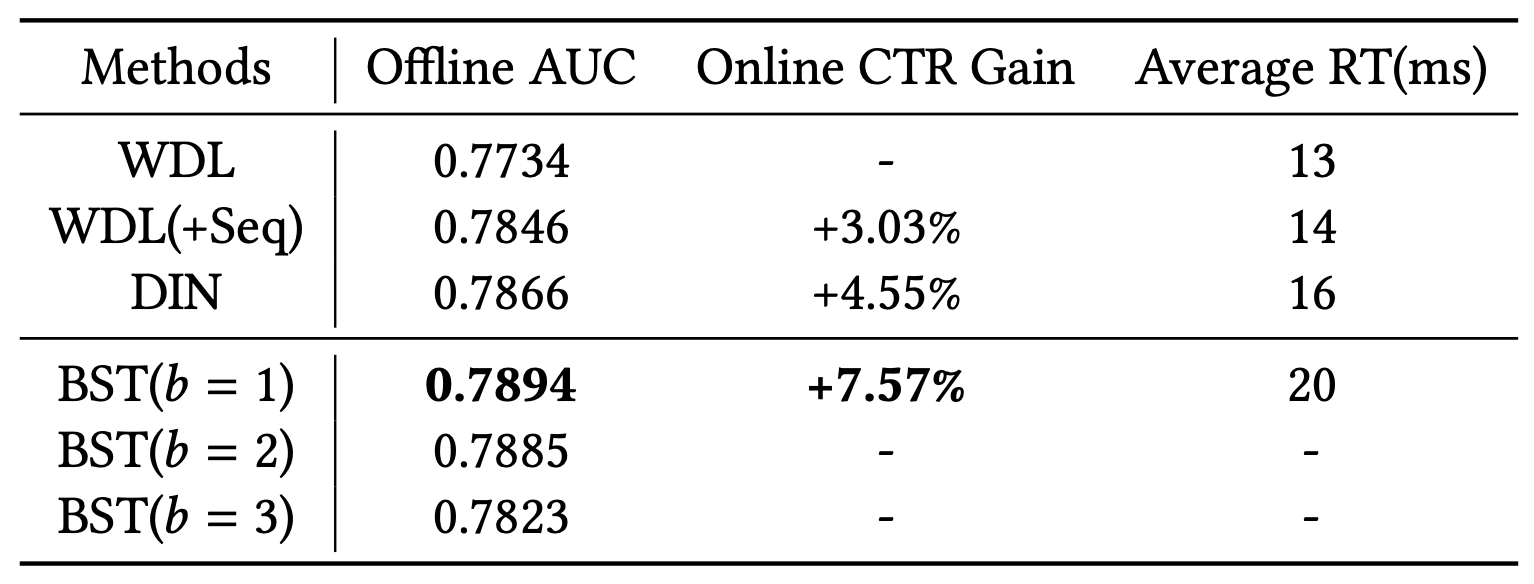
[출처] https://arxiv.org/pdf/1905.06874.pdf, Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
Transformer는 CTR 예측에서 SOTA(State-of-the-art)의 성능을 보인다.
단, transformer 블록을 두 개 이상 쌓을 때 오히려 성능이 감소하는 걸 볼 수 있는데, 이는 CTR 예측의 sequence는 machine translation와 같은 NLP sequence보다는 덜 복잡한 것으로 추측된다.
출처
1. 네이버 부스트캠프 AI Tech 추천시스템 Stage 2 기초 강의
'AI > 추천 시스템' 카테고리의 다른 글
| MAB(Multi-Armed-Bandit)를 활용한 Thompson Sampling과 LinUCB(Linear Upper Confidence Bound) (0) | 2022.03.19 |
|---|---|
| 추천 시스템과 Multi-Armed Bandit(MAB) 알고리즘 (0) | 2022.03.19 |
| CTR를 딥 러닝으로 예측하는 Wide & Deep 모델과 DeepFM (0) | 2022.03.19 |
| Gradient Boosting을 사용한 GBM(Gradient Boosting Machine)과 연관 모델 (0) | 2022.03.19 |
| Context 기반 추천 모델인 FM(Factorization Model)과 FFM(Field-aware Factorization Machine) (0) | 2022.03.19 |
Contents
소중한 공감 감사합니다.