AI/추천 시스템
CTR를 딥 러닝으로 예측하는 Wide & Deep 모델과 DeepFM
- -
딥 러닝을 사용한 CTR Prediction
CTR 예측은 유저가 주어진 아이템을 클릭할 확률을 예측하는 문제이다.
주로 광고에 사용되며 광고주 및 서비스 제공자들의 이익 창출에 사용된다.
그러나 현실의 CTR 데이터를 기존의 선형 모델로 예측하는 데는 한계가 있다.
Highly sparse하고 데이터의 차원이 너무 클 수 있으며, feature 간의 non-linear association이 존재한다.
그래서 이러한 데이터에 효과적인 딥러닝 기법들이 CTR 예측 문제에 적용된다.
Wide & Deep 모델
선형적인 모델(Wide)과 비선형적인 모델(Deep)을 결합하여 기존 모델들의 장점을 모두 취하고자 하는 모델이다.
Wide & Deep 등장 배경
추천 시스템에서 해결해야 할 두 가지 과제는 Memorization과 Generalization이다.
Memorization(암기)
함께 빈번히 등장하는 아이템 또는 feature 관계를 과거 데이터로부터 학습해야 한다.
Logistic Regression과 같은 선형 모델에 적합하다.
모델이 단순한만큼 학습을 통한 파라미터의 수렴이 상대적으로 빠르고, 모델에 사용되는 feature가 추가되더라도 모델의 확장과 해석이 용이하다.
그러나 학습 데이터에 없거나 부족한 feature 조합에 취약하다는 단점이 있다.
Generalization(일반화)
드물게 발생하거나 전혀 발생한 적 없는 아이템 또는 특성의 조합을 기존의 관계로부터 발견하는 것이다.
FM(Factorization Machine), DNN(Deep Neural Network)과 같은 임베딩 기반 모델에 적합하다.
이러한 모델은 일반화가 가능하지만, 고차원의 희소한 데이터로부터 저차원의 임베딩을 만드는 것은 어렵다.
이 둘을 결합하여 사용자의 검색 쿼리에 맞는 앱을 추천하는 모델이 필요하다.
Wide & Deep 모델의 구조
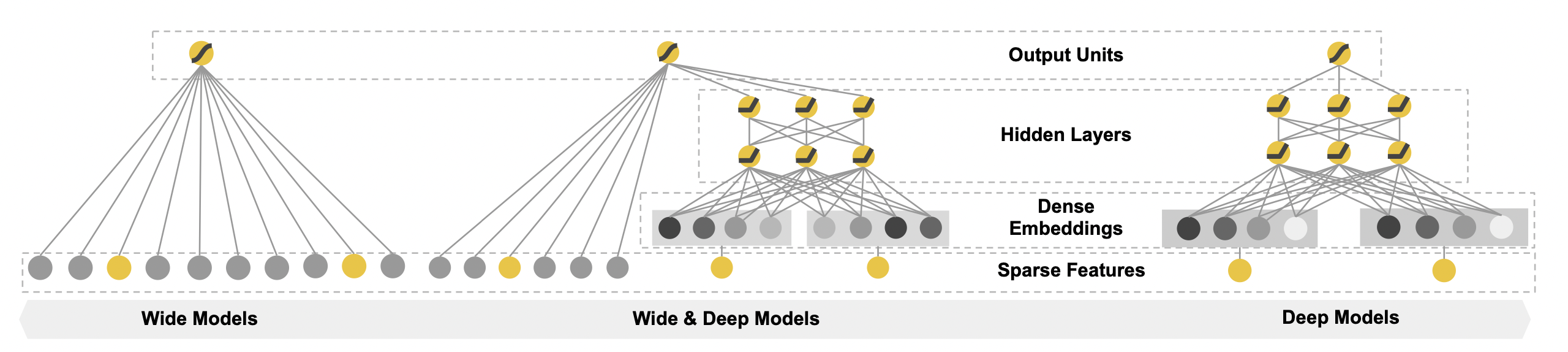
[출처] https://dl.acm.org/doi/pdf/10.1145/2988450.2988454, Wide & Deep Learning for Recommender Systems
The Wide Component
일반적인 선형 모델은 다음과 같다.
$$ y = w^T x + b \quad (w = [w_1, \cdots, w_n], \; x = [x_1, \cdots, x_n], \; b \in \mathbb{R}) $$
그러나 이러한 모델링은 서로 다른 두 개의 interaction은 학습할 수 없다.
그래서 Wide Component에서는 Cross-Product Transformation을 사용한다.
$$ \phi_k(x) = \prod_{i = 1}^d x_i^{c_{ki}} \qquad c_{ki} \in {0, 1} $$
가능한 모든 변수들 사이의 cross-product를 표현한다면 학습해야 하는 가중치가 기하급수적으로 증가한다.
그래서 주요 feature 두 개에 관한 second order cross product만 사용할 수 있다.
The Deep Component
Feed-Forward Neural Network
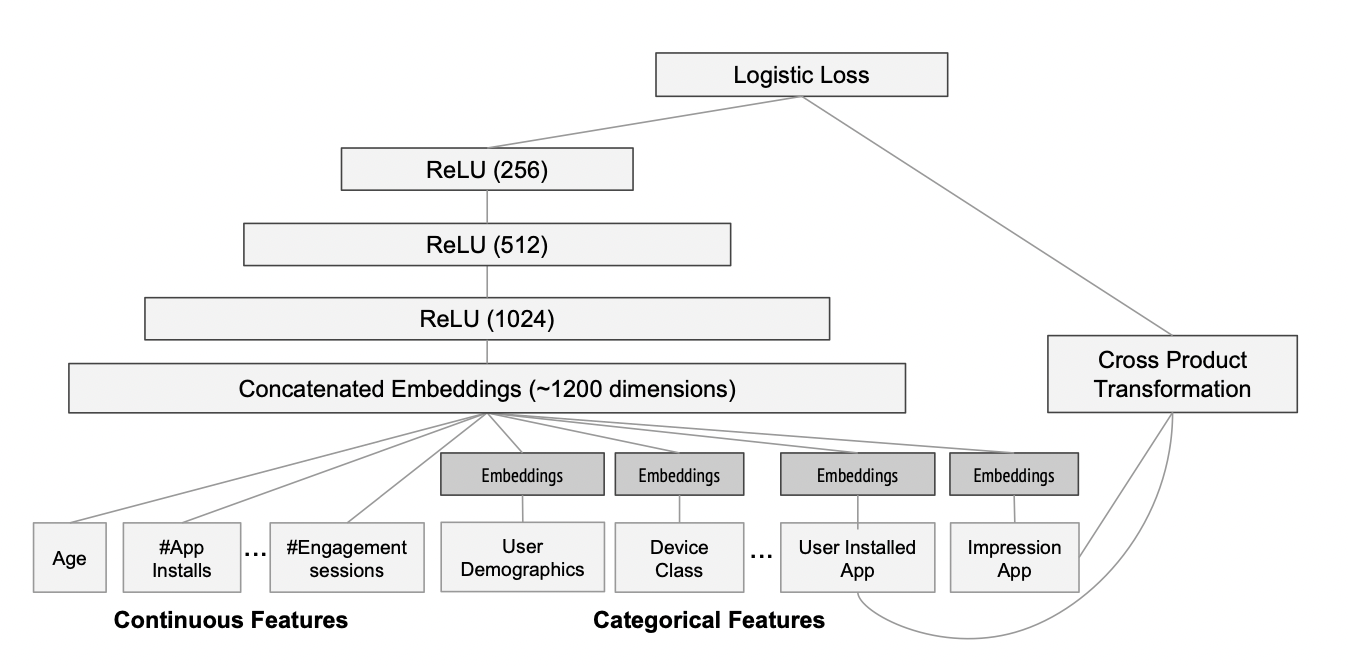
[출처] https://dl.acm.org/doi/pdf/10.1145/2988450.2988454, Wide & Deep Learning for Recommender Systems
세 개의 Layer로 구성되었으며, ReLU 함수를 사용한다.
연속형 변수는 그대로 사용하고, 범주형 변수는 feature embedding 후 사용한다.
Wide Component와 Deep Component를 합쳐서 Wide & Deep 모델을 형성할 수 있다.
Wide & Deep 모델의 손실함수
$$ P(Y = 1 | x) = \sigma(w_{\text{wide}}^{\text{T}}[x, \phi(x)] + w_{\text{deep}}^{\text{T}}a^{(lf)} + b ) $$
Wide Component를 의미하는 term에서 $x$는 주어진 $n$개의 변수를 의미하고, $\phi(x)$는 $n$개의 변수 사이의 cross-product transformaton을 의미한다.
Deep Component를 의미하는 term은 MLP 레이어를 일반화한 것이다.
Wide Component와 Deep Component를 더한 뒤 global bias를 추가하여 최종적으로 sigmoid를 취하면 CTR를 예측할 수 있다.
Wide & Deep 모델의 특징
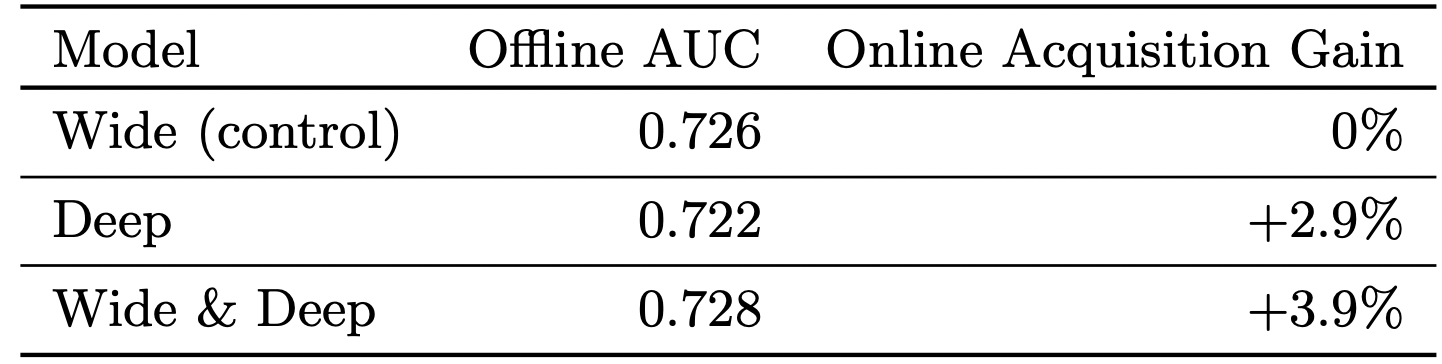
[출처] https://dl.acm.org/doi/pdf/10.1145/2988450.2988454, Wide & Deep Learning for Recommender Systems
Baseline인 Wide 모델과 Deep 모델은 각각 Offline, Online에서 좋은 성능을 보이는 서로 다른 양상을 띠지만, 두 개의 모델을 결합하여 만든 Wide & Deep 모델은 모두 좋은 성능을 보인다.
DeepFM
Wide & Deep 모델과 달리 Wide와 Deep Component인 두 요소가 입력값을 공유하도록 한 end-to-end 방식의 모델이다.
[출처] https://arxiv.org/pdf/1703.04247.pdf, DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM의 등장 배경
추천 시스템에서는 implicit feature interaction을 학습하는 것이 중요하다.
예) 식사 시간에 배달앱 다운로드 수 증가 (order-2 interaction)
기존 모델들은 low-order 또는 high-order interaction 중 어느 한 쪽에만 강한 성향을 띤다.
Wide & Deep 모델은 이 둘을 통합하여 문제를 해결했지만, wide component에 cross-product transformation이라는 feature engineering이 필요하다는 단점이 있다.
FM을 wide component로 사용하여 입력값을 공유하도록 하는 것이 DeepFM의 아이디어이다.
DeepFM = Factorization Machine + Deep Neural Network
DeepFM의 구조
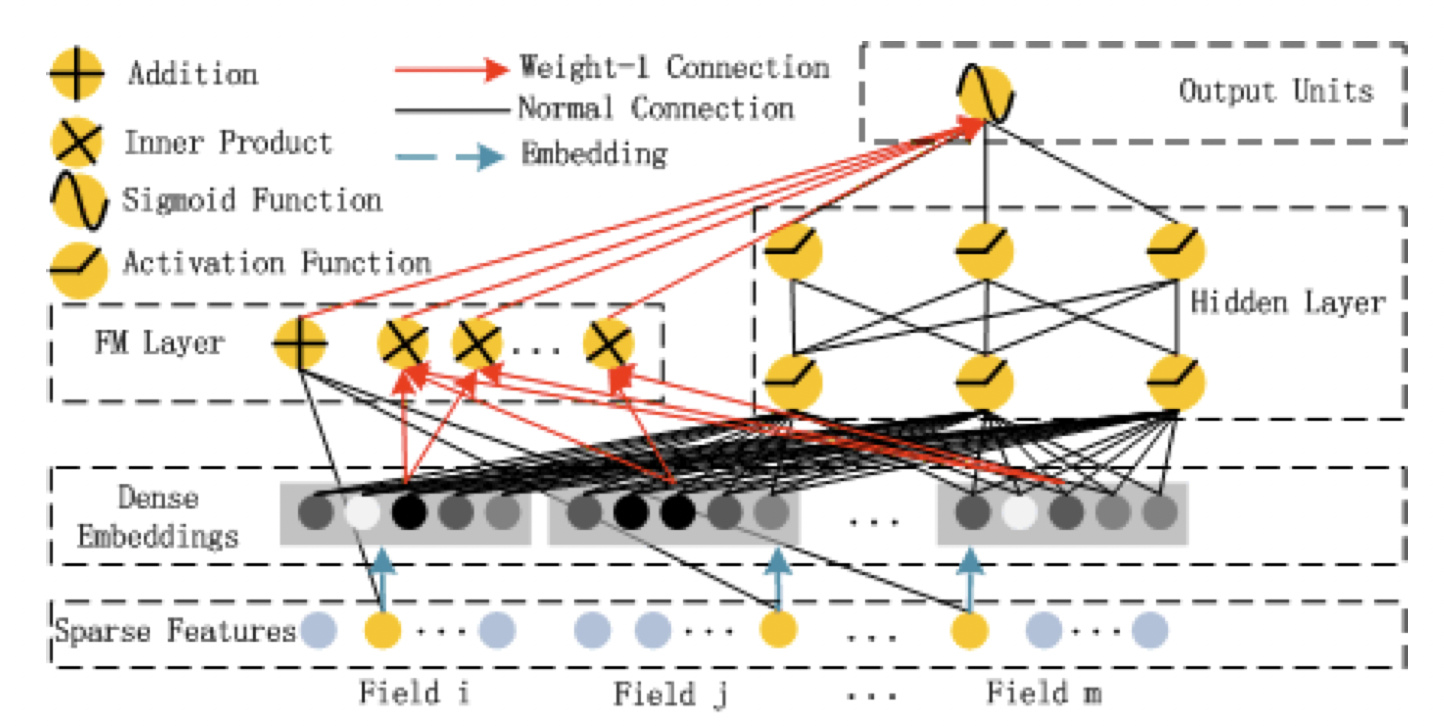
FM Component
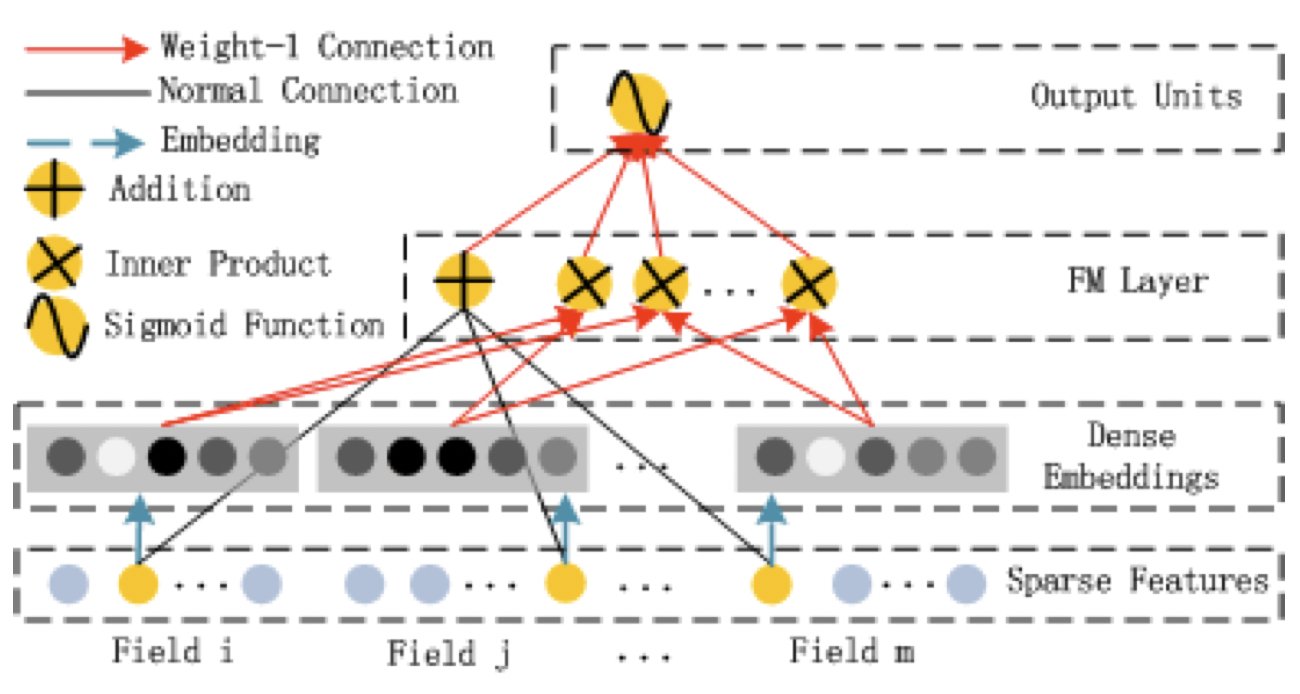
[출처] https://arxiv.org/pdf/1703.04247.pdf, DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
기존의 FM 모델과 완전히 동일한 구조이며, order-2 feature interaction을 효과적으로 잡는다.
$$ \hat{y}(x) = \big{(}w_0 + \sum_{i=1}^n w_i x_i + \sum_{i=1}^n \sum_{j=i+1}^n \big{<} v_i, v_j \big{>} x_{i} x_{j} \big{)}\\ w_i \in \mathbb{R},\quad w_i \in \mathbb{R}, \quad v_i \in \mathbb{R}^k $$
각각의 Field가 하나의 feature를 의미하고, DeepFM에서는 모두 sparse한 feature로 구성하고 있다.
위의 FM Component 구조 이미지에서 Addition에 해당되는 term인 $\sum_{i=1}^n w_i x_i$은 각각의 feature가 갖는 weight가 학습되는 것이다. (Addition은 임베딩한 feature를 사용하지 않고 sparse feature를 가지고 진행한다.)
Second-order feature interaction(두 개의 feature 사이의 상호작용)을 구하는 term인 $ \sum_{i=1}^n \sum_{j=i+1}^n \big{<} v_i, v_j \big{>} x_{i} x_{j}$은 각각의 feature를 동일한 차원으로 embedding하고, 이들끼리 서로 내적하여 feature 간의 interaction을 학습하는 것이다.
Deep Component
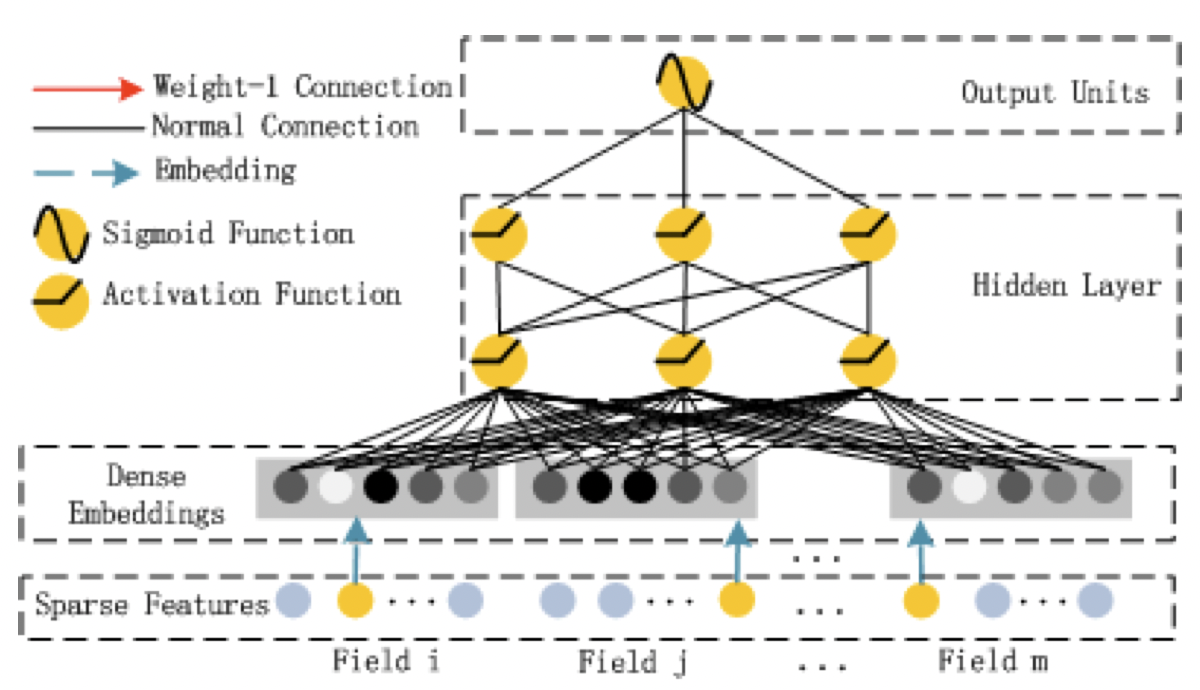
[출처] https://arxiv.org/pdf/1703.04247.pdf, DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
[출처] https://arxiv.org/pdf/1703.04247.pdf, DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
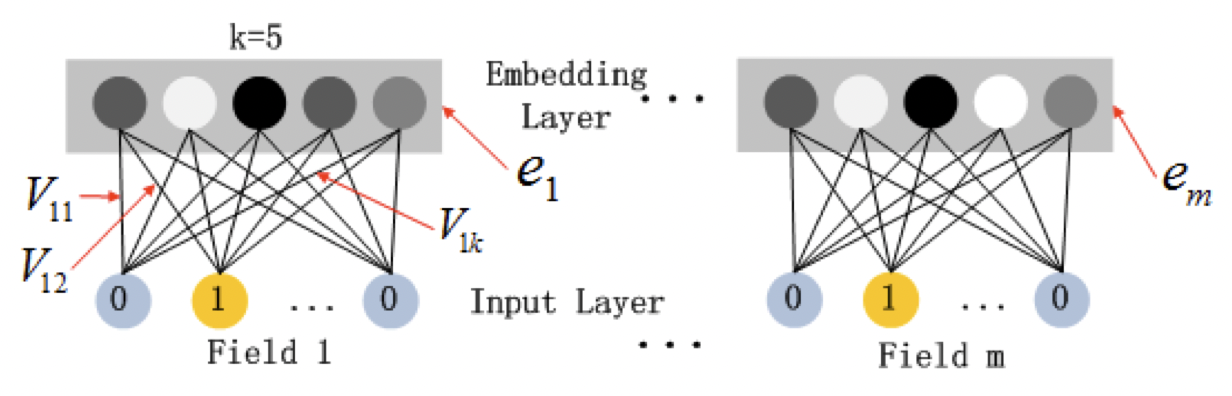
모든 feature들은 동일한 차원($k$)의 임베딩으로 치환된다.
이때, 임베딩에 사용되는 가중치는 FM Component의 가중치인 $V_{ij}$와 동일하다.
그래서 Deep Component의 임베딩과 FM Component의 임베딩이 따로 학습되지 않고 한꺼번에 end-to-end로 학습된다.
$$ a^0 = [e_1, e_2, \cdots, e_m]\\ a^{(l + 1)} = \sigma(W^l a^l + b^l)\\ y_{DNN} = W^{|H| + 1} a^{|H|} + b^{|H| + 1} $$
각각의 embedding은 concatenate 되어서 가로로 붙게 되는데, 이것이 input layer이다.
이후에 $l$개의 feed forward neural network를 쌓게 되면 마지막 layer에서 최종적으로 클릭 여부를 예측할 수 있다.
$$ \hat{y} = sigmoid(y_{FM} + y_{DNN}) $$
다른 DeepCTR 모델과의 비교
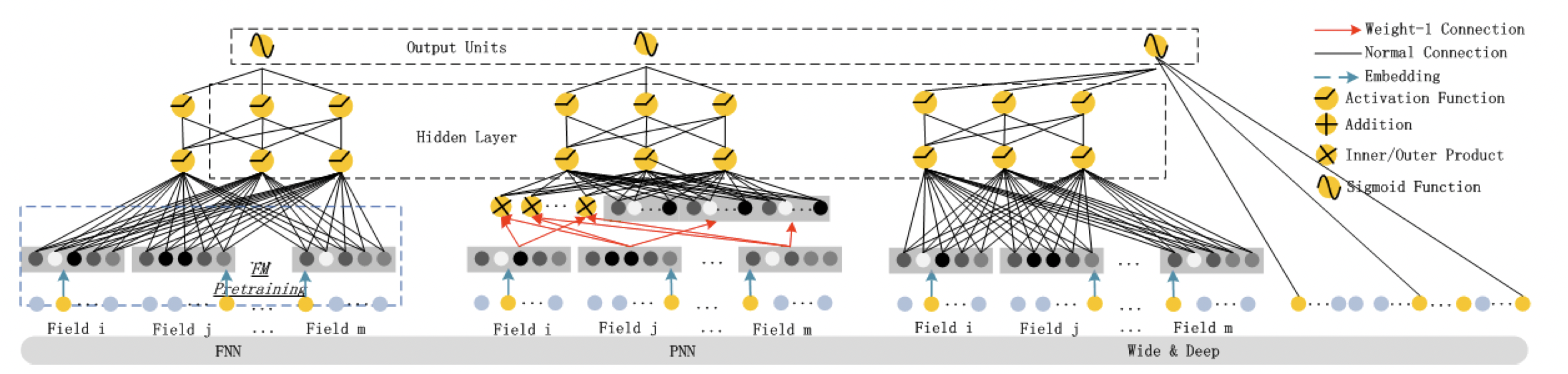
[출처] https://arxiv.org/pdf/1703.04247.pdf, DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
FNN
FM 모델을 사용하지만, end-to-end로 학습하지 않고 FM 모델을 학습한 이후에 그 임베딩을 가지고 와서 다시 딥러닝 모델을 거치는 것이다.
그래서 pre-training이 반드시 필요하다.
PNN
DeepFM와는 다르게 low-order interaction(memorization) 부분에 학습 파라미터가 빠져 있다.
출처
1. 네이버 부스트캠프 AI Tech 추천시스템 Stage 2 기초 강의
'AI > 추천 시스템' 카테고리의 다른 글
| 추천 시스템과 Multi-Armed Bandit(MAB) 알고리즘 (0) | 2022.03.19 |
|---|---|
| User Behavior Feature를 활용하는 DIN(Deep Interest Network)과 BST(Behavior Sequence Transformer) (0) | 2022.03.19 |
| Gradient Boosting을 사용한 GBM(Gradient Boosting Machine)과 연관 모델 (0) | 2022.03.19 |
| Context 기반 추천 모델인 FM(Factorization Model)과 FFM(Field-aware Factorization Machine) (0) | 2022.03.19 |
| RNN 계열의 GRU 모델을 활용한 GRU4Rec (0) | 2022.03.19 |
Contents
소중한 공감 감사합니다.