AI/추천 시스템
추천 시스템에서 자주 사용하는 용어와 평가 지표
- -
2022년 3월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
추천 시스템이란?
서비스는 매우 많은 아이템으로 이루어져 있다.
이 매우 많은 아이템에서 사용자의 데이터를 기반으로 비즈니스 목적에 맞게 사용자가 선호할 만한 아이템을 추천하는 것이다.
Search(검색)와 Recommendation(추천)
검색은 사용자가 의도를 가지고 아이템을 찾는 행위이다.
사용자의 의도가 담긴 쿼리(query)라는 키워드가 사용된다.
검색을 통해 아이템을 소비하는 것을 pull 방식이라고 한다.
추천은 push 방식인데, 사용자가 어떠한 의도를 가진 키워드를 명목적으로 제공하지 않더라도 상품을 사용자에게 노출한다.
추천 시스템의 중요성
과거에는 사용자가 접할 수 있는 상품, 콘텐츠가 제한적이었다.
그러나 웹 • 모바일 환경이 등장하고 다양한 상품과 콘텐츠가 등장하면서 정보가 풍요해졌다.
인기 있는 소수의 아이템이 많이 소비되고, 아주 많은 아이템들이 적게 소비되는 Long Tail의 형태로 변화한다.
그래서 사용자가 정보를 찾는 데 시간이 오래 걸리게 된다.

[출처: https://en.wikipedia.org/wiki/Long_tail, 'Picture by Hay Kranen / PD']
Long-Tail Recommendation은 소수의 인기 있는 아이템이 소비되는 면적은 줄어들고, 그 외의 아주 많은 아이템이 소비되는 면적이 커지는 현상을 반영한 것이다.
사용되는 데이터
- 유저 관련 정보
- 아이템 관련 정보
- 유저 - 아이템 상호작용 정보
유저 관련 정보
유저 프로파일링
- 유저에 관한 정보를 구축하는 것이다.
식별자(Identifier)
- 유저 ID, 디바이스 ID, 브라우저 쿠키
데모그래픽(Demographic) 정보
- 사용자의 성별, 연령, 지역, 관심사 등
- 사용자의 성별 또는 연령은 추정을 통해 생성하기도 한다.
유저 행동 정보
- 페이지 방문 기록, 아이템 평가, 구매 등의 피드백 기록
아이템 관련 정보
메타 데이터(meta data)라고도 한다.
아이템 ID, 아이템의 고유 정보 등으로 아이템 프로파일링을 진행한다.
유저 - 아이템 상호작용 정보
Explicit Feedback
유저에게 아이템에 대한 만족도를 직접 물어본 경우에 해당된다.
Implicit Feedback
유저가 아이템을 클릭하거나 구매한 경우에 해당되며, 보통 Explicit Feedback보다 수가 압도적으로 많다.
Implicit feedback은 explicit feedback과는 달리 사용자의 선호에 대한 암시적인 정보만을 제공하지만, 그것의 수집 효율성 및 generality 덕분에 사용자의 실제 선호를 추정하는 데에 더욱 효율적일 수 있다.
예를 들어, 어떤 한 사용자가 앱을 이용하여 상품을 구매했을 때 리뷰를 작성하는 시나리오를 가정한다.
이때 평점을 작성해야 하는 경우에는 사용자에게 귀찮은 일이 될 수 있으므로 실제로 많은 feedback이 수집되기에는 한계가 있다.
반면에 implicit feedback은 사용자의 모든 기록된 행위를 사용하기 때문에 방대한 양의 데이터를 활용할 수 있으며, 이를 오히려 잘 분석하여 explicit feedback보다 비즈니스의 목적을 더 잘 달성할 수 있다.
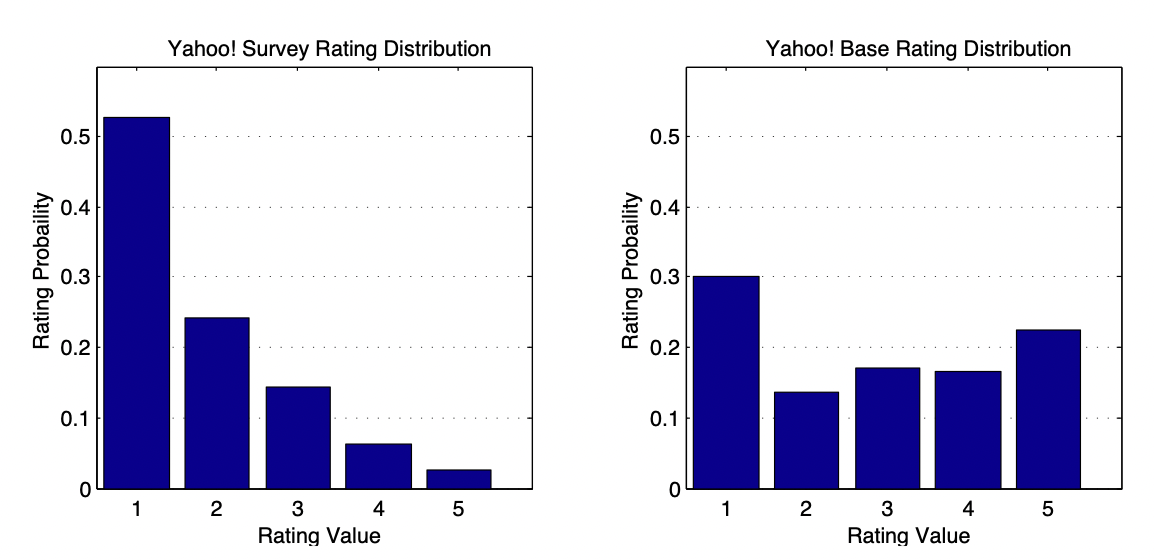
[출처] https://arxiv.org/pdf/1206.5267.pdf, Collaborative Filtering and the Missing at Random Assumption
Explicit feedback을 사용한 추천 시스템에서는 주로 관측된 데이터로부터 관측되지 않은(unseen) 데이터를 예측해야 하는데, 관측된 평점 분포와 랜덤 평점 분포 사이에 불일치가 존재하면 이로 인해 generalizable 하지 않을 수 있음을 유추할 수 있다.
최근 대부분의 추천 연구도 단순 평점 예측보다는 Top-K ranking 추천 문제를 주로 다루고 있을 정도로 implicit feedback이 더 활발히 연구되고 있다.
이는 보다 풍부한 데이터를 활용할 수 있으며, 사용자가 다음에 무엇을 클릭할지를 예측하는 게 주 목표일 때 implicit feedback이 이러한 추천 태스크에 더 적합하기 때문이다.
또한 비즈니스 목표와의 직접적인 연관성이 explicit feedback보다는 좀 더 높다고 볼 수 있다.
Explicit feedback을 사용하여 RMSE를 최적화하는 것이 과연 추천에 도움이 되는지에 관해 의문점이 있다고 볼 수 있는데, 이는 RMSE 기준으로 추천되는 영화가 사용자의 입맛에는 맞더라도 다양하고 새로운 콘텐츠를 발견해줄 수 있는지에 관해서는 만족스럽지 못할 수 있어서다,

그러나 주로 E-Commerce 업체에서는 명확하고 세분화된 사용자 선호를 반영하는 explicit feedback의 강점을 이용하는 경우가 많다.
예를 들어, Coupang에서는 제품을 구매한 사용자가 리뷰에 평점을 매길 수 있는데, 이를 바탕으로 사용자에게 개인화된 추천을 해줄 수 있다.
추천 시스템의 목적
특정 유저에게 적합한 아이템을 추천하거나, 특정 아이템에게 적합한 유저를 추천한다.
그러기 위해서는 유저와 아이템 사이의 상호작용을 평가할 score 값이 필요한다.
랭킹(Ranking)
유저에게 적합한 아이템 Top K개를 추천하는 문제이다.
Top K개를 선정하기 위한 기준 또는 스코어가 필요하지만, 유저가 아이템에 가지는 정확한 선호도를 구할 필요는 없다.
예측(Prediction)
평점, 상품 구매 확률처럼 유저가 아이템을 가질 선호도를 정확하게 예측하는 것이다.
Explicit Feedback
유저가 어떠한 상품 등에 관해 내릴 평점 값을 예측하는 문제에 해당된다.
Implicit Feedback
유저가 어떠한 상품을 조회하거나 구매할 확률 값을 예측하는 문제에 해당된다.
추천 시스템의 평가 지표
추천 모델의 성능 평가의 관점
비즈니스 ・ 서비스 관점
매출, PV의 증가, 유저의 CTR 상승 등이 해당된다.
품질 관점
- 연관성: 추천한 아이템이 유저에게 관련이 있는지
- 다양성: 얼마나 다양한 아이템이 추천되는지
- 새로움: 얼마나 새로운 아이템이 추천되고 있는지
- 참신함: 유저가 기대하지 못한 뜻밖의 아이템이 추천되는지
Offline Test
새로운 추천 모델을 검증하기 위해 가장 우선적으로 수행되는 단계이다.
유저로부터 수집한 데이터를 train, valid, test로 나누어 모델의 성능을 객관적인 지표로 평가한다.
보통 offline test에서 좋은 성능을 보여야 online 서빙에 투입되지만, serving bias로 인해 실제 서비스 상황에서는 다른 양상을 보일 수 있다.
Online에서는 유저의 데이터가 다시 log로 보내지고 일르 통해 다시 모델을 학습시키는 과정이 진행되어 모델이 계속 학습된다.
Precision ・ Recall @K
원래 Classification 문제에서 사용되는 metric이다.
Precision@K
우리가 추천한 K개 아이템 가운데 실제 유저가 관심있는 아이템의 비율
Recall@K
유저가 관심있는 전체 아이템 가운데 우리가 추천한 아이템의 비율
Mean Average Preicison(MAP) @ K
추천된 K개의 아이템의 순서에 따라서 지표 값이 달라질 수 있다.
AP@K
Precision@1부터 Precision@K까지의 평균값을 의미한다.
Precision@K와 달리 관련 아이템을 더 높은 순위에 추천할수록 점수가 상승한다.
$$ AP@K = \frac{1}{m}\sum_{i=1}^{K} Precision @i $$
MAP@K
모든 유저에 대한 Average Precision 값의 평균이다.
$$ MAP@K = \frac{1}{|U|}\sum_{u=1}^{|U|}(AP@K)_{u} $$
Normalized Discounted Cumulative Gain(NDCG)
추천 시스템에서 가장 많이 사용되는 지표 중 하나이며, 원래는 검색에서 등장한 지표이다.
Top K 리스트를 만들고 유저가 선호하는 아이템을 비교하여 값을 구한다.
MAP@K와 마찬가지로 추천의 순서에 가중치를 더 많이 두어 성능을 평가하며, 1에 가까울수록 좋다.
단, MAP@K와는 달리 연관성($rel$)이라는 개념을 이진값(0, 1)으로 하지 않고 수치로도 사용할 수 있다.
미리 유저의 아이템 별로 연관성을 수치로 구하거나 정해 놓아야 한다.
Cumulative Gain
$$ CG_K = \sum_{i=1}^{K} rel_{i} $$
상위 K개 아이템에 관하여 관련도를 합한 것이며, 순서에 따라 discount하지 않고 동일하게 더한 것이다.
Discounted Cumulative Gain(DCG)
$$ DCG = \sum_{i=1}^{K} \frac{rel_{i}}{\log_{2}{(i+1)}} $$
순서에 따라 cumulative gain을 discount한다.
Ideal DCG(IDCG)
$$ IDCG = \sum_{i=1}^{K} \frac{rel_{i}^{opt}}{\log_{2}{(i+1)}} $$
이상적인 추천이 일어났 때의 DCG 값이며, 가능한 DCG 값 중에서 가장 크다.
Normalized DCG
$$ NDCG = \frac{DCG}{IDCG} $$
추천 결과에 따라 구해진 DCG를 IDCG로 나눈 값이다.
Online (A/B) Test
추천 시스템 변경 전후의 성능을 비교하는 것이 아니라, 동시에 대조군(A)과 실험군(B)의 성능을 평가해야 한다.
대조군과 실험군의 환경은 최대한 동일해야 한다.
대부분 현업에서 모델 성능을 평가하는 최종 지표는 비즈니스 관점으로 정해진다.
인기도 기반 추천
Most Popular
조회 수, 좋아요 등이 가장 많은 아이템을 추천하는 방식이다.
특히 뉴스의 가장 중요한 속성은 최신성이므로, 기사가 언제 작성되었는지도 중요한 요소가 된다.
Hacker News Formula
$$ score = \frac{pageviews - 1}{(age + 2)^{gravity}} $$
시간이 지날수록 age가 점 증가하므로 score는 작아진다.
시간에 따라 줄어드는 score를 조정하기 위해 gravity라는 상수를 사용한다.
Reddit Formula
$$ score = \log_{10}(ups-downs) + \frac{sign(ups - downs) \cdot seconds}{45000} $$
첫번째 term은 popularity, 두번째 term은 포스팅으로 게시된 절대 시간이다.
나중(최근)에 게시된 포스팅일수록 절대시간이 크기 떄문에 더 높은 score를 가진다.
첫번째 vote에 대해서는 가장 높은 가치를 부여하며, vote가 늘어날수록 score의 증가 폭이 작아진다.
이미 인기 있는 글의 추천이 늘어날 때 부여되는 가치를 줄어들게 한다.
Highly Rated
평균 평점이 가장 높은 아이템을 추천한다.
신뢰할 수 있을 만한 평점인지, 평가의 개수가 충분한지를 고려해야 한다.
Steam Rating Formula
$$ rating_{avg} = \frac{ \text{Number of positive reviews}}{ \text{Number of reviews} } $$
$$ score = rating_{avg} - (rating_{avg} - 0.5) \cdot 2^{-\log(\text{Number of reviews})} $$
rating은 평균값을 사용하되, 전체 review 개수에 따라 rating을 보정한다.
review의 개수가 너무 적을 경우, 0.5보다 score가 낮으면 조금 높게, score가 높으면 조금 낮게 보정한다.
review의 개수가 아주 많을 경우 score는 평균 rating에 가까워진다.
Movie Rating
$$ rating_{avg} = \frac{ \sum{rating}}{ \text{Number of reviews} } $$
$$ score = rating_{avg} - (rating_{avg} - 3.0) \cdot 2^{-\log(\text{Number of reviews})} $$
영화 평점은 1.0부터 5.0의 rating을 사용하는데, 중앙값인 3.0이 아니라 모든 평점 데이터의 평균값을 보정으로 사용해도 된다.
전체 review의 개수가 많아질수록 score는 평균 rating에 가까워진다.
'AI > 추천 시스템' 카테고리의 다른 글
| Word2Vec을 응용한 Item2Vec (0) | 2022.03.13 |
|---|---|
| Bayesian Personalized Ranking(BPR) (0) | 2022.03.13 |
| 모델 기반 CF와 SVD를 응용한 MF(Matrix Factorization) (3) | 2022.03.13 |
| Collaborative Filtering(협업 필터링)기반 추천 모델 (0) | 2022.03.11 |
| 연관 분석과 TF-IDF를 활용한 콘텐츠 기반 추천 (0) | 2022.03.11 |
Contents
소중한 공감 감사합니다.