AI/AI 기본
PyTorch에서의 텐서(Tensor)와 수식 자동 미분을 위한 Autograd
- -
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
PyTorch에서의 Tensor
PyTorch의 특징 = Numpy + AutoGrad + Function

[출처] BITAmin 연합동아리 PyTorch 실습 세션에서 발표용으로 직접 제작한 자료
Tensor란?
- Pytoch의 다차원 array이며, numpy 구조를 가지는 Tensor 객체로 array를 표현한다.
- numpy의 ndarray와 유사하며, numpy ndarray와 가질 수 있는 datatype과 operation(slicing, flatten, ones_like 등)이 대부분 동일하다.
- numpy에서는 ndarray라는 list 객체를 사용하지만, PyTorch에서는 Tensor라는 객체를 사용한다.
# tensor 생성방법 1 - FloatTensor 이용
import torch
t_array = torch.FloatTensor(n_array)
print(t_array)
print("ndim :", t_array.ndim, "shape :", t_array.shape)
# tensor 생성방법 2 - list를 torch.tensor()를 사용하여 변환
data = [[3, 5],[10, 5]]
x_data = torch.tensor(data)
x_data
# tensor 생성방법 3 - numpy array를 torch.from_numpy()를 사용하여 변환
nd_array_ex = np.array(data)
tensor_array = torch.from_numpy(nd_array_ex)
tensor_array
view, transpose, reshape
기본적으로 동일하나, contiguity(데이터 저장 위치의 연속성)의 차이가 있다.
view
numpy에서 reshape와 동일하게 tensor의 shape를 변형한다.
tensor에 저장된 데이터의 물리적 위치 순서와 index 순서가 일치할 때(contiguous 할 때), shape을 재구성한다.
이 때문에 contiguous한 tensor에 관해서는 contiguous하다는 성질이 보유된다.
그러나 contiguous 하지 않은 tensor에 대해서는 shape를 재구성하지 못해서 적용할 수 없다.
transpose
tensor 에 저장된 데이터의 물리적 위치 순서와 상관없이 수학적 의미의 transpose를 수행한다.
물리적 위치와 transpose가 수행된 tensor 의 index 순서는 같다는 보장이 없으므로 항상 contiguous 하지 않다.
reshape
tensor 에 저장된 데이터의 물리적 위치 순서와 index 순서가 일치하지 않아도 shape을 재구성한 이후에 강제로 contiguous하게 만든다.
그래서 항상 contiguous하다는 성질이 보유된다.
https://inmoonlight.github.io/2021/03/03/PyTorch-view-transpose-reshape/
squeeze & unsqueeze
차원의 길이가 1인 차원을 지우거나 추가할 수 있다.
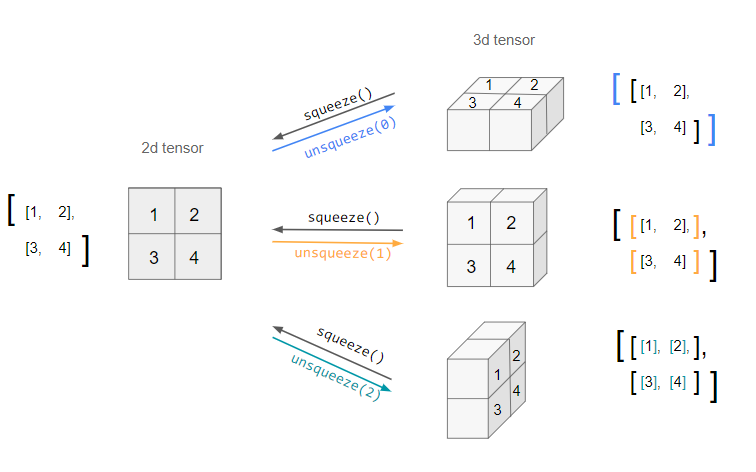
[출처] https://stackoverflow.com/questions/61598771/pytorch-squeeze-and-unsqueeze, iacob
squeeze
차원의 개수가 1인 차원을 삭제한다.
unsqueeze
차원의 개수가 1인 차원을 추가한다.
dot, mm, matmul
dot
벡터 간 내적 연산
mm
행렬 간 곱셈 연산을 수행하지만, broadcasting 하지 않는다.
matmul
행렬 간 곱셈 연산을 수행하지만, mm과는 다르게 broadcasting을 한다
여기서 broadcasting이란, 예를 들어 앞의 행렬의 차원의 개수가 3일 때, 첫 번째 dim(차원)을 batch로 간주하는 것이다.
nn.functional과 autograd
torch.nn.functional 모듈에서 softmax, argmax, one-hot encoding, cartesian product 등 다양한 수식 변환을 지원한다.
PyTorch에서는 {수식}.backward() 함수를 통해 자동 미분을 지원한다.
w = torch.tensor(2.0, requires_grad = True)
y = w**2
z = 10*y + 25
z.backward()
w.grad
# autograd 예시
a = torch.tensor([2., 3.], requires_grad=True)
b = torch.tensor([6., 4.], requires_grad=True)
Q = 3*a**3 - b**2
external_grad = torch.tensor([1., 1.])
Q.backward(gradient=external_grad)
a.grad
# tensor([36., 81.])
b.grad
# tensor([-12., -8.])
마찬가지로 torch.nn 모듈에서 가져와도 torch.nn.functional 모듈에서의 내용을 그대로 쓸 수 있는데, 이는 모델을 직접 정의해서 사용하냐 아니면 직접 호출해서 함수처럼 사용하냐의 차이로 볼 수 있다.
'AI > AI 기본' 카테고리의 다른 글
| 모델의 파라미터(Parameter)를 학습하기 위한 Loss와 Optimizer (0) | 2022.02.15 |
|---|---|
| PyTorch 프로젝트 구조와 클래스 속성 활용하기 (0) | 2022.02.15 |
| 딥 러닝에서 주로 사용하는 프레임워크(Framework) (0) | 2022.02.14 |
| RNN (Recurrent Neural Network) (0) | 2022.02.14 |
| CNN (Convolutional Neural Network) (0) | 2022.02.14 |
Contents
소중한 공감 감사합니다.