AI/AI 기본
RNN (Recurrent Neural Network)
- -
2022년 1월 17일(월)부터 21일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
RNN(Recurrent Neural Network)
RNN이란?
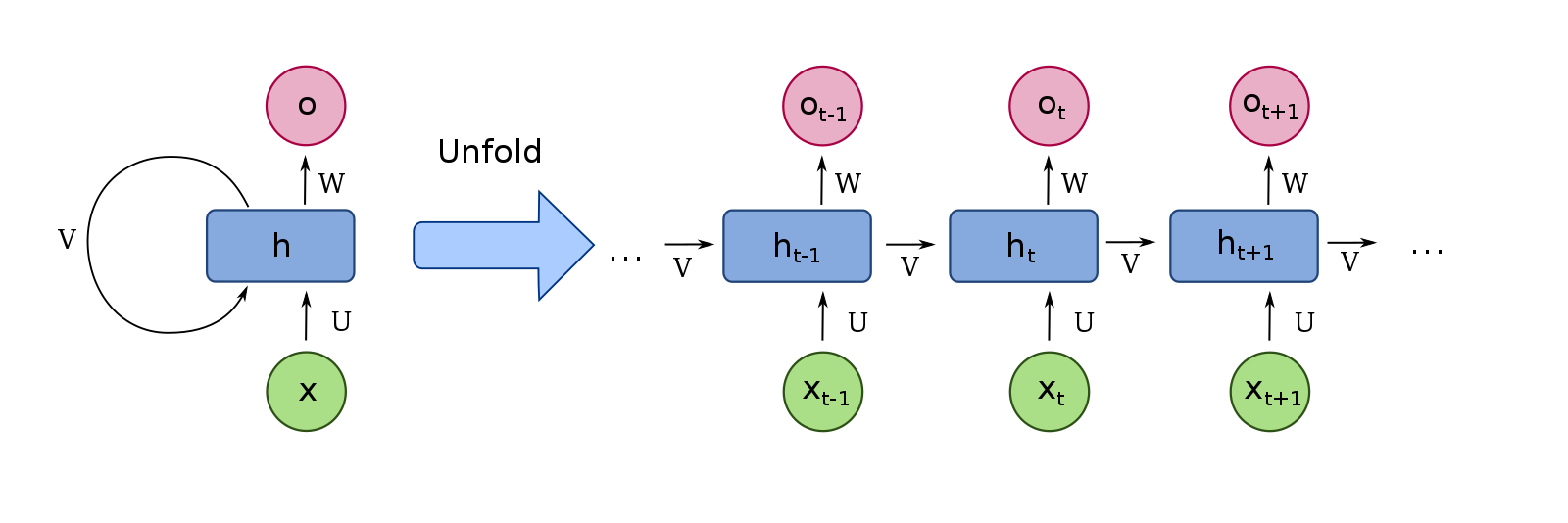
[출처] https://commons.wikimedia.org/wiki/File:Recurrent_neural_network_unfold.svg, fdeloche
시계열 데이터는 시간 순서에 따라 나열된 데이터이며, 소리, 문자열, 주가 등의 순서가 있는 시퀀스(sequence) 데이터이다.
시퀀스 데이터는 독립동등분포(i.i.d.) 가정을 위배하므로 순서를 바꾸거나 과거 정보에 손실이 발생하면 데이터의 확률분포도 바뀌게 된다.
순차적으로 들어오는 데이터를 어떻게 분석하고 반영해야 할지에 대한 고민에서 출발한 neural network이다.
조건부확률과 RNN
이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률분포를 다루기 위해 조건부확률과 베이즈 정리를 이용한다.
$$ \begin{align} P(X_1, \cdots , X_t) &= P(X_t | X_1, \cdots, X_{t-1}) P(X_1, \cdots , X_{t-1})\\ &= \prod_{s=1}^t P(X_s | X_{s-1}, \cdots, X_1) \end{align} $$
단, 주의할 점은 시퀀스 데이터를 분석할 때 항상 과거의 모든 정보가 필요한 것은 아니다.
조건부에 들어가는 데이터의 길이는 가변적이다. 그래서 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요하다.
고정된 길이만큼의 시퀀스만 사용하는 경우를 AR(Autoregressive Model) 자기회귀모델이라고 한다.
바로 직전 정보를 제외한 나머지 이전 정보들을 잠재변수 $H_t$로 인코딩해서 활용하는 방법을 잠재 AR 모델이라고 한다.
잠재변수 $H_t$를 신경망을 통해 반복해서 사용하여 시퀀스 데이터의 패턴을 학습하는 모델이 RNN이다.
RNN에서의 가중치 행렬
가장 기본적인 RNN(Recurrent Neural Network)은 MLP(Multi Layer Perceptron)와 유사한 모양이다.
잠재변수를 $\mathbf{H}$, 활성 함수를 $\sigma$, 가중치 행렬과 편향을 각각 $\mathbf{W}$, $\mathbf{b}$라고 할 때, 기본적인 RNN은 MLP와 유사한 모양이다.
$\mathbf{H = \sigma(XW + b)}$ $\mathbf{O = HW + b}$
MLP에서는 가중치 행렬 $\mathbf{W}$에 과거의 정보를 반영할 수 없었지만, RNN에서는 새로운 가중치 행렬이 등장한다.
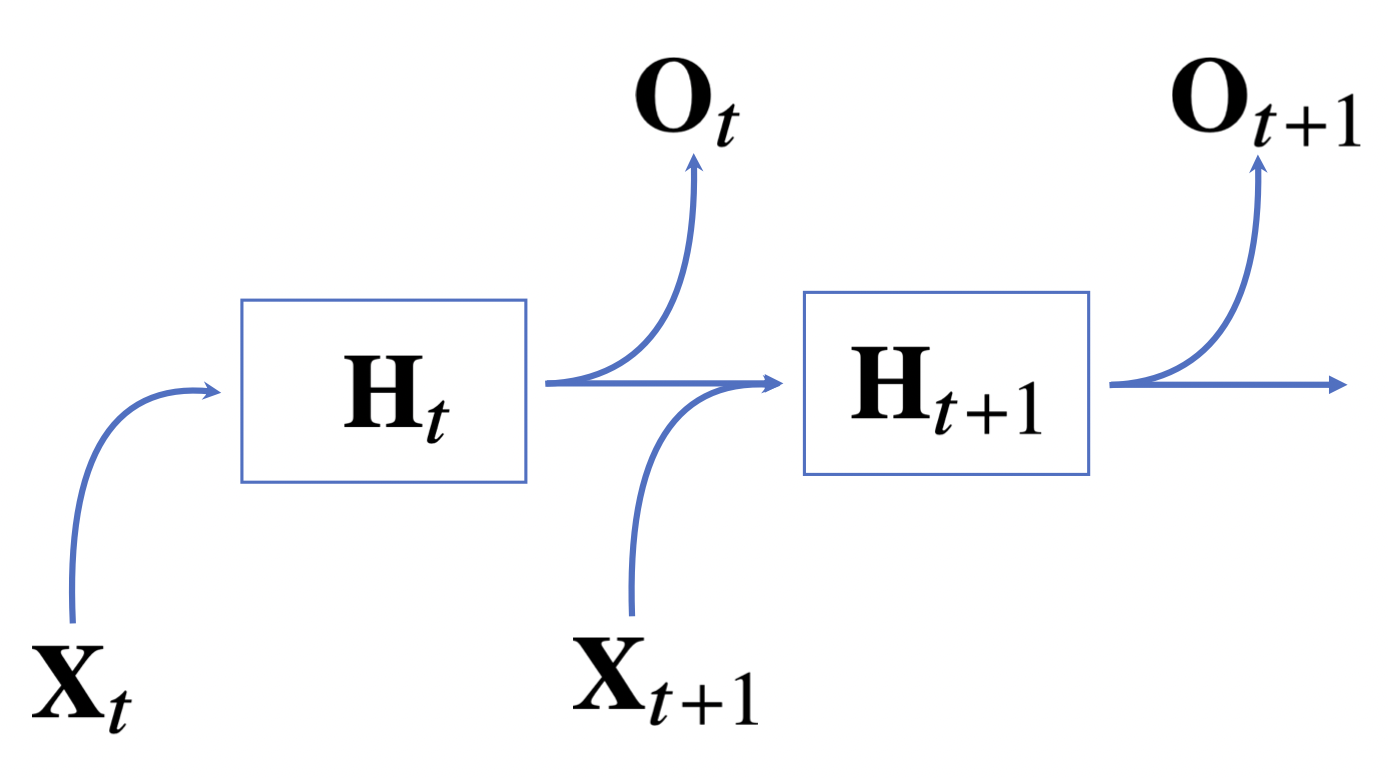
$\mathbf{W}_X$: 입력으로부터 정보를 전달받아서 현재 잠재변수 값을 반영해주는 가중치 행렬
$\mathbf{W}_H$: 이전 잠재변수로부터 정보를 전달받아서 현재 잠재변수 값을 반영해주는 새로운 가중치 행렬
$\mathbf{H}_t = o(\mathbf{X}_t \mathbf{W}_X + \mathbf{H}_{t-1} \mathbf{W}_H + \mathbf{b}) $
$\mathbf{O}_t = \mathbf{H}_t \mathbf{W} + \mathbf{b}$
$\mathbf{W}_H$와 $\mathbf{W}_X$는 T에 따라서 변하는 게 아니다.
RNN에서 hidden state와 output인 출력값 동일한가?

개인적으로 활동하고 있는 빅데이터 연합동아리 BITAmin에서 RNN을 발표할 때 다른 동아리원으로부터 받았던 질문이었다.
일부 교재 또는 참고 자료에서는 현재 cell의 output인 출력값 $\mathbf{O}_t$에 가중치 $\mathbf{W}$가 곱해지지 않고 hidden state인 $\mathbf{H}_t$와 동일하다고 설명되어 있다고 한다.
그렇지만 발표를 준비하면서 다른 참고 자료에서는 hidden state에 가중치를 곱한 선형 변환이 이루어진 것을 output으로 받는다고 서술되어 있었다.
그래서 인터넷에 찾아봐서 궁금증을 해결하려고 했다.

[출처] https://towardsdatascience.com/all-you-need-to-know-about-rnns-e514f0b00c7c
All you need to know about RNNs
A beginner’s guide into the implementation and data manipulation inside a RNN in TensorFlow
towardsdatascience.com
"To obtain the output at time step t, the hidden state (S) at time step t is multiplied by the output weight (O) at time step t and then the output bias is added to the result."
위의 자료에서는 현재 $t$ 시점의 hidden state인 $S_t$에 weight인 $O_w$가 곱해지고 bias인 $O_b$를 통과해서 $t$ 시점에서의 output이 나오는 것으로 설명되어 있다.

[출처] https://stackoverflow.com/questions/68044280/why-is-rnn-no-weigth-between-hidden-and-output
그런데 stackoverflow의 한 답변자에 의하면 PyTorch에서는 output이 hidden state에서 어떻게 만들어지는지 기술되어 있지 않아서 output을 구할 때 hidden state에 곱해지는 weight이 없다고 한다.
그래서 weight이 hidden state에 곱해져서 output을 구하는지의 여부는 아마 단순 구현 방식의 차이가 아닌가 하는 결론을 지었다.
RNN에서의 역전파 알고리즘
Backpropagation Through Time(BPTT)
RNN의 역전파는 잠재변수의 연결 그래프에 따라 순차적으로 계산한다. 이를 Backpropagation Through Time(BPTT)이라고 한다.
BPTT를 통해 RNN의 가중치행렬의 미분을 계산하면 미분의 곱으로 이루어진 항이 계산된다.
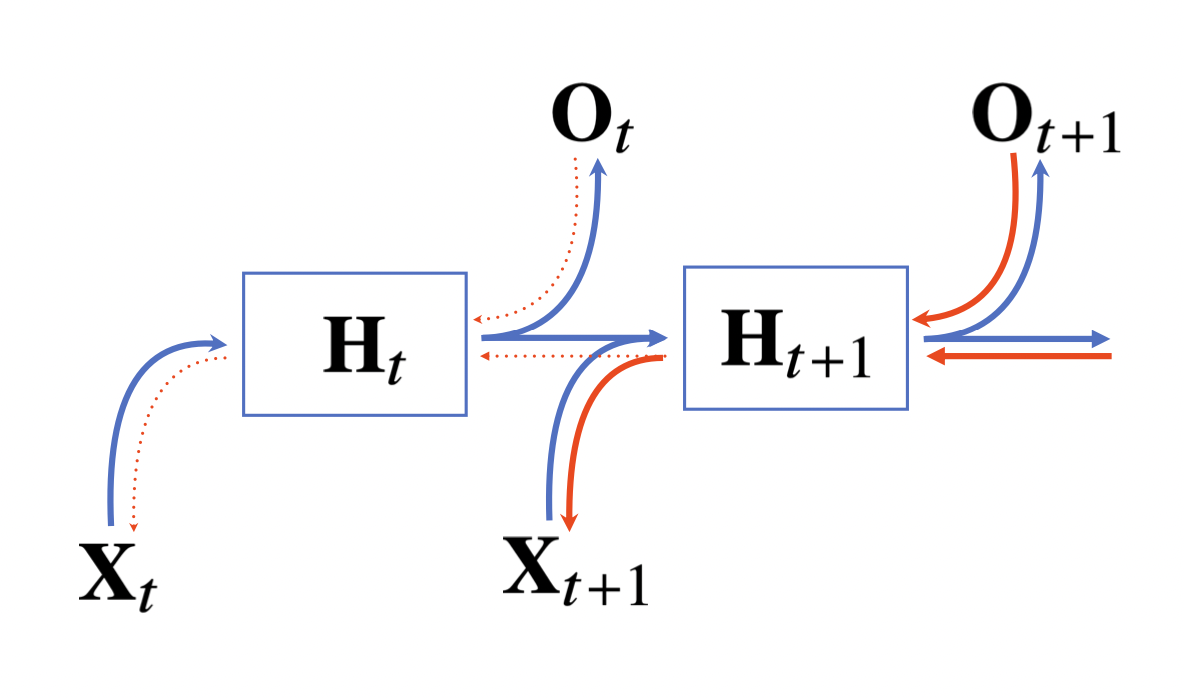
시퀀스의 길이가 길어질수록 BPTT를 통한 미분값이 너무 커지거나 작아질 수 있어 불안정해지기 쉽다.
그래서 시퀀스 길이가 길어지면 길이를 끊는 것이 필요하다. (Truncated BPTT)
Vanilla RNN은 길이가 긴 시퀀스를 처리하는 데 한계가 있어서 최근에는 LSTM(Long Short-Term Memory Model)과 GRU(Gated Recurrent Unit)라는 RNN 네트워크를 사용한다.
'AI > AI 기본' 카테고리의 다른 글
| PyTorch 프로젝트 구조와 클래스 속성 활용하기 (0) | 2022.02.15 |
|---|---|
| PyTorch에서의 텐서(Tensor)와 수식 자동 미분을 위한 Autograd (0) | 2022.02.15 |
| 딥 러닝에서 주로 사용하는 프레임워크(Framework) (0) | 2022.02.14 |
| CNN (Convolutional Neural Network) (0) | 2022.02.14 |
| 신경망(Neural Network)과 역전파 알고리즘(Backpropagation) (0) | 2022.02.14 |
Contents
소중한 공감 감사합니다.