AI/AI 기본
PyTorch에서 모델 또는 데이터를 나눠서 Multi GPU 사용하기
- -
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
Multi GPU
오늘날의 딥러닝은 엄청난 데이터와의 싸움이며, 다양한 컴퓨팅 리소스와 파워를 사용해서 모델에 데이터를 학습시켜야 한다.
그중 중요한 컴퓨팅 리소스인 GPU를 딥러닝에서 어떻게 다룰 것인가가 중요하다.
- Node: 시스템 또는 하나의 컴퓨터
- Single Node Single GPU
- Single Node Multi GPU
- Multi Node Multi GPU
필요 시 여러 GPU를 통해 학습할 수도 있으며, 이때 학습을 GPU에 분산시키는 방법에는 두 가지가 있다.
- 모델 나누기 (Model Parallel)
- 데이터 나누기 (Data Parallel)
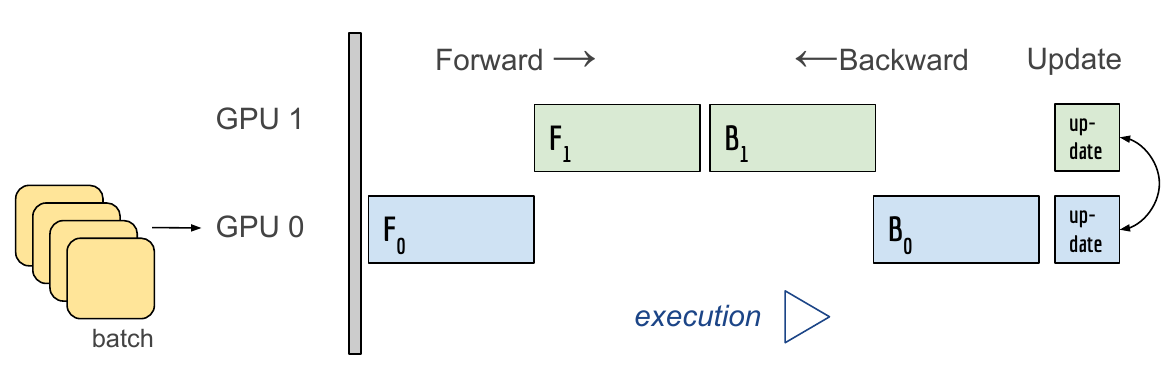
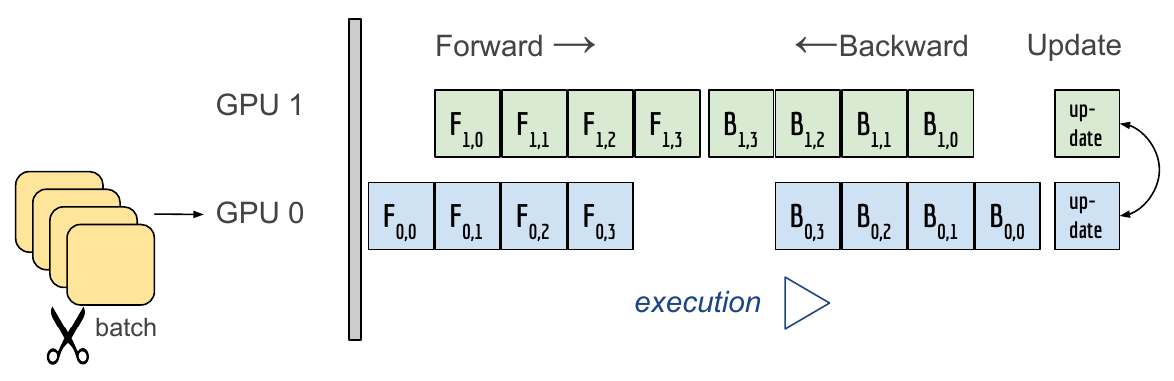
모델 나누기 (Model Parallel)
[출처] http://www.idris.fr/eng/ia/model-parallelism-pytorch-eng.html, CNRS.fr
[출처] http://www.idris.fr/eng/ia/model-parallelism-pytorch-eng.html, CNRS.fr
모델을 나누는 방법은 예전부터 쓰였다. (예: Alexnet)
하지만 모델의 병목과 파이프라인의 어려움 등으로 인해 모델 병렬화는 고난이도 과제가 되었다.
그래서 병렬적 연산이 일어나도록 파이프라인을 구조화하는 것이 핵심이다.
예시 코드
# 예시 코드
class ModelParallelResNet50(ResNet):
def __init__(self, *args, **kwargs):
super(ModelParallelResNet50, self).__init__(
Bottleneck, [3, 4, 6, 3], num_classes=num_classes, *args, **kwargs)
# 첫번째 모델을 0번째 gpu에 할당
self.seq1 = nn.Sequential(self.conv1, self.bn1, self.relu, self.maxpool, self.layer1, self.layer2).to('cuda:0')
# 두번째 모델을 1번째 gpu에 할당
self.seq2 = nn.Sequential(self.layer3, self.layer4, self.avgpool).to('cuda:1')
self.fc.to('cuda:1')
def forward(self, x):
# 두 모델 연결
x = self.seq2(self.seq1(x).to('cuda:1'))
return self.fc(x.view(x.size(0), -1))
데이터 나누기 (Data Parallel)
💥 Training Neural Nets on Larger Batches: Practical Tips for 1-GPU, Multi-GPU & Distributed setups
Training neural networks with larger batches in PyTorch: gradient accumulation, gradient checkpointing, multi-GPUs and distributed setups…
medium.com
데이터를 나눠서 GPU에 할당한 후 결과의 평균을 취하는 방법이다. mini batch 수식과 유사하며, 한번에 여러 GPU에서 데이터에 관한 연산을 수행한다.
DataParallel
- 단순히 데이터를 분배한 후 평균을 취하는 방법이다.
- GPU 사용 불균형 문제가 발생할 수 있다.
- Coordinator 역할을 하는 한 GPU(여러 GPU에서의 결과에 대한 평균치를 구하는 역할을 하는 GPU)에 결과를 모아주려면 Batch 크기가 감소하는데, 이 때 GPU에 병목 현상이 발생할 수 있어서 이를 고려해 batch size 등을 설정해야 한다.
DistributedDataParallel
- 각 CPU마다 process를 생성하여 개별 GPU에 할당하는 방법이다.
- 기본적으로 DataParallel로 실행하지만 각 GPU가 개별적으로 연산의 평균을 낸다.
예시 코드
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory = True
trainloader = torch.utils.data.DataLoader(train_data, batch_size=20,
pin_memory=pin_memory, num_workers=3, shuffle=shuffle, sampler=train_sampler)
def main():
n_gpus = torch.cuda.device_count()
torch.multiprocessing.spawn(main_worker, nprocs=n_gpus, args=(n_gpus, ))
def main_worker(gpu, n_gpus):
image_size = 224
batch_size = 512
num_worker = 8
epochs = ...
batch_size = int(batch_size / n_gpus)
num_worker = int(num_worker / n_gpus)
# CPU끼리 연산을 주고받을 때
torch.distributed.init_process_group(
backend='nccl’, init_method='tcp://127.0.0.1:2568’, world_size=n_gpus, rank=gpu)
model = MODEL
torch.cuda.set_device(gpu)
model = model.cuda(gpu)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu])
'AI > AI 기본' 카테고리의 다른 글
| PyTorch 딥 러닝 과정에서 자주 발생하는 문제 해결을 위한 팁 (0) | 2022.02.15 |
|---|---|
| PyTorch에서의 하이퍼파라미터(Hyperparameter) 튜닝 (0) | 2022.02.15 |
| PyTorch에서 자주 사용하는 학습 과정 및 결과 모니터링 Tool (0) | 2022.02.15 |
| PyTorch에서 모델 학습 과정과 검증 과정에서의 Checkpoints (0) | 2022.02.15 |
| PyTorch의 Dataset과 Dataloader (0) | 2022.02.15 |
Contents
소중한 공감 감사합니다.