AI/AI 기본
PyTorch에서 모델 학습 과정과 검증 과정에서의 Checkpoints
- -
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
PyTorch에서 Model의 학습 과정
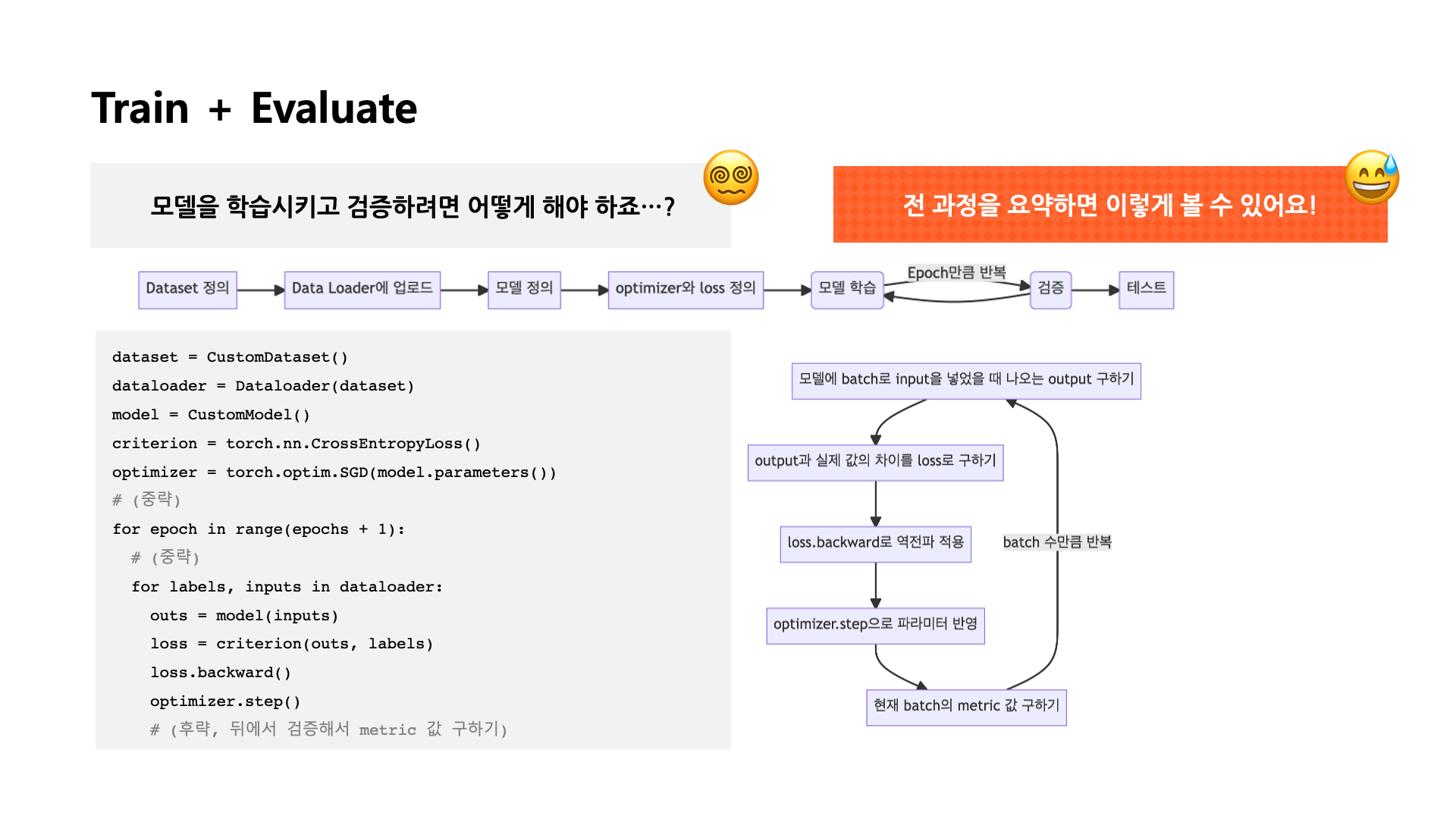
[출처] BITAmin 연합동아리 PyTorch 실습 세션에서 발표용으로 직접 제작한 자료
전반적인 모델 제작 및 학습 과정
전반적으로 PyTorch 모델을 제작하고 학습시키는 과정을 요약하면 다음과 같다.

- Dataset 정의
- DataLoader를 정의하여 Dataset을 업로드
- 학습할 Model 정의
- Loss와 Optimizer 정의
- 설정한 Epoch만큼 반복하여 모델 학습하고 검증
- 테스트 진행
모델 학습 과정 요약
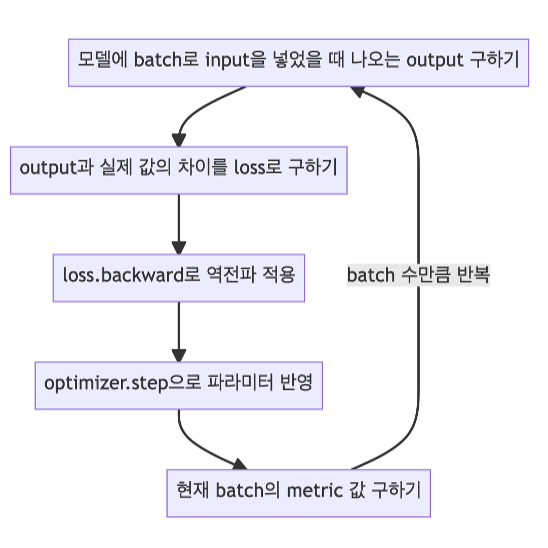
model.train()을 사용하여 모델을 학습 모드로 바꿔준다.- Optimizer의
zero_grad()함수로 optimizer에 있는 파라미터를 모두 0으로 초기화해준다. - 앞에서 제작한 커스텀 모델에 데이터의 입력을 넣어줘서 나오는 출력을 받는다.
- 위에서 정한 loss 함수로 실제 레이블과 모들이 예측한 값의 차이를 구한다.
- Loss 함수의
backward()함수로 back propagation을 진행하여 각 파라미터의 gradient를 구한다. - Optimizer의
step()함수로 4번에서 구한 gradient를 가지고 모델의 각 파라미터를 업데이트해 준다.
검증 과정에서의 유의사항
torch.no_grad() 사용하는 이유
검증 과정에서는 torch.no_grad() 함수를 써서 모델의 파라미터가 자동미분되지 않도록 해주는 것이 좋다.
그런데 어차피 loss 함수의 backward()를 실행하지 않으면 back propagation이 실행되지 않을 텐데 상관이 없지 않을까 하는 생각이 들 수 있다. 🧐
사실 주된 목적은 자동 미분을 비활성화해서 메모리 사용량을 줄이고 연산의 효율성을 높이기 위한 것이다.
컴퓨팅 리소스는 아끼면 아낄수록 좋기 때문에 검증에서 굳이 필요 없는 autograd를 꺼주는 것이다. 😆
model.eval()로 모델을 검증 모드로 바꿔주는 이유
모델이 학습 모드일 때와 검증 모드일 때 메모리 사용과 연산의 효율성이 다르다고 한다.
또한 검증 모드일 때는 Batch Normalization과 Dropout 등이 적용이 안되어서 더 공정한 검증이 가능하다.
그래서 학습 또는 검증 전에 원하는 모드로 모델을 바꿔주는 게 필요하다.
PyTorch 모델 불러오기
이미 다른 분야에서 학습된 모델을 불러와서 자신의 데이터셋에 학습시키는 것이 모델을 불러오기다.
학습 결과의 저장
colab은 runtime 연결이 끊기면 학습 결과가 모두 날아가는 불상사가 발생할 수 있으므로 학습 결과를 공유하고 싶으면 학습 결과를 저장할 필요가 있다.
학습 과정에서 모든 epoch 중 가장 측정 기준(accuracy 등)이 좋았던 시점의 모델의 파라미터 또는 모델 그 자체를 저장할 수 있다.
이는 torch.save(model, PATH)로 모델 그 자체, 또는 torch.save(model.state_dict(), PATH)로 모델의 파라미터를 저장할 수 있습니다.
여기서 저장되는 모델 또는 모델의 파라미터 파일의 확장자는 주로 .pt로 설정한다.
테스트할 때 가장 좋은 시점의 모델을 불러오는 것도 간단하다.
이때는 torch.load(PATH)로 모델 또는 모델의 파라미터를 불러올 수 있다.
모델의 파라미터를 불러와서 현재 모델의 파라미터로 업데이트하려면 model.load_state_dict(torch.load(PATH))를 실행해주면 된다.
torch.save()
학습의 결과를 저장하기 위한 함수이며, 모델의 형태(Architectur)와 파라미터(Parameter)를 저장할 수 있다.
torch.save(model.state_dict(), 경로)
# 모델의 파라미터만을 저장
torch.save(model.state_dict(), os.path.join(MODEL_PATH, "model.pt"))
# 같은 구조의 모델에 저장했던 파라미터 load
new_model = TheModelClass()
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt")))
torch.save(모델, 경로)
# 모델의 아키텍쳐까지 저장 -> 더 큰 용량을 필요로 함
torch.save(model, os.path.join(MODEL_PATH, "model.pt"))
# 저장했던 모델과 파라미터 load
model = torch.load(os.path.join(MODEL_PATH, "model.pt"))
Checkpoints
Checkpoints를 통해 모델 학습의 중간 과정을 저장하면서 최선의 결과 모델을 선택할 수 있으며, 이는 이전 학습의 결과물을 저장하는 early stopping 사용 이유와 연관이 있다.
보통 epoch, loss와 metric 값 등을 함께 저장하고 확인하며, 특히 colab은 runtime 연결이 끊길 시 학습 결과가 날라가므로 지속적인 학습을 위해서는 checkpoints를 잘 사용해야 한다.
# 모델의 정보를 epoch과 함께 저장, 파일 명에 예시처럼 핵심 정보들을 적어주는 것이 일반적이다.
torch.save({'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss,
},
f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")
# 저장한 checkpoint 불러와 확인
checkpoint = torch.load(PATH)
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']
Transfer Learning(전이 학습)
근래 DL에서의 트렌드이자 일반적인 학습 기법은 Pretrained Model로 학습하는 것인데, 이는 다른 데이터 셋으로 만든 모델을 현재 데이터에 적용하는 것이다.
즉, 특정 분야에서 학습된 neural network의 일부 능력을 새 분야에서 사용되는 neural network의 학습에 이용하는 것을 의미한다.
일반적으로 대용량 데이터 셋으로 만들어진 모델의 성능이 좋아서 이를 가져와 사용하는 게 효율적이다.
그래서 전이 학습은 학습 데이터의 수가 적을 때도 효과적이며, 학습 속도가 빠르다는 장점이 있다.
Backbone Architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행하는데, 이 Pretrained model을 활용할 때 requires_grad 속성을 사용해 일부분을 Frozen 시키기도 한다.
# vgg16 모델 불러오기
vgg = models.vgg19(pretrained = True).to(device)
# 모델의 마지막 부분에 원하는 목적에 맞게 layer를 추가한다.
class MyNewNet(nn.Module):
def __init__(self):
super(MyNewNet, self).__init__()
self.vgg19 = models.vgg19(pretrained = True)
self.linear_layers = nn.Linear(1000, 1)
# Forward Pass 정의 부분
def forward(self, x):
x = self.vgg19(x)
return self.linear_layers(x)
# 마지막에 추가한 선형 변환 layer를 제외하고 나머지 모든 파라미터에 대해 requires_grad = False를 적용함으로써 freeze한다.
my_model = MyNewNet()
for param in my_model.parameters():
param.requires_grad = False
for param in my_model.linear_layers.parameters():
param.requires_grad = True
'AI > AI 기본' 카테고리의 다른 글
| PyTorch에서 모델 또는 데이터를 나눠서 Multi GPU 사용하기 (0) | 2022.02.15 |
|---|---|
| PyTorch에서 자주 사용하는 학습 과정 및 결과 모니터링 Tool (0) | 2022.02.15 |
| PyTorch의 Dataset과 Dataloader (0) | 2022.02.15 |
| 모델의 파라미터(Parameter)를 학습하기 위한 Loss와 Optimizer (0) | 2022.02.15 |
| PyTorch 프로젝트 구조와 클래스 속성 활용하기 (0) | 2022.02.15 |
Contents
소중한 공감 감사합니다.