AI/NLP
LSTM과 GRU의 Gate별 특징과 구조 한번에 이해하기
- -
LSTM(Long Short-Term Memory)
이전 포스팅에서 LSTM에 관해 자세히 정리했는데, 여기서 좀 더 나아가서 각 gate의 특징과 그 의미를 거시적인 관점에서 이해해볼 필요가 있어 보였다.
https://glanceyes.tistory.com/entry/Deep-Learning-RNNRecurrent-Neural-Network
순차 데이터와 RNN(Recurrent Neural Network) 계열의 모델
2022년 2월 7일(월)부터 11일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거
glanceyes.tistory.com
LSTM이란?
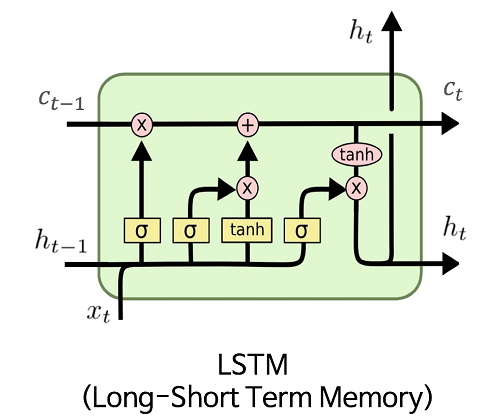
[출처] https://commons.wikimedia.org/wiki/File:LSTM.png, MingxianLin
기존의 vanilla RNN이 지니던 gradient vanishing 또는 exploding 문제를 해결하고, time step이 먼 경우에도 필요로 하는 정보를 보다 효과적으로 처리하고 학습할 수 있도록 개선한 모델이다.
매 time step마다 변화하는 hidden state vector를 단기 기억을 담당하는 기억 소자로 볼 수 있는데, time step이 진행됨에 따라 단기 기억을 보다 길게 기억하도록 개선한 모델이라는 의미에서 'Long Short-Term Memory'라는 이름을 붙였다.
LSTM의 특징
기존 vanilla RNN에서는 현재 time step에서의 hidden state를 반영할 때 해당 time step에서의 입력과 전 time step에서 오는 hidden state를 입력으로 받았다.
그러나 LSTM에서는 이전 time step에서 두 개의 서로 다른 역할을 하는 입력과 현재 time step에서의 입력을 사용한다.
$$ \left\{ C_t, h_t \right\} = \text{LSTM}\left( x_t, C_{t-1}, h_{t-1} \right) $$
$C_t$: cell state
$h_t$: hidden state
두 state의 의미를 부여하자면 cell state인 $C_t$가 전반적인 sequence에 관해 좀 더 완전한 정보를 가지고 있다고 볼 수 있고, hidden state인 $h_t$는 $C_t$를 한 번 더 가공해서 해당 time step에서 노출할 필요가 있는 정보만을 필터링해서 갖고 있다고 볼 수 있다.
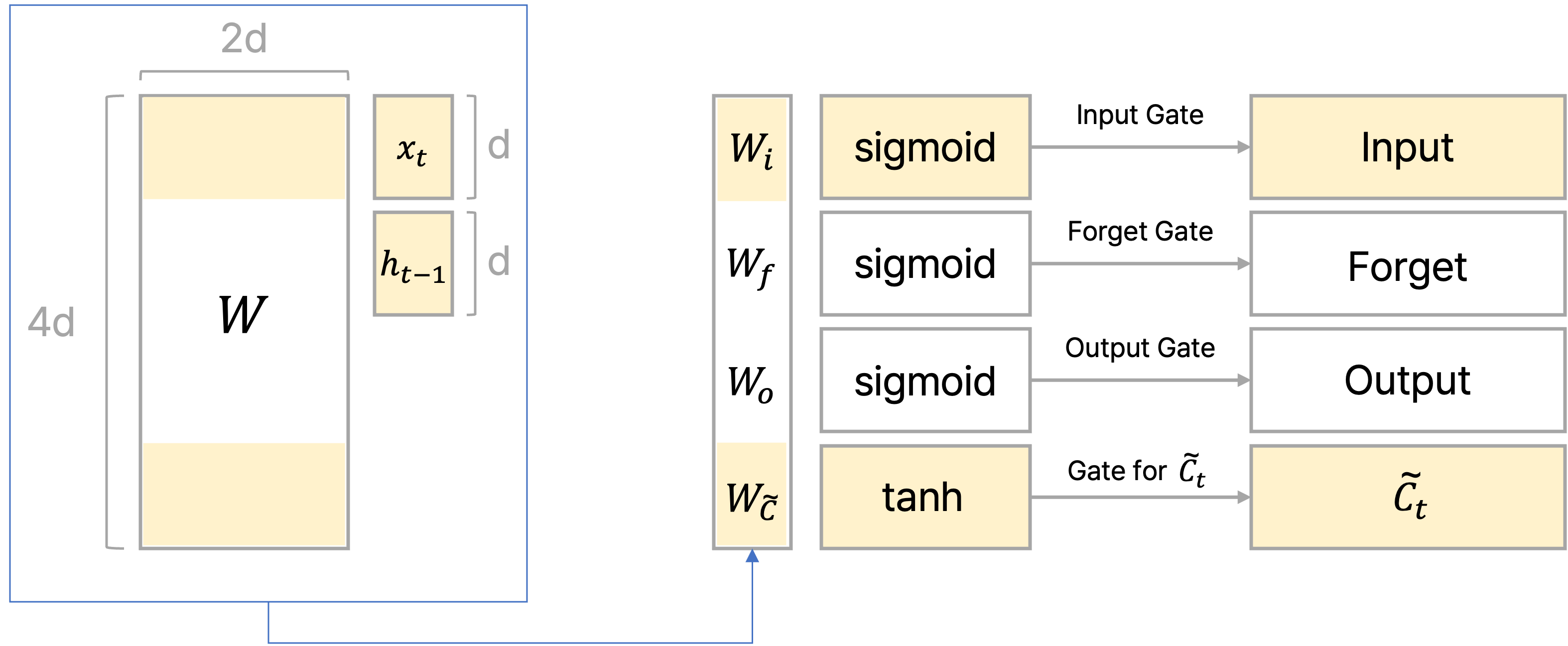
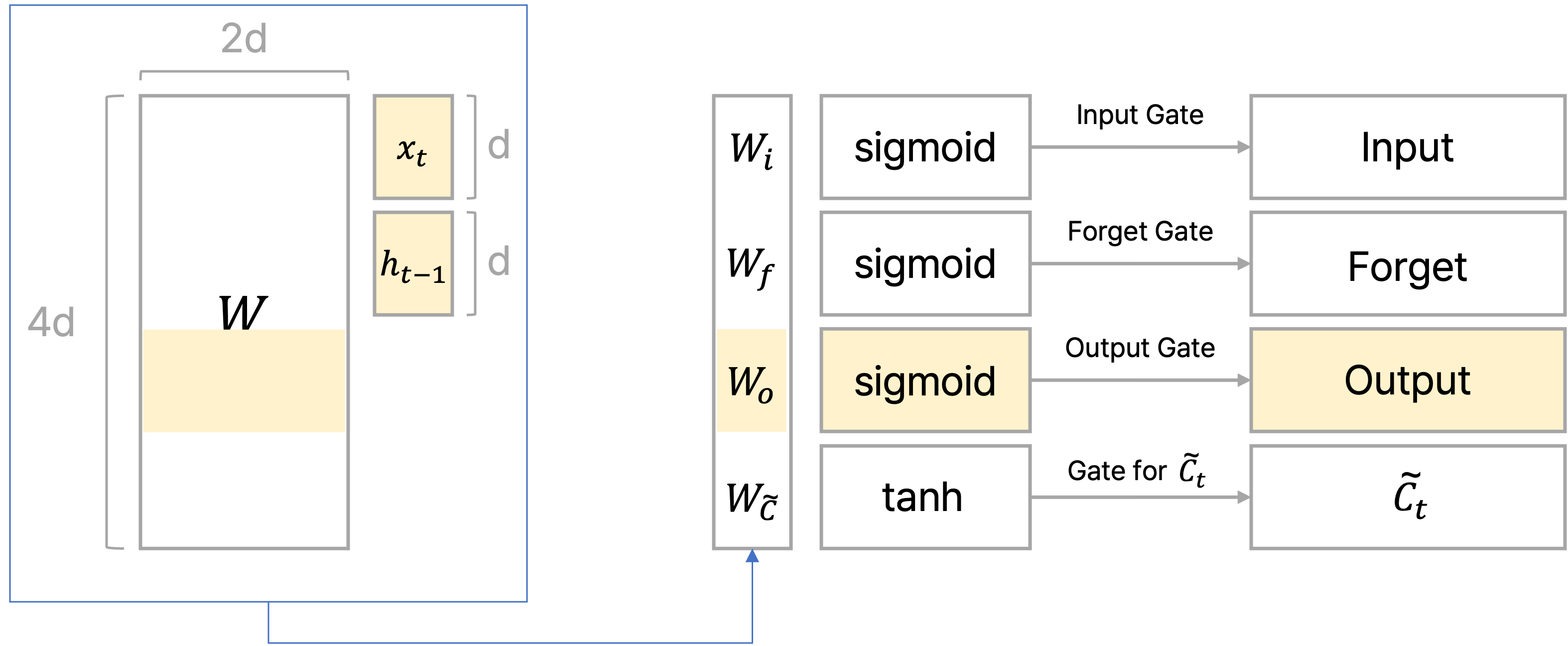
이전에 포스팅했던 글에서는 각 gate별로 state를 도출하는 식을 작성했는데, 이를 통합적으로 바라보면 결국 하나의 파라미터 matrix인 $W$를 가지고 각 gate에 해당되는 부분 행렬을 학습시키는 것으로 볼 수 있다.
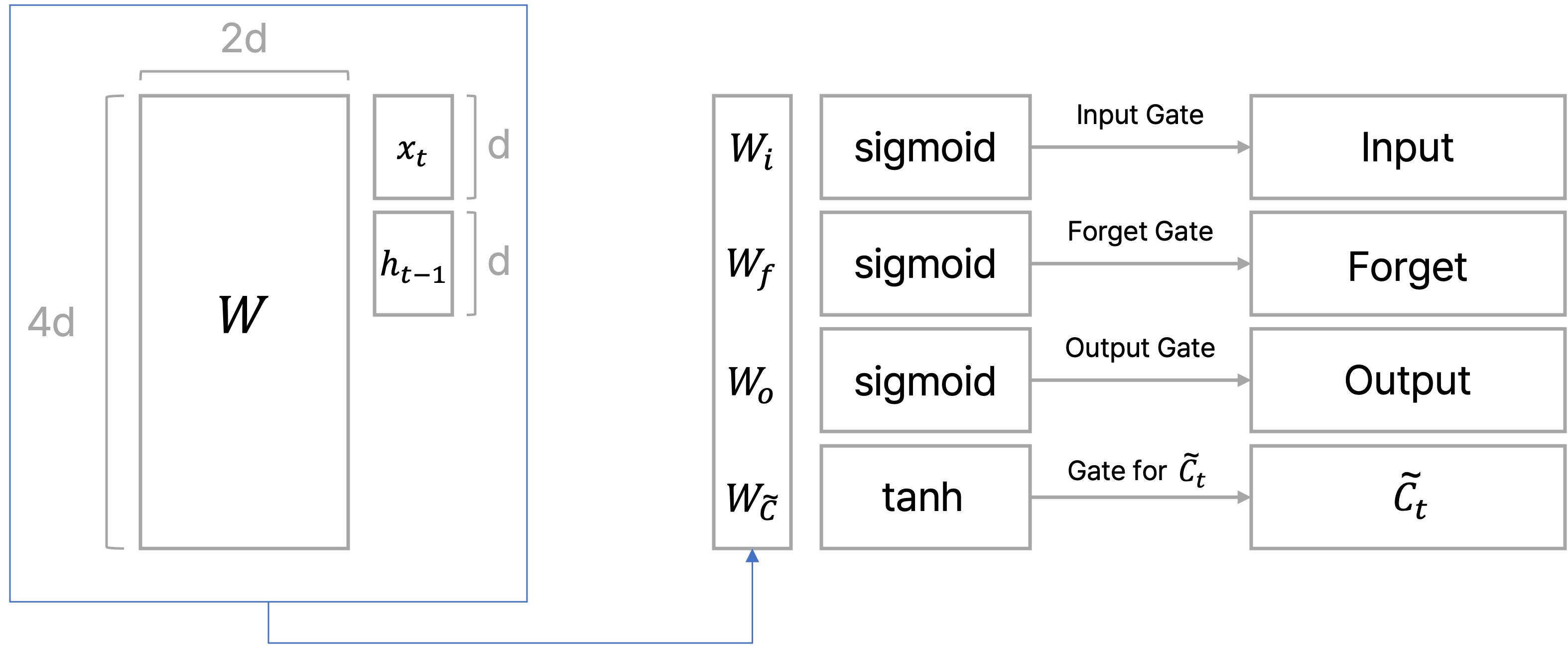
위의 그림처럼 LSTM에서 학습되는 파라미터 $W$가 존재할 때, 이를 각 gate별로 업데이트 해서 gate에서의 vector를 구하는 것으로 볼 수 있다.
Gate별 특징과 함께 후술하겠지만 $x_t$, $h_{t-1}$를 이은 벡터와 파라미터 $W$를 곱한 결과에 $\text{sigmoid}$ 또는 $\tanh$를 취한 결과를 cell state인 $C_t$ 또는 hidden state인 $h_t$와 element-wise multiplication하는데, 이는 계산 결과를 최종적으로 얼만큼의 비율로 반영해줄지를 계산하는 과정으로 볼 수 있다.
또한 $\tilde{C}_t$는 아직 $C_t$로 나오기 전의 현재 시간에서의 임시 cell state로 이해하면 된다.
예를 들어, 어떤 한 gate에서 sigmoid를 가지고 구한 벡터의 한 원소 값이 0.3이고 이와 대응되는 cell state의 원소 값이 3이면, 두 원소를 곱하는 경우 cell state의 해당 원소에서 30%만 남겨서 0.9를 만든다고 볼 수 있다.
$$ \begin{pmatrix} \text{input} \\ \text{forget} \\ \text{output} \\ \tilde{C} \end{pmatrix} = \begin{pmatrix} \sigma \\ \sigma \\ \sigma \\ \tanh \end{pmatrix} W \begin{pmatrix} h_{t-1}\\ x_t \end{pmatrix} $$
이처럼 LSTM에서의 gate는 cell state인 $C_t$에서 얼만큼의 데이터를 가지도록 할지를 조절하는 역할을 한다.
LSTM의 구조
Forget Gate
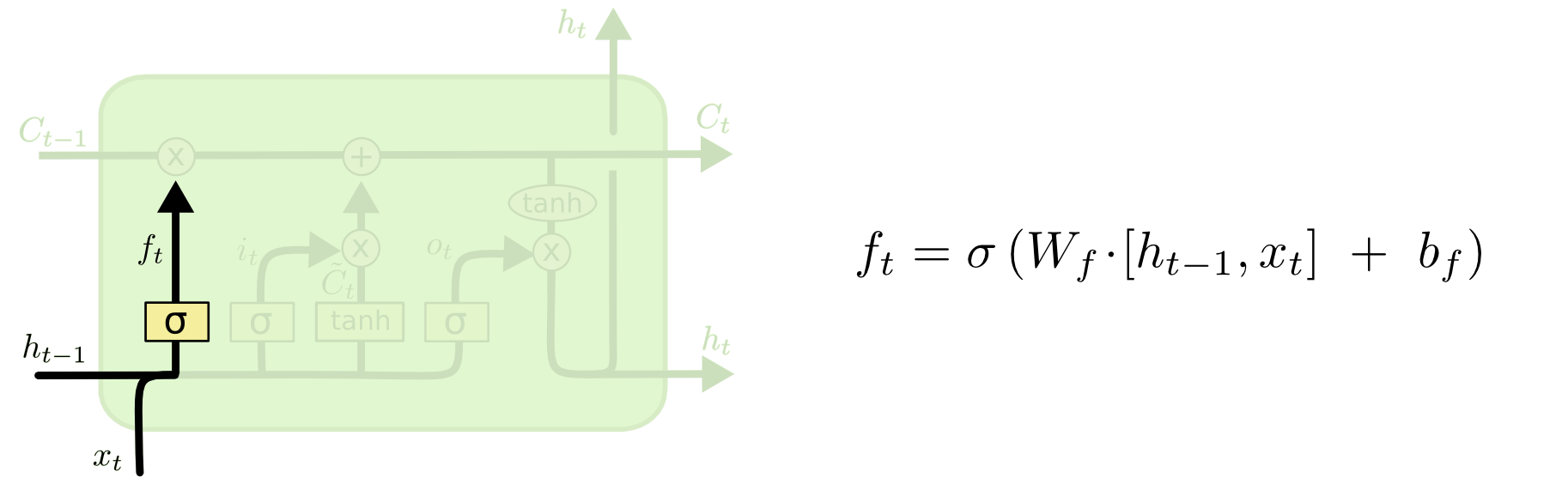
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
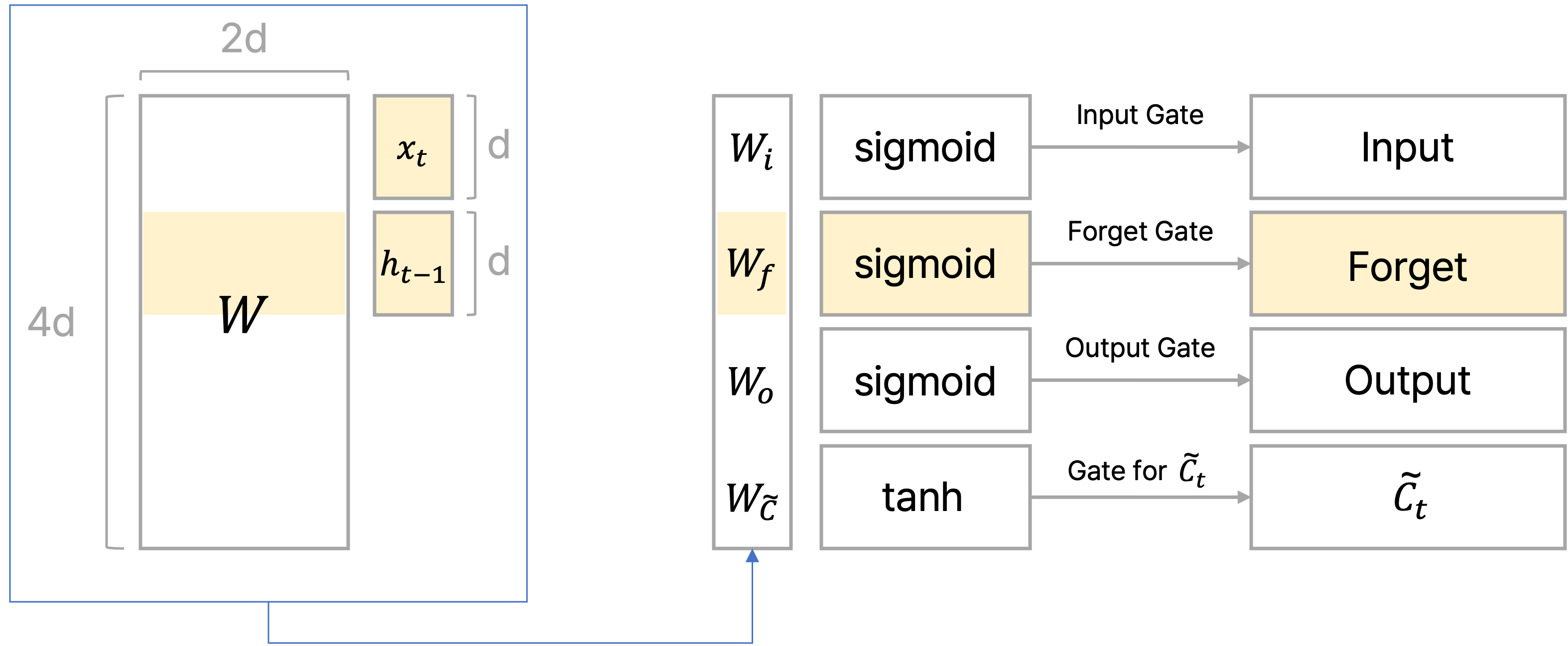
$$ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) $$
이전 hidden state와 현재 time step의 input을 가지고 이들 중에서 어떠한 정보를 버릴지를 정한다.
Forget gate를 통해 구한 결과인 $f_t$는 0과 1 사이의 값을 가질 텐데, 이를 이전 time step에서 오는 cell state인 $C_{t-1}$과 곱함으로써 cell state vector의 각 원소를 얼만큼 반영할지를 결정하는 것이다.
이때 sigmoid를 통과하고 나온 각 원소 값이 0에서 1사이의 값을 가지는 비율이므로, cell state의 원소에서 각 원소에 대응되는 비율만큼 남기고 나머지는 버리겠다는 의미에서 'Forget gate'로 볼 수 있다.
Input Gate
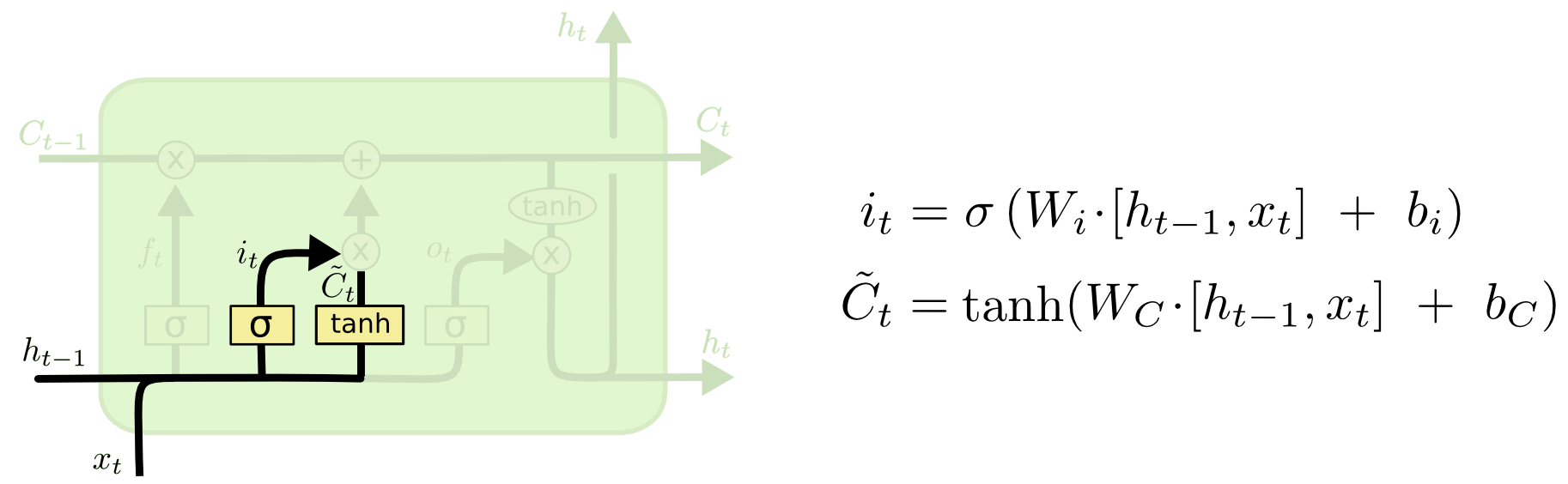
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
$$ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) $$
$$ \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) $$
이전 hidden state인 $h_{t-1}$와 현재 times step의 input인 $x_t$를 가지고 이들 중 어떤 정보를 현재 state로 저장할지를 정한다.
그래서 input gate가 위치한 영역에서는 새로운 cell state를 만들기 위한 임시 상태인 $\tilde{C}_t$와 이를 얼만큼의 비율로 반영할지를 결정하는 $i_t$를 계산한다.
참고로 이 $\tilde{C}_t$를 만들 때도 $\tanh$를 통해 입력과 파라미터를 가지고 만든 벡터의 각 원소를 얼만큼 반영할지를 반영하게 된다.
$$ C_t = f_t * C_{t-1} + i_t * \tilde{C}_t $$
Forget gate에서 구한 반영 비율 결과와 input gate 영역에서 구한 반영 비율 결과와 임시 상태인 $\tilde{C}_t$를 가고 현재 time step의 cell state를 반영한다.
Output Gate
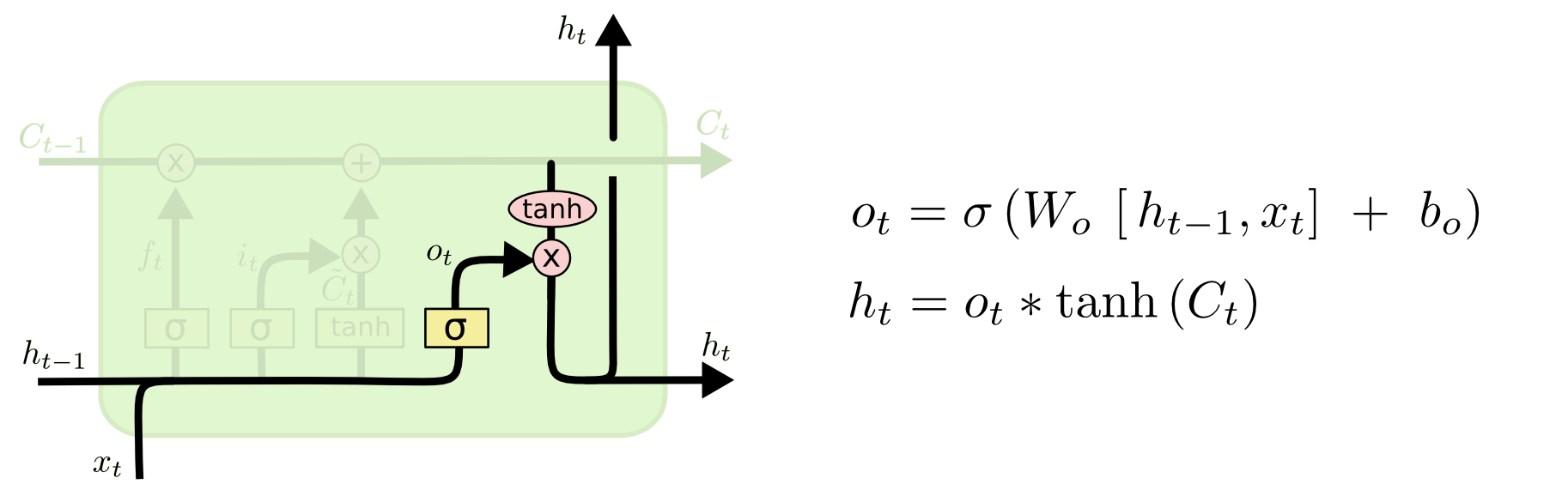
[출처] http://colah.github.io/posts/2015-08-Understanding-LSTMs
$$ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_i) $$
$$ h_t = o_t * \tanh(C_t) $$
마찬가지로 output gate에서도 이전 hidden state인 $h_{t-1}$와 현재 times step의 input인 $x_t$를 가지고 sigmoid를 통과시켜서 $C_t$에서 얼만큼의 비율을 반영할지를 계산한다.
이때, 현재 time step $t$에서의 hidden state를 계산하기 위해 $C_t$에 $\tanh$를 적용한 결과를 앞서 구한 output gate에서 구한 비율과 곱한다.
Output gate의 과정은 이제까지의 좀 더 완전하고 많은 정보를 갖고 있는 $C_t$에서 일부 정보만을 필터링하여 hidden state가 현재 time step에 직접적으로 필요한 정보만을 갖도록 하는 것으로 이해할 수 있다.
GRU(Gated Recurrent Unit)
GRU란?
LSTM의 구조를 보다 경량화해서 적은 메모리로도 빠른 계산이 가능하도록 만든 모델이다.
전체적인 동작은 LSTM과 비슷하지만, LSTM과의 가장 큰 차이점은 GRU에는 LSTM에서 입력 데이터로 사용되던 cell state와 hidden state 두 개가 아닌 이를 일원화한 hidden state만 사용한다는 것이 특징이다.
즉, GRU에서의 hidden state는 LSTM에서의 cell state와 유사한 역할을 한다고 볼 수 있다.
GRU의 구조
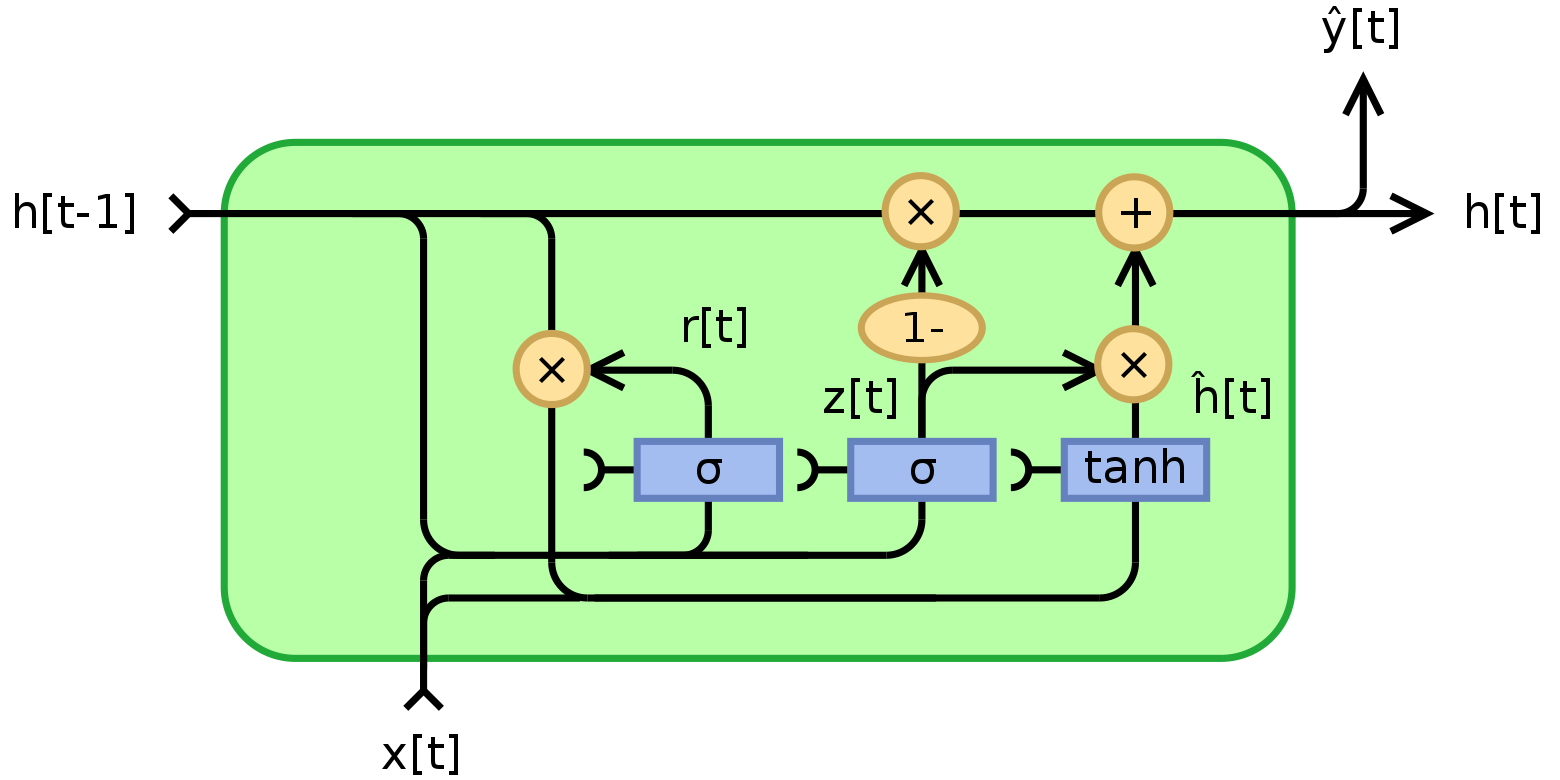
[출처] https://commons.wikimedia.org/wiki/File:Gated_Recurrent_Unit,_base_type.svg, Jeblad
$$ \begin{align} z_t &= \sigma (W_z \cdot [h_{t-1}, x_t])\\ r_t &= \sigma (W_r \cdot [h_{t-1}, x_t])\\ \tilde{h}_t &= \tanh(W_h \cdot [r_t \cdot h_{t-1} , x_t])\\ h_t &= (1 - z_t) \cdot h_{t-1} + z_t \cdot \tilde{h}_t \end{align} $$
주로 $z_t$는 update gate, $r_t$는 reset gate로 불린다.
주목해야 할 점은 현재 time step에서의 hidden state인 $h_t$를 업데이트 하는 과정이 LSTM과 닮아있다는 것이다.
$$ C_t = f_t * C_{t-1} + i_t * \tilde{C}_t $$
앞서 LSTM에서는 현재 time step의 cell state인 $C_t$를 구할 때, 이전 cell state인 $C_{t-1}$에 forget gate를 통과한 결과를 곱하고, 임시 현재 cell state인 $\tilde{C}_t$에 input gate를 통과한 결과를 곱해서 더하는 과정을 거친다.
GRU에서는 update gate의 결과인 $z_t$만 가지고 임시 hidden state인 $\tilde{h}_t$에 그대로 곱하고 이전 hidden state인 $h_{t-1}$에는 마치 forget gate를 적용하는 것처럼 $(1- z_t)$를 곱해서 이를 더하는 식을 사용하는데, 이는 $\tilde{h}_t$와 $h_{t-1}$의 가중 평균을 구하는 것으로 볼 수 있다.
LSTM에서는 input gate와 forget gate의 독립적인 두 개의 gate 결과를 가지고 cell state를 업데이트했다면, GRU에서는 하나의 gate에서 hidden state를 연산하는 것을 볼 수 있다.
이로 인해 구조적으로 GRU는 LSTM에 비해 경량화된 모델로 볼 수 있는 것이다.
LSTM과 GRU의 Backpropagation
정보를 담는 주된 벡터인 LSTM의 cell state 또는 GRU에서의 hidden state를 업데이트 되는 과정이 기존 vanilla RNN처럼 동일한 $W_{hh}$를 계속 곱하는 연산이 아니라 매 time step마다 값이 다른 forget gate를 곱하고, 필요로 하는 정보를 곱셈 뿐만이 아니라 덧셈을 통해서 만들어 낼 수 있다는 특징으로 인해 gradient vanishing 또는 exploding 문제가 많이 사라지는 것으로 알려져있다.
기본적으로 덧셈 연산은 backpropagation을 수행할 때 gradient를 복사해주는 것처럼 작동하여 멀리 있는 time step에 관해서도 gradient를 큰 변형 없이 전달해줄 수 있어서 long term dependency 문제를 해결할 수 있다.
출처
1. 네이버 커넥트재단 부스트캠프 AI Tech NLP Track 주재걸 교수님 기초 강의
'AI > NLP' 카테고리의 다른 글
| Self-supervised Model인 GPT-1과 BERT 분석 및 비교 (0) | 2022.08.01 |
|---|---|
| Beam Search와 NLP 모델의 성능을 평가하는 지표인 BLEU Score (0) | 2022.07.16 |
| RNN의 기본 개념과 자연어 처리에서의 RNN 학습 과정 (0) | 2022.07.01 |
| Bag-of-Words와 나이브 베이즈 분류 (0) | 2022.06.22 |
| NLP 분야와 이를 구성하는 다양한 태스크 (0) | 2022.06.22 |
Contents
소중한 공감 감사합니다.