AI/추천 시스템
추천 시스템의 정의와 사용하는 목적, 그리고 전통적인 분류
- -
추천 시스템의 정의
추천 시스템이란 정확히 무엇일까? 추천 시스템을 우리 일상에서 가장 쉽게 접할 수 있는 서비스의 예라고 하면 대표적으론 Netflix, Youtube, 인스타그램 등 일명 '알고리즘'에 의해 내 사용이력과 관심사에 기반하여 추천되는 서비스가 될 것이다. 그렇지만 추천 시스템을 단순히 이러한 서비스 예시로만 정의할 수는 없을 것이다. 추천 시스템을 명확히 하나의 정의만으로는 설명할 수 없지만, 대체로 위키피디아 등 유명한 자료에서는 다음과 같이 정의한다.
사용자가 아이템에 부여한 평점이나 선호도를 예측하는 일종의 정보 필터링 시스템을 뜻한다. - by Wikipedia -
사용자가 사용한 아이템에 대한 제안을 제공하는 소프트뒈어 도구나 테크닉이다.
사용자와 아이템의 상호작용을 모델링하는 기본적인 툴이다. - by PML(Personalized Machine Learning, McAuley, 2022) -
종합하자면, 일상생활에서 접하고 있는 다양한 개인화 서비스의 일종이라고 볼 수 있다.
추천 시스템의 목적
구체적으로 추천 시스템의 목적으로 아래와 같이 정리할 수 있다.
- 사용자에게 새로운 콘텐츠 제공하기
- 사용자가 좋아할 만한 콘텐츠 제공하기
- 사용자에게 개인화된 경험 제공하기
요약하면, 사용자의 선호를 모델링하고 이를 통해 비즈니스 목표를 달성하는 것이 추천 시스템의 목적이다.
기존 머신러닝 방법론과의 차이
사용자 로그 데이터를 바탕으로 사용자 별로 좋아할 만한 아이템을 추천하는데, 이를 전통적인 지도학습의 한 형태인 Linear Regression 형태의 predictor로 만든다고 가정한다.
$$ \begin{align} \text{rating(user, item)}\\ = f(\text{user, item})\\ = W^{(u)} \phi^{u} (u) + W^{(i)} \phi^{(i)}(i) \end{align} $$
사용자와 아이템 term을 포함하고 있고, 각각의 알맞은 weight가 곱해지는 형태로 표현된다.
사용자의 아이템에 대한 score를 계산하는 데 활용하면 아래와 같이 각각의 사용자에 관해 해당 사용자가 접하지 않은 아이템 중 가장 score가 높은 것을 보여준다.
$$ \underset{i \in \text{unseen items}}{\text{arg max}} f(\text{user}, \text{item}) = \underset{i \in \text{unseen items}}{\text{arg max}} W^{(i)} \phi^{(i)}(i) $$
그러나 여기서 아이템에 관한 랭킹만 구하기 때문에 사용자 term은 필요하지 않고 아이템 term만 남게 된다.
그래서 사용자와 관련된 변수가 필요가 없어서 모든 사용자들에게 동일한 내용을 보여주는 비개인화 추천 시스템이 되어 버린다.
물론 사용자와 아이템 간의 상호작용을 고려하여 머신러닝 모델을 설계할 수도 있지만, 유저와 아이템 수가 워낙 많은 경우가 대부분이어서 모든 조합의 경우를 고려하는 것은 비효율적이다.
또한 어떤 도메인에서 어떠한 feature가 효과적인지 미리 알 수 없으며, feature가 존재하지 않을 수 있다.
그래서 추천 시스템 방법론은 이러한 시나리오에서 개인화된 예측을 위한 근본적인 방법이다.
즉, 추천 시스템에서는 사용자와 아이템 간의 관계를 명시적으로 모델링하는 것이다.
$$ \text{compatibility} = f(u, i) $$
CV와 NLP에서는 이미지, 텍스트라는 단일 entity를 다루지만, 추천 시스템에서는 (사용자, 이미지) 또는 (사용자, 텍스트)로 주어지는 각 조합의 상호작용을 모델링한다.
더 나아가서 사용자와 아이템의 조합 뿐만이 아니라 사용자의 위치와 아이템과의 상호작용이 이루어지는 시간 등 다른 요인도 함께 고려할 수도 있다.
다양한 complatibility function의 형태
- Matrix Factorization(MF): 사용자, 아이템 벡터 등 dense vectors를 내적하는 연산
- Memory-based Collaborative Filtering(CF): one-hot vector로 Cosine, Pearson, Jaccard 유사도를 구하는 형태
- Neural CF: concatenation을 활용하여 MLP 모델링을 하는 방법
- Collaborative Metric Learning: Euclidean distance 구하기
- Latent Cross: element-wise product 연산
대부분의 추천 시스템 연구 및 방법론은 크게 사용자와 아이템을 어떻게 잘 표현할지와 어떠한 형태의 compatibility function을 사용할지인 두 가지 관점을 고려한다.
사용자와 아이템 상호작용 데이터 표현 방법
다음과 같은 사용자, 아이템, 평점, 시간에 관한 데이터가 있다고 가정한다.
| USER_ID | ITEM_ID | RATING | TIMESTAMP |
|---|---|---|---|
| 243 | 2904 | 5 | 1546559725 |
| 243 | 23985 | 3 | 1546560911 |
| 65 | 235 | 3 | 1546589911 |
| 124 | 54 | 2 | 1546588801 |
Set을 사용하는 방법
$I_u$ = 사용자 $u$에 의해 소비된 아이템 set
$U_i$ = 아이템 $i$를 소비한 사용자 set
Set을 사용한 상호작용 데이터의 표현은 item-to-item이나 user-to-user similarity를 계산하거나 추천 시스템의 성능을 평가할 때 유용하다.
Matrix를 사용하는 방법
상호작용을 나타내는 행렬 $C$와 평점을 나타내는 행렬 $R$을 만든다면 다음과 같이 정리할 수 있다.
$$ R = \begin{bmatrix} 5 & \cdot & \cdot & 2 & 3 \\ \cdot & 4 & 1 & \cdot & \cdot \\ \cdot & 5 & 5 & 3 & \cdot \\ 5 & \cdot & 4 & \cdot & 4 \\ 1 & 1 & \cdot & 4 & 5 \\ \end{bmatrix} \qquad C = \begin{bmatrix} 1 & \cdot & \cdot & 1 & 1 \\ \cdot & 1 & 1 & \cdot & \cdot \\ \cdot & 1 & 1 & 1 & \cdot \\ 1 & \cdot & 1 & \cdot & 1\\ 1 & 1 & \cdot & 1 & 1 \\ \end{bmatrix} $$
$R_u$: 사용자 $u$가 평가한 아이템의 평점을 하나의 행으로 나타내는 것이다.
$R_{., i}$: 아이템 $i$를 소비한 사용자를 하나의 열로 표현하는 것이다.
Set 표현과의 연관성을 나타낼 수도 있다.
$I_u = \left\{i | R_{u, i} \neq 0 \right\}$
$U_i = \left\{u | R_{u, i} \neq 0 \right\}$
아이템과 사용자의 상호작용 이력을 갖고 있는 행렬을 기반으로 하는 추천 시스템에서는 SVD(Singular Value Decomposition) 등 선형대수학의 개념을 사용하는 경우가 많다.
추천 시스템 방법론의 전통적인 분류
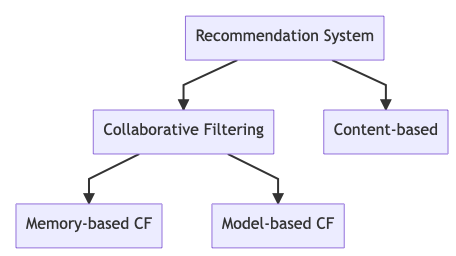
추천 시스템은 그것이 사용하는 데이터의 형태에 따라 크게 CF(Collaborative Filtering)와 CB(Content-based) 방법으로 구분될 수 있다.
CF는 사용자와 아이템의 상호작용 이력을 나타내는 데이터 행렬을 사용하는 것이고, CB는 사용자와 아이템의 상호작용 뿐만이 아니라 사용자, 아이템의 여러 부가적인 속성들을 활용하는 것이다.
특히 CF는 전통적인 Memory 기반과 Model 기반의 방법으로 구분될 수 있는데, Memory 기반을 Neighborhood 기반 방법이라고도 한다.
Memory 기반은 유사도가 높은 이웃 기반의 대표적인 Amazon.com 추천 시스템이, Model 기반은 latent factor를 사용하는 MF(Matrix Factorization) 모델이 해당된다.
위의 내용을 전통적인 분류라고 한 이유는, 최근에 연구되는 그래프를 활용하는 방법이나 순차적인 데이터를 활용하는 방법론은 전통적인 분류 체계로 나누기에 모호하기 때문이다.
출처
1. 네이버 부스트캠프 AI Tech 추천 시스템 Stage 2 강의
'AI > 추천 시스템' 카테고리의 다른 글
| 추천 시스템의 핵심이 되는 여러 방법론 (0) | 2022.03.27 |
|---|---|
| 딥 러닝(Deep Learning) 기반의 추천 시스템 (0) | 2022.03.27 |
| MAB(Multi-Armed-Bandit)를 활용한 Thompson Sampling과 LinUCB(Linear Upper Confidence Bound) (0) | 2022.03.19 |
| 추천 시스템과 Multi-Armed Bandit(MAB) 알고리즘 (0) | 2022.03.19 |
| User Behavior Feature를 활용하는 DIN(Deep Interest Network)과 BST(Behavior Sequence Transformer) (0) | 2022.03.19 |
Contents
소중한 공감 감사합니다.