AI/AI 기본
딥 러닝에서 알아두어야 할 요소와 역사적으로 중요한 모델
- -
Deep Learning에서 중요한 요소
- The data that the model can learn from
- The model how to transform the data
- The loss function that quantifies the badness of the model
- The algorithm to adjust the parameters to minimize the loss
Data
데이터는 해결해야 할 문제에 의존적이다.
- Classification
- 이미지에 대한 label 찾기
- 예) 개·고양이 분류 문제
- Sementic Segmentation
- 픽셀이 어떠한 개체에 속하는지를 분류
- 이미지 내 요소 구분 문제
- Detection
- 이미지에서 개체에 대한 bounding box 찾기
- 사물 감지 문제
- Pose Estimination
- 2차원 또는 3차원 skeleton 데이터
- 생물의 자세 추측 문제
- Visual QnA
- 이미지에 대한 질문이 주어졌을 때 그에 대한 답 구하기
딥러닝에서 필요한 각각의 요소에 관한 자세한 설명은 아래 링크를 참조하면 된다.
https://glanceyes.tistory.com/entry/PyTorch-AutoGrad-Optimizer
모델의 파라미터(Parameter)를 학습하기 위한 Loss와 Optimizer
2022년 1월 24일(월)부터 28일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거
glanceyes.com
Model

[출처] BITAmin 연합동아리 PyTorch 실습 세션에서 발표용으로 직접 제작한 자료
- 딥러닝을 구성하는 Layer의 Base Class이다.
- Input, Output, Forward, Backward에 해야할 일을 정의한다.
- 학습의 대상이 되는 Parameter(tensor)를 정의한다.
AlexNet, ResNet, DenseNet, LSTM 등이 해당된다.
모델에 따라 좋은 성능이 나올 수 있고 아닐 수도 있다.
Loss

Neural Network에서는 각 레이어마다 존재하는 weight와 bias 등 파라미터를 어떻게 업데이트 해 나갈지에 관해 그 기준을 정하는 것이다.
즉, 실제 값과 모델이 예측한 값의 차이를 어떠한 식으로 정의할지를 결정하는 것이다.
Regression Task
Mean Squared Error
$$ MSE = \frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{D}(y_i^{(d)}- \hat{y_i}^{(d)})^2 $$
Classification Task
Cross Entropy
$$ CE = -\frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{D}y_i^{(d)}\log{\hat{y_i}^{(d)}} $$
Probabilistic Task
Maximum Likelihood Estimation
$$ MLE = \frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{D}\log{\mathcal{N}(y_i^{(d)};\hat{(y_i)}^{(d)},1)} $$
단순히 Loss Function의 값이 줄어든다고 해서 우리가 원하는 것을 항상 이룬다고 보장할 수 없으므로, Loss Function은 이루고자 하는 것의 근사치에 불과하다는 점을 유의해야 한다.
예를 들어, 회귀문제에서 noise가 많이 있을 때 outlier가 존재하므로 MSE보다는 다른 Loss Function을 사용하는 것이 바람직할 수 있다.
즉, loss가 줄어든다고 무조건 문제를 푸는 것이 아닐 수 있으며, 특정 loss를 왜 사용하는지에 관해 이해하는 것이 필요하다.
Optimization Algorithm
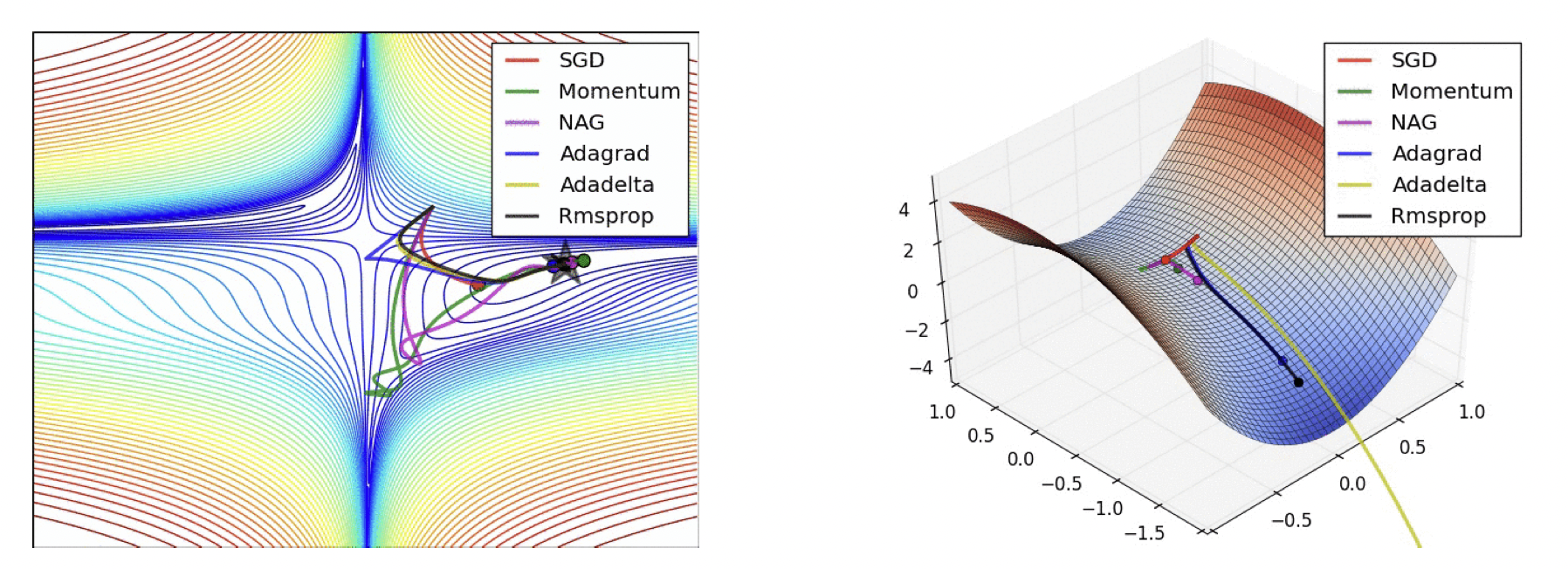
[출처] https://arxiv.org/pdf/1609.04747.pdf, An overview of gradient descent optimization algorithms
최적화를 위해 사용하는 알고리즘이며, 역전파 알고리즘(Backpropagation)을 한 후 나온 gradient를 가지고 모델의 parameter를 어떻게 업데이트할지에 관한 방식을 결정하는 것이다.
SGD, Momentum, NAG, Adagrad, Adadelta, Rmsprop 등이 있다.
Dropout, Early stopping, k-fold validation, Weight decay, Batch normalization, MixUp, Ensemble, Bayesian Optimization 등 다양한 테크닉을 같이 사용해볼 수 있다.
딥러닝 모델의 Historical Review
2012 - AlexNet
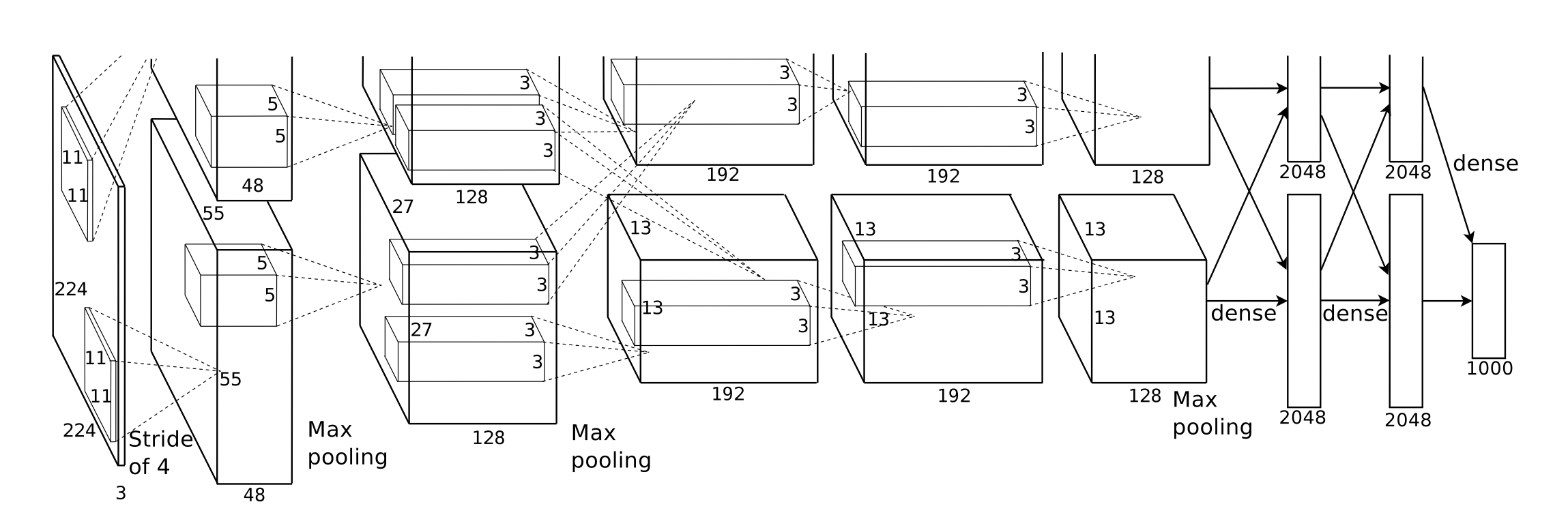
[출처] https://papers.nips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf, ImageNet Classification with Deep Convolutional Neural Networks
ImageNet 대회에서 처음으로 우승한 딥러닝 모델이며, $224 \times 224$ 크기의 RGB 이미지가 입력되었을 때 이를 알맞게 분류한다.
이전에는 Suppor Vector Machine 등을 사용했지만, AlexNet이 등장하고 Paradigm Shift가 일어났다.
ReLU 활성함수, Dropout 사용, Local Response Normalization, Data Augmentation, Multi GPU 사용, Stride를 좁혀서 overlapping하여 convolution 연산 진행 등 주목할 만한 특징이 있다.
딥러닝이 실제로 성능을 발휘한 시작점이라 의미가 있다.
2013 - DQN(Deep Q Network)

[출처] https://www.cs.toronto.edu/~vmnih/docs/dqn.pdf, Playing Atari with Deep Reinforcement Learning
AlphaGo를 제작한 Google Deep Mind가 만든 아케이드 게임을 플레이하는 딥러닝 모델이다.
Q-learning을 활용한 방식을 사용했는데, Q-learning은 강화학습을 통해 어떤 상태에서 어떠한 행동을 취하는 것이 가장 큰 보상을 받을 수 있는지를 학습할 때 사용하는 함수이다.
이제까지 방법으로는 Q를 정확히 학습시키는 것이 어려웠지만, 이를 Deep Neural Network로 구성하여 해결한 아이디어이다.
또한 RMSProp Optimizer로 Parameter를 업데이트했다는 점도 주목할 만하다.
2014 - Encoder와 Decoder
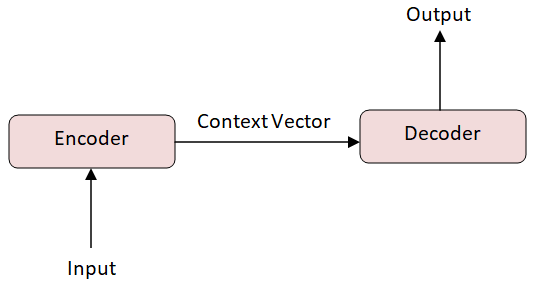
[출처] https://commons.wikimedia.org/wiki/File:Basic_Encoder-Decoder_Architecture.png, Medhabarve
기계어 트랜드 변화를 주도한 논문이며, NMT(Neural Machine Translation)을 해결하기 위한 모델이다.
단어의 연속으로 이루어진 문장을 vector로 인코딩하고, 인코딩된 vector를 다른 언어의 단어의 연속으로 디코딩한다.
2014 - Adam(Adaptive Momentum) Optimizer
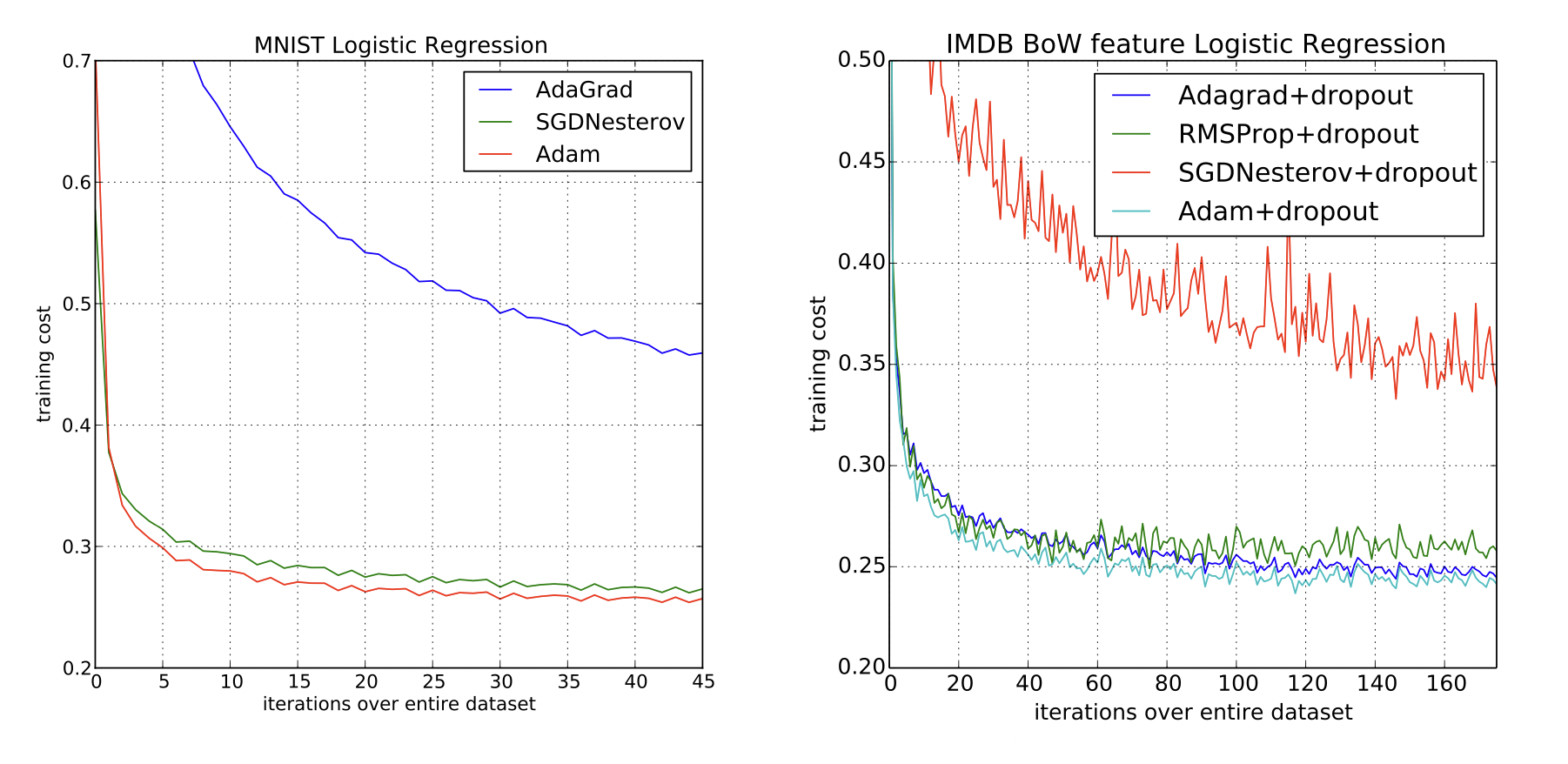
[출처] https://arxiv.org/pdf/1412.6980.pdf, ADAM: A METHOD FOR STOCHASTIC OPTIMIZATION
Adam Optimizer는 RMSProp와 Momentum의 장점을 모두 반영한 것이며, step의 방향과 크기를 적절히 조정하기 위한 알고리즘이다.
보통 이유를 잘 모른 채 Adam Optimizer를 사용하는 경우가 많은데, 이는 Adam Optimizer을 사용했을 때의 결과가 좋다고 알려져 있기 때문이다.
다양한 hyperparameter tuning에 따라 모델의 성능이 달라지기도 하지만, 이는 많은 컴퓨팅 자원을 사용할 수밖에 없다.
그래서 컴퓨팅 자원 사용에 제약이 있는 사람들이 Adam Optimizer를 사용하면 웬만하면 좋은 결과를 보장해준다고 한다.
2015 - Generative Adversarial Network

[출처] https://arxiv.org/pdf/1406.2661.pdf, Generative Adversarial Networks
네트워크를 Generator와 Discriminator 두 개로 만들어서 학습하는 모델이다.
자세한 내용은 여기에 정리된 것을 참고하면 된다.
https://glanceyes.tistory.com/entry/Deep-Learning-Generative-Model?category=1050635
생성 모델(Generative Model)과 VAE 그리고 GAN
Generative Model Generative Model이란? Discriminative Model과 Generative Model 일반적으로 머신러닝에서 모델을 크게 두 범주로 분류하자면 discriminative model과 generative model로 구분할 수 있다. Discriminative model은
glanceyes.com
2015 - ResNet(Residual Networks)
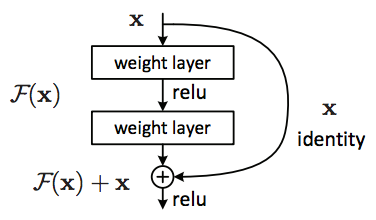
[출처] https://commons.wikimedia.org/wiki/File:Resnet.png, Xiaozhu0429
Neural Network를 너무 깊게 쌓으면 testing error에 있어서 좋지 않은 결과가 나온다고 알려져 있었지만, Residual Networks가 등장한 이후로는 Neural Network를 어느 정도 깊게 쌓아도 test error가 낮은 괜찮을 결과를 가질 수 있도록 한 모델이다.
Gradient Vanishing 또는 Exploding 문제를 해결하기 위한 방법이며, 앞에서 입력한 input을 몇 개의 layer 이후의 출력값에 더해주는 skip connection을 만들어준다.
2017 - Transformer
"Attention Is All You Need" 논문에서 발표된 모델이다.
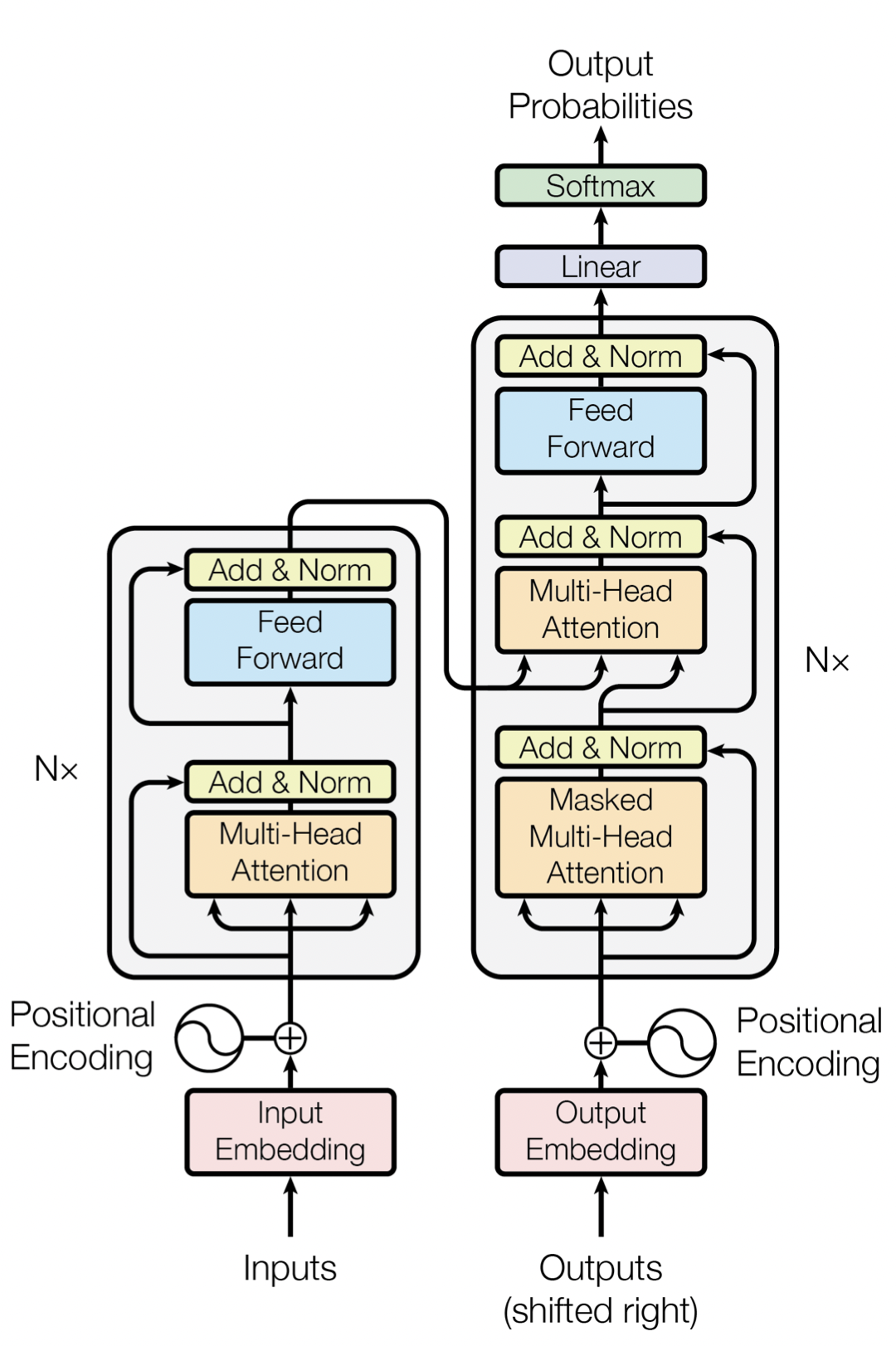
[출처] https://arxiv.org/pdf/1706.03762.pdf, Attention is All You Need
Google에서 도발적인 제목으로 발표한 논문의 핵심 내용이다.
Multi-Head Attention을 활용해 기존 NLP 모델의 단점을 극복하는 방법이다.
현재는 NLP 외에 다른 분야에서도 활용되고 있다.
자세한 내용은 여기를 참고하면 된다.
https://glanceyes.tistory.com/entry/Deep-Learning-Transformer
Self-Attention을 사용하는 Transformer(트랜스포머)
Sequential Model Sequential Model이 어려운 이유 언어 문장을 예로 들면 완벽한 문장 구조에 대응되도록 문장을 만드는 경우는 흔치 않은데, 이러한 문제는 sequential model에 있어서 난관이다. 또한 기존 Se
glanceyes.com
2018 - BERT (fine tuned NLP models)
Bidirectional Encoder Representations from Tansformers
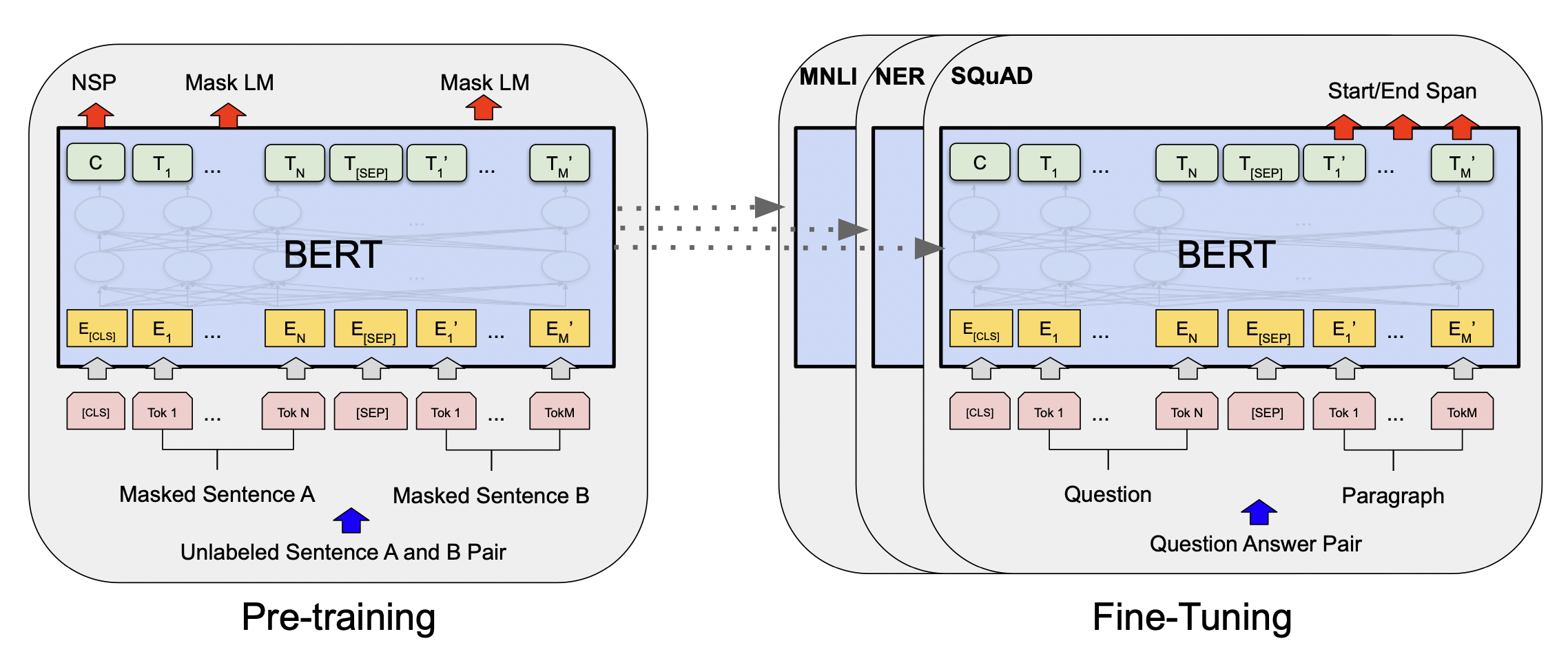
[출처] https://arxiv.org/pdf/1810.04805.pdf, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
자연어 처리 문제는 이전에 단어들이 주어졌을 때 다음 단어가 무엇이 나올지를 예측하는 Language 모델을 학습시킨다.
그렇지만 Fine Tuned NLP Models는 다양하고 일반적인 데이터를 활용하여 큰 말뭉치를 pre-training을 하고, 진정으로 해결하고자 하는 문제에 적용시키는 Fine-Tuning을 진행한다.
2019 - BIG Language Models (GPT-X)
https://openai.com/blog/openai-api/
수많은 파라미터를 활용한 autoregressive language model을 제시한 논문이다.
openAI사가 만든 GPT-X를 사용하여 다양한 Fine Tuning을 통해서 여러 Sequential Model을 만들 수 있다.
Parameter의 수가 굉장히 많다는 것이 특징인데, GPT-3만 해도 1,750억 개의 매개변수를 지니고 있다고 알려져 있다.
2020 - Self Supervised Learning
SimCLR = A Simple Framework for Contrastive Learning of Visual Representations
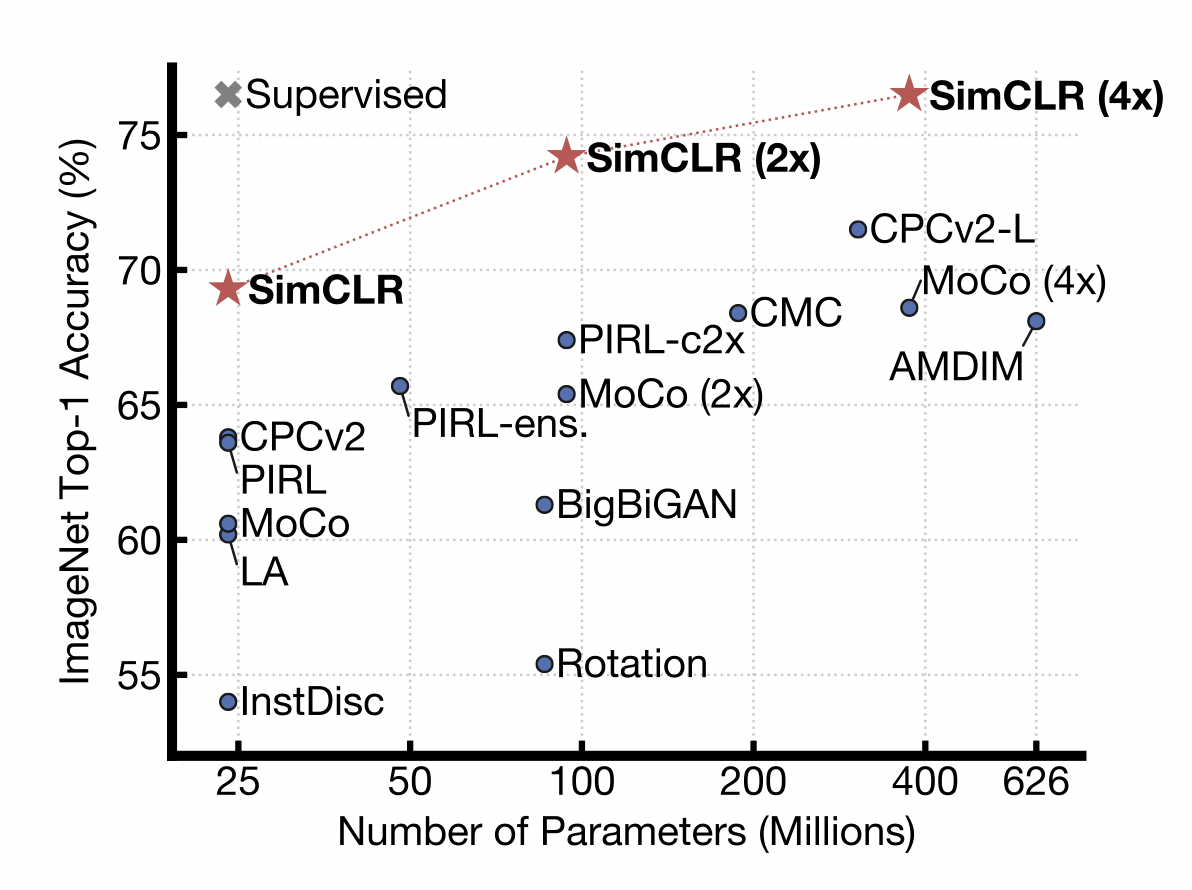
[출처] https://arxiv.org/pdf/2002.05709.pdf, A Simple Framework for Contrastive Learning of Visual Representations
일반적으로 한정된 학습 데이터를 가지고 모델 또는 Loss Function 등 Modification을 진행하여 좋은 결과를 도출하는 것이었다면, Self Supervised Learning에서는 주어진 학습 데이터 외의 label을 모르는 unsupervised 데이터를 학습에 활용하고자 하는 아이디어에서 나온 것이다.
추가적으로, domain 지식이 깊을 때 스스로 데이터를 만들어 학습시키는 방법론인 Self Supervised Data Sampling이 있다.
출처
1. 네이버 부스트캠프 AI Tech Stage 1 기초 강의
'AI > AI 기본' 카테고리의 다른 글
| 딥 러닝에서의 일반화(Generalization)와 최적화(Optimization) (0) | 2022.02.16 |
|---|---|
| 신경망(Neural Network)과 다층 퍼셉트론(Multi Layer Perceptron) (0) | 2022.02.16 |
| PyTorch 딥 러닝 과정에서 자주 발생하는 문제 해결을 위한 팁 (0) | 2022.02.15 |
| PyTorch에서의 하이퍼파라미터(Hyperparameter) 튜닝 (0) | 2022.02.15 |
| PyTorch에서 모델 또는 데이터를 나눠서 Multi GPU 사용하기 (0) | 2022.02.15 |
Contents
소중한 공감 감사합니다.