Data Science/데이터 시각화
Matplotlib 기반의 시각화 라이브러리 Seaborn
- -
2022년 2월 3일(목)부터 4일(금)까지 네이버 부스트캠프(boostcamp) AI Tech 강의를 들으면서 개인적으로 중요하다고 생각되거나 짚고 넘어가야 할 핵심 내용들만 간단하게 메모한 내용입니다. 틀리거나 설명이 부족한 내용이 있을 수 있으며, 이는 학습을 진행하면서 꾸준히 내용을 수정하거나 추가해 나갈 예정입니다.
Seaborn
파이썬 데이터 분석에서 한 번 즈음은 꼭 쓰게 되며, Matplotlib 기반의 통계 시각화 라이브러리이다.
구성, 분포 관계 등 통계 정보를 파악하는 데 유용하다.
Matplotlib 기반이라서 Matplotlib으로 커스텀할 수 있다.
쉬운 문법과 깔끔한 디자인을 특징으로 갖는다.
import seaborn as sns처럼 관용적으로 sns로 import 한다.
왜 별칭을 'sns'라고 정하여 import를 하는가?
다양한 API
Seaborn은 시각화의 목적과 방법에 따라 API를 분류하여 제공하고 있다.
- Categorical API
- Distribution API
- Relational API
- Regression API
- Multiples API
- Theme API
- Matrix API
Count Plot
countplot은 seaborn의 Categorical API에서 대표적인 시각화 모듈로서 범주를 이산적으로 세서 bar plot처럼 막대 그래프로 그려주는 함수이다.
기본적으로 다음과 같은 파라미터가 있다.
xydatahuehue_order
palettecolorsaturateax
이 중 x, y, hue 등은 기본적으로 df(pandas.DataFrame)의 feature를 의미한다. dict라면 key를 의미한다.
# 주로 데이터를 넣고 데이터의 컬럼을 지정하는 게 일반적이다.
sns.countplot(x='race/ethnicity', data=student)
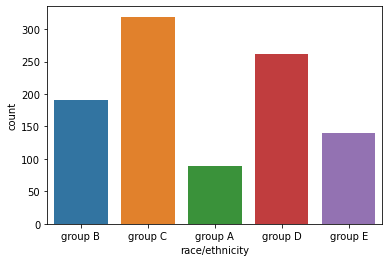
horizontal 방향으로 그래프를 바꾸고 싶으면 y에 보고자 하는 데이터 컬럼을 지정한다.
sns.countplot(y='race/ethnicity',data=student)
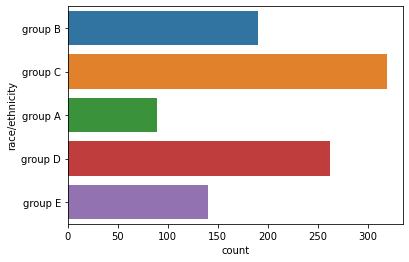
하지만 x, y가 변경되었을 때, 두 축 모두 자료형이 같다면 방향 설정이 원하는 방식대로 진행이 되지 않을 수 있다. 이때는 oriented를 v 또는 h로 전달하여 원하는 시각화를 진행할 수 있다.
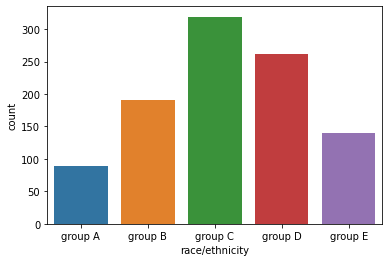
order 파라미터로 데이터의 순서를 지정할 수 있다.
sns.countplot(x='race/ethnicity',data=student,
order=sorted(student['race/ethnicity'].unique())
)
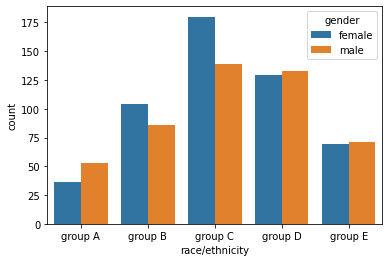
hue는 색을 의미하는데, 데이터의 구분 기준을 정하여 색상을 통해 내용을 구분한다.
sns.countplot(x='race/ethnicity',data=student,
hue='gender',
order=sorted(student['race/ethnicity'].unique())
)
색은 palette 파라미터를 넘겨서 바꿀 수 있다.
hue로 지정된 그룹에 color 파라미터를 지정하여 같은 계열의 Gradient 색상을 전달할 수 있다.
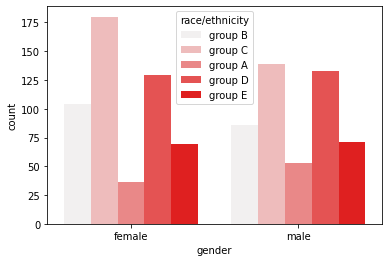
sns.countplot(x='gender',data=student,
hue='race/ethnicity', color='red'
)
matplotlib과 함께 사용하기 적합하게 ax 를 지정하여 원하는 서브 플롯에 seaborn plot을 그릴 수 있다.
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
sns.countplot(x='race/ethnicity',data=student,
hue='gender',
ax=axes[0]
)
sns.countplot(x='gender',data=student,
hue='race/ethnicity',
hue_order=sorted(student['race/ethnicity'].unique()),
ax=axes[1]
)
plt.show()
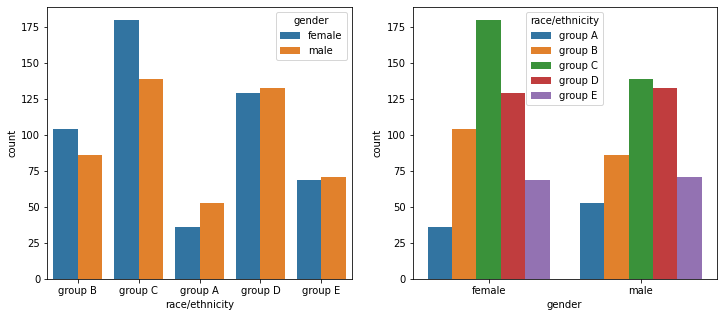
Categorical API
Categorical API를 사용하려면 데이터의 통계량을 기본적으로 알고 있어야 한다.
count- missing value
데이터가 정규분포에 가깝다면 평균과 표준 편차를 살피는 게 의미있을 수 있다.
mean(평균)std(표준 편차)
하지만 데이터가 정규분포에 가깝지 않다면 다른 방식으로 대표값을 뽑는 게 더 좋을 수 있다.
예) 직원 월급 평균에서 임원급 월급은 제외하는 것
분위수란 자료의 크기 순서에 따른 위치값이며, 백분위값으로 표기하는 게 일반적이다. 주로 한쪽으로 편향된 데이터에서 특정 백분위에 위치한 값을 구할 때 유용하다.
- 사분위수 : 데이터를 4등분한 관측값
min25%(lower quartile)50%(median)75%(upper quartile)max
Box Plot
분포를 살피는 대표적인 시각화 방법이며, 중간의 사각형은 25%, medium, 50% 값을 의미한다.
- interquartile range ($IQR$)
- 사각형의 왼쪽과 오른쪽 변의 위치를 의미한다.
- $25th$ to the $75th$ percentile
box plot에서 outlier은 다음과 같이 표현한다.
- whisker
- $±IQR * 1.5$ 범위에 걸친 실제 데이터 분포 구간
- 왼쪽 막대와 오른쪽 막대로 나타낸다.
- 박스 외부의 범위를 나타내는 선
- outlier
- $±IQR * 1.5$ 범위 밖의 점을 의미한다.
- $-IQR * 1.5$과 $+IQR * 1.5$을 벗어나는 값
양쪽의 whisker의 길이가 서로 같지 않을 수 있는데, 이는 실제 데이터의 위치를 반영한다는 점에 유의한다. 즉, $±IQR * 1.5$ 범위에서 실제 데이터가 위치한 최대 최소 값까지를 whisker 구간으로 그리는 것이다.
- $min$ : $-IQR * 1.5$ 보다 크거나 같은 값들 중 최솟값
- $max$ : $+IQR * 1.5$ 보다 작거나 같은 값들 중 최댓값
fig, ax = plt.subplots(1,1, figsize=(12, 5))
sns.boxplot(x='math score', data=student, ax=ax)
plt.show()
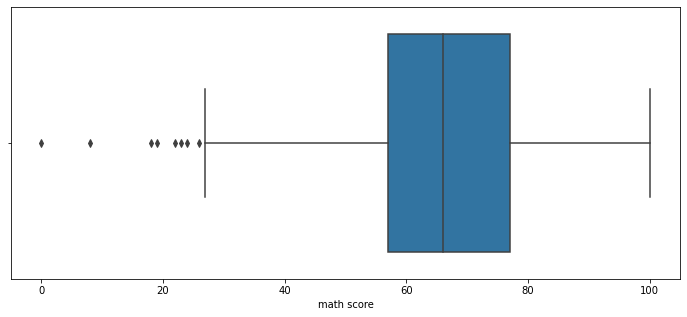
아래의 요소를 사용하여 box plot의 디자인을 커스텀할 수 있다.
widthlinewidthfliersize
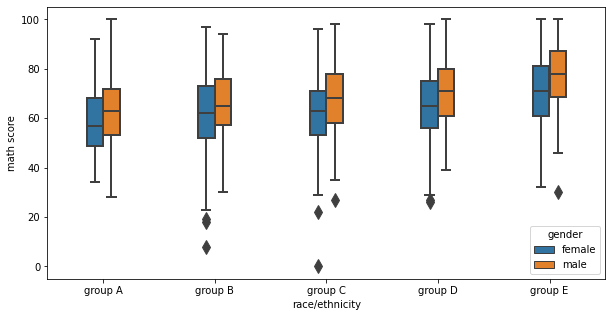
fig, ax = plt.subplots(1,1, figsize=(10, 5))
sns.boxplot(x='race/ethnicity', y='math score', data=student,
hue='gender',
order=sorted(student['race/ethnicity'].unique()),
width=0.3,
linewidth=2,
fliersize=10,
ax=ax)
plt.show()
Violin Plot
box plot은 대푯값을 잘 보여주지만, 분포가 편향되어 있는지 아닌지 등 실제 분포를 표현하기에는 부족하다. 이런 분포에 대한 정보를 더 제공해주기에 적합한 방식 중 하나가 violin plot이다.
이번에는 흰 점이 50%를, 중간의 두꺼운 검정 막대가 IQR 범위를, 중간의 가는 검정 선이 whisker를 의미한다.
fig, ax = plt.subplots(1,1, figsize=(12, 5))
sns.violinplot(x='math score', data=student, ax=ax)
plt.show()
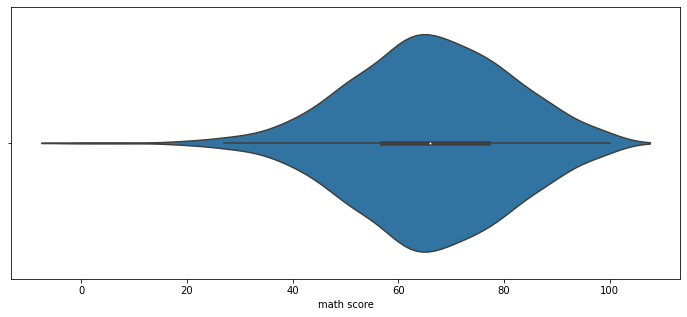
그러나 violin plot은 오해가 생기기 충분한 분포 표현 방식이다.
- 데이터는 연속적이지 않다.
- violin plot은 kernel density estimate를 사용하는데, 근사 과정에서 부정확할 수 있다.
- 연속적 표현에서 생기는 데이터의 손실과 오차가 존재한다.
- 데이터의 범위가 없는 데이터까지 표시된다.
이런 오해를 줄이고 정보량을 높이는 방법은 다음과 같은 방법이 있다.
bw(band width)- 분포 표현을 얼마나 자세하게 보여줄 것인가를 정한다.
- default 값은 0.2이다.
‘scott’,‘silverman’,float
cut- 끝부분을 얼마나 자를 것인가를 정한다.
- float
inner- 내부를 어떻게 표현할 것인가
'box','quartile','point','stick',None
fig, ax = plt.subplots(1,1, figsize=(12, 5))
sns.violinplot(x='math score', data=student, ax=ax,
bw=0.1,
cut=0,
inner='quartile'
)
plt.show()
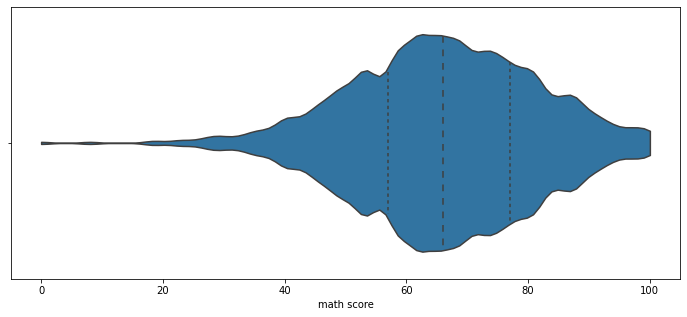
이 외에도 다양한 모양으로 box plot을 디자인하여 그릴 수 있다.
fig, axes = plt.subplots(3,1, figsize=(12, 21))
# 히스토그램처럼 그릴 수 있다.
sns.boxenplot(x='race/ethnicity', y='math score', data=student, ax=axes[0],
order=sorted(student['race/ethnicity'].unique()))
# 각각의 데이터를 하나의 점으로 만들어서 scatter plot처럼 그릴 수 있다.
sns.swarmplot(x='race/ethnicity', y='math score', data=student, ax=axes[1],
order=sorted(student['race/ethnicity'].unique()))
# 직선 막대에 점을 뿌린 것처럼 그려서 밀도로 분포를 표현할 수 있다.
sns.stripplot(x='race/ethnicity', y='math score', data=student, ax=axes[2],
order=sorted(student['race/ethnicity'].unique()))
plt.show()
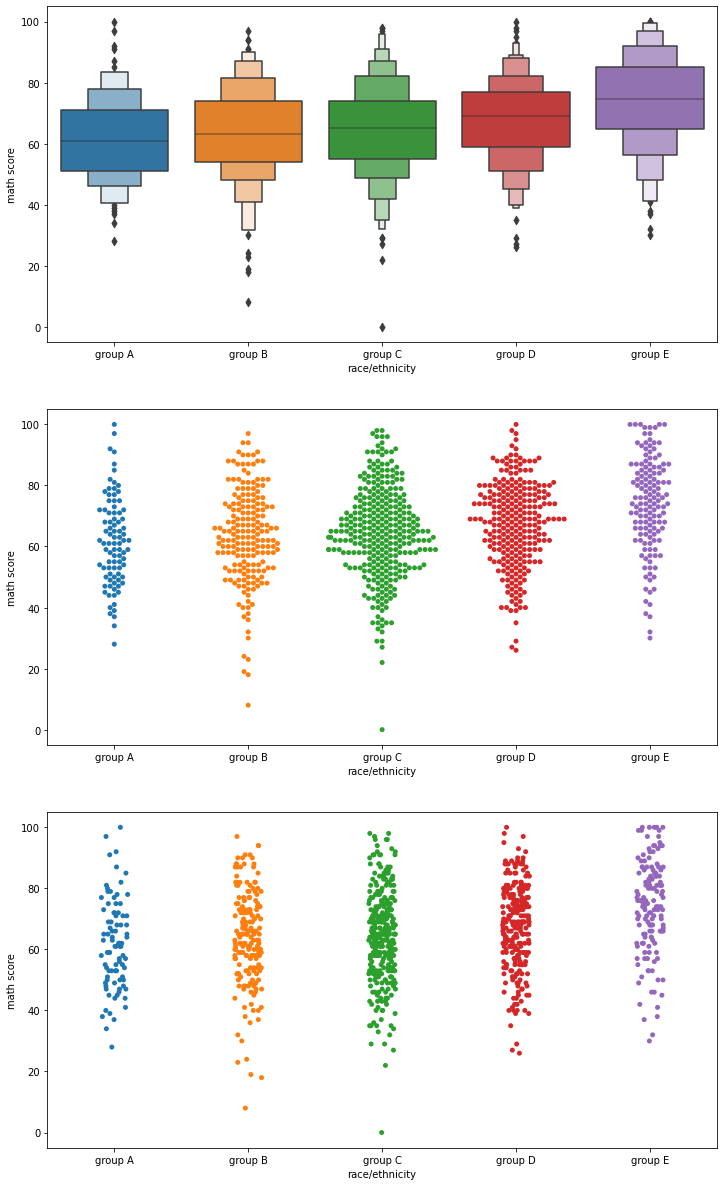
Distribution API
범주형 • 연속형을 모두 살펴볼 수 있는 분포 시각화이다.
Univariate Distribution
histplot
- 히스토그램
- 막대 개수나 간격에 대한 조정은 대표적으로 2가지 파라미터가 있다.
binwidthbins
fig, ax = plt.subplots(figsize=(12, 7))
sns.histplot(x='math score', data=student, ax=ax,
binwidth=50,
bins=100,
)
plt.show()
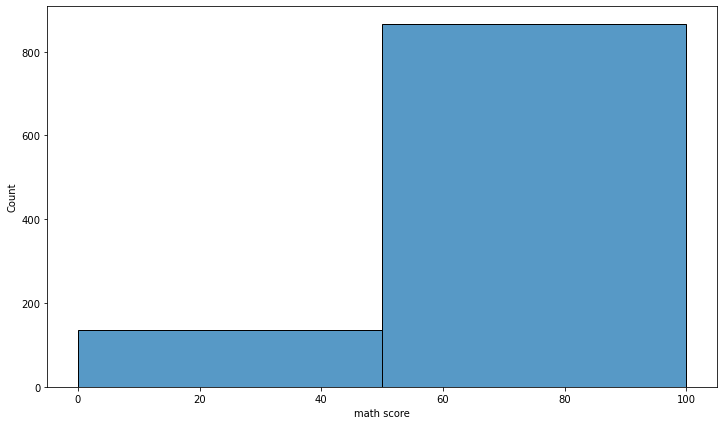
- 히스토그램은 기본적으로 막대지만, seaborn에서는 다른 표현들도 제공하고 있다.
element'poly''step'
fig, ax = plt.subplots(figsize=(12, 7))
sns.histplot(x='math score', data=student, ax=ax,
element='poly' # step, poly
)
plt.show()
- histogram을 여러 방법으로 여러 feature의 분포를 표현할 수 있다.
- 기본적으로는 Overlapped Bar Plot처럼 그린다.
multiple'stack'- Stacked Bar Plot처럼
'layer'- Overlapped Bar Plot처럼
'dodge'- Grouped Bar Plot처럼
'fill'- Percentage Stacked Bar Chart처럼
kdeplot
- Kernel Density Estimate
- 연속확률밀도를 보여준다.
fig, ax = plt.subplots(figsize=(12, 7))
sns.kdeplot(x='math score', data=student, ax=ax)
plt.show()
- 밀도 함수를 그릴 때는 단순히 선만 그려서는 정보의 전달이 어려울 수 있으므로
fill='True'를 전달하여 내부를 채워 표현하는 것이 권장된다.
fig, ax = plt.subplots(figsize=(12, 7))
sns.kdeplot(x='math score', data=student, ax=ax,
fill=True)
plt.show()
bw_method를 사용하여 분포를 더 자세하게 표현할 수도 있다.
fig, ax = plt.subplots(figsize=(12, 7))
sns.kdeplot(x='math score', data=student, ax=ax,
fill=True, bw_method=0.05)
plt.show()
- 분포 표현 방식도 histogram의 연속적인 표현이라고 생각하면 된다.
multiple:stack,layer,fill
cumulative는 처음부터 누적되는 결과를 보여준다.
ecdfplot
- 누적 밀도 함수
- 전체 데이터가 어떤 식으로 누적되는지를 볼 수 있다.
fig, ax = plt.subplots(figsize=(12, 7))
sns.ecdfplot(x='math score', data=student, ax=ax,
hue='gender',
stat='count', # proportion
# complementary=True
)
plt.show()
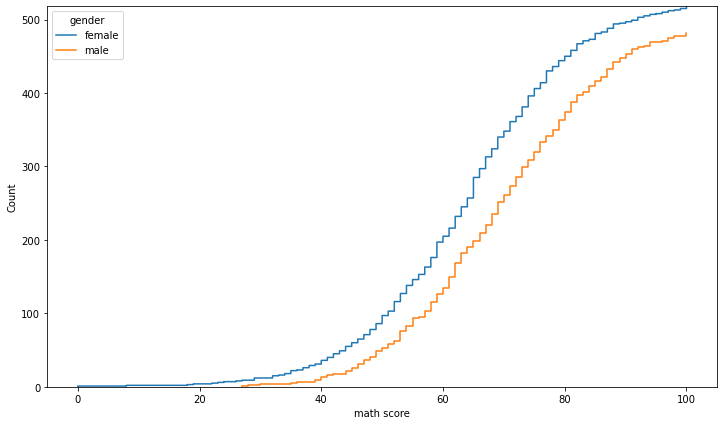
rugplot
- 선을 사용한 밀도함수
- 조밀한 정도를 통해 밀도를 나타낸다.
fig, ax = plt.subplots(figsize=(12, 7))
sns.rugplot(x='math score', data=student, ax=ax)
plt.show()

Bivariate Distribution
두 개 이상 변수를 동시에 분포를 살펴볼 수 있으며, 결합 확률 분포(joint probability distribution) 확인이 가능하다.
함수는 histplot과 kdeplot을 사용하고, 입력에 1개의 축만 넣는 게 아닌 2개의 축 모두 입력을 넣어주는 것이 특징이다.
아래는 histplot 함수를 사용한 방법이다.
fig, axes = plt.subplots(1,2, figsize=(12, 7))
ax.set_aspect(1)
axes[0].scatter(student['math score'], student['reading score'], alpha=0.2)
sns.histplot(x='math score', y='reading score',
data=student, ax=axes[1],
# color='orange',
cbar=False,
bins=(10, 20),
)
plt.show()
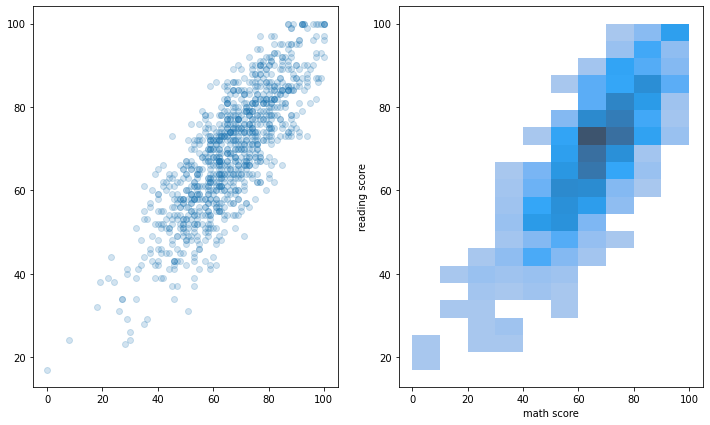
아래는 kdeplot 함수를 사용한 방법이다.
fig, ax = plt.subplots(figsize=(7, 7))
ax.set_aspect(1)
sns.kdeplot(x='math score', y='reading score',
data=student, ax=ax,
fill=True,
# bw_method=0.1
)
plt.show()

Relation API
Scatter Plot
산점도는 다음과 같은 요소를 사용할 수 있다.
stylehuesize
style, hue, size에 대한 순서는 각각 style_order, hue_order, size_order로 전달할 수 있다.
fig, ax = plt.subplots(figsize=(7, 7))
sns.scatterplot(x='math score', y='reading score', data=student,
style='gender', markers={'male':'s', 'female':'o'},
hue='race/ethnicity',
size='writing score',
)
plt.show()
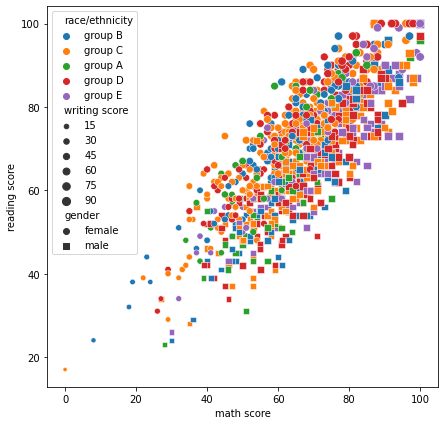
Line Plot
fig, ax = plt.subplots(1, 1,figsize=(12, 7))
sns.lineplot(x='year', y='Jan',data=flights_wide, ax=ax)
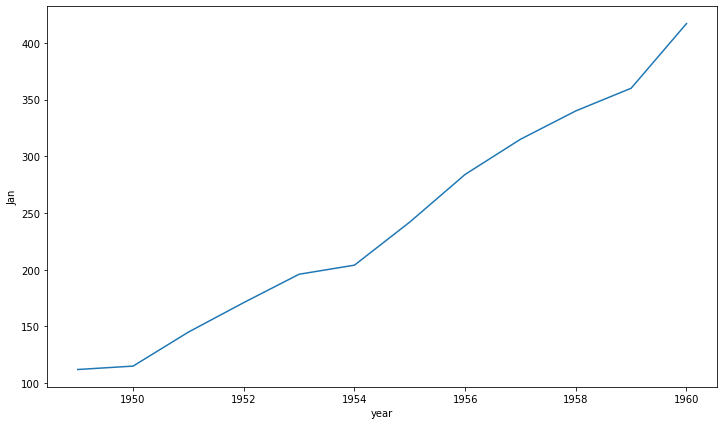
데이터만 넣으면 알아서 hue를 지정한 것처럼 자동으로 그려준다.
fig, ax = plt.subplots(1, 1,figsize=(12, 7))
sns.lineplot(data=flights_wide, ax=ax)
plt.show()
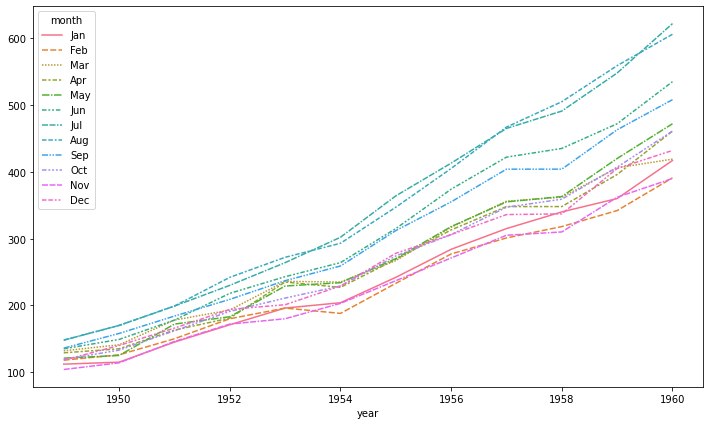
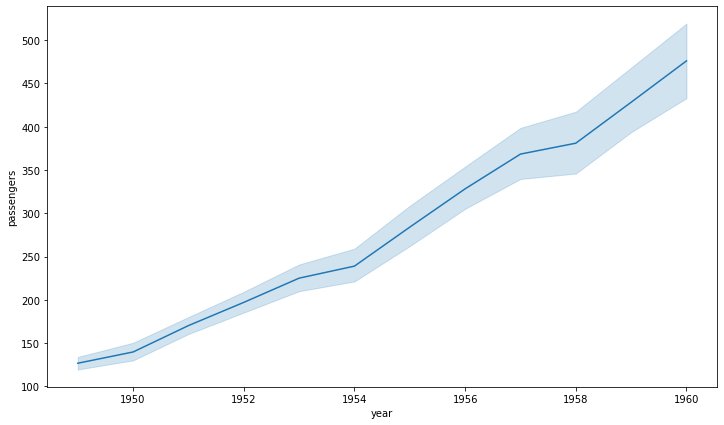
자동으로 평균과 표준편차로 오차범위를 시각화해줄 수 있다.
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
sns.lineplot(data=flights, x="year", y="passengers", ax=ax)
plt.show()
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
sns.lineplot(data=flights, x="year", y="passengers", hue='month',
style='month', markers=True, dashes=False,
ax=ax)
plt.show()
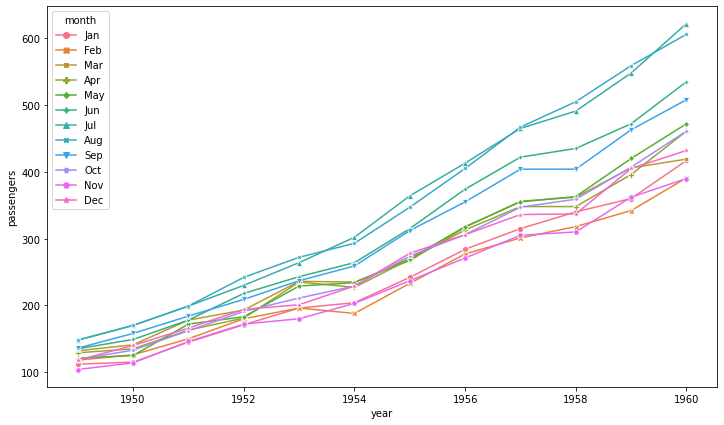
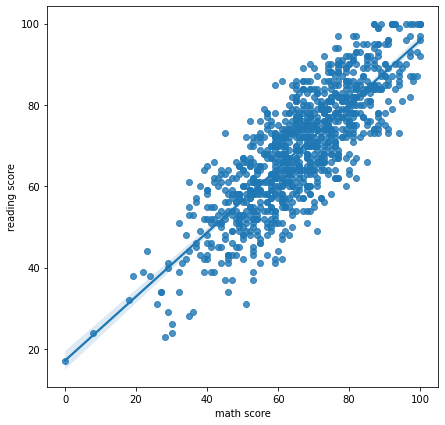
Regression API
Regplot
회귀선을 추가한 scatter plot이다.
fig, ax = plt.subplots(figsize=(7, 7))
sns.regplot(x='math score', y='reading score', data=student,
)
plt.show()
다차원 회귀선은 order 파라미터를 통해 전달할 수 있다. 다만 아래의 예시는 데이터가 적고 선형성이 너무 강해서 회귀식이 선으로 보인다.
fig, ax = plt.subplots(figsize=(7, 7))
sns.regplot(x='math score', y='reading score', data=student,
order=2
)
plt.show()
로그를 사용하여 회귀선을 표현할 수도 있다.
fig, ax = plt.subplots(figsize=(7, 7))
sns.regplot(x='reading score', y='writing score', data=student,
logx=True
)
plt.show()
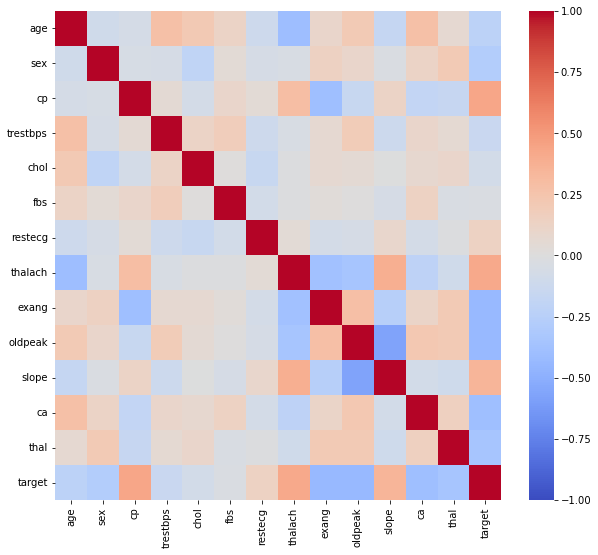
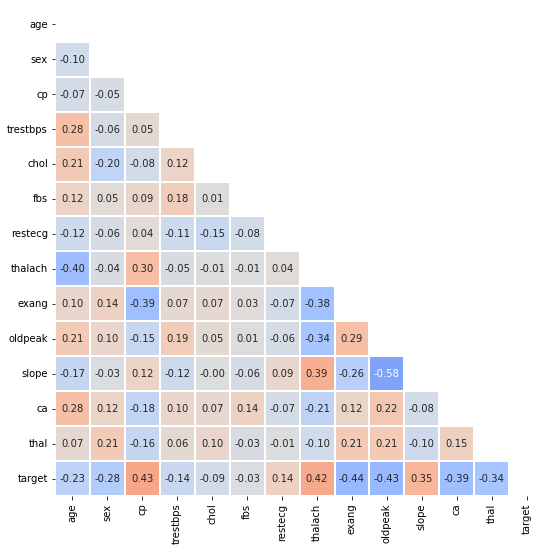
Matrix API
Heatmap
히트은 다양한 방식으로 사용될 수 있으며, 대표적으로는 상관관계(correlation) 시각화에 많이 사용된다
상관관계는 다양한 방법이 있는데, pandas에서는 다음과 같은 방법을 제공한다.
| 방법 | 설명 |
|---|---|
| Pearson Linear correlation coefficient | 모수적 방법(두 변수의 정규성 가정), 연속형 & 연속형 변수 사이의 선형 관계 검정, (-1,1)사이의 값을 가지며 0으로 갈수록 선형 상관관계가 없다는 해석 가능 |
| Spearman Rank-order correlation coefficient | 비모수적 방법(정규성 가정 x), 연속형 & 연속형 변수 사이의 단조 관계 검정, 값에 순위를 매겨 순위에 대한 상관성을 계수로 표현 - 연속형 변수가 아닌 순서형 변수에도 사용 가능 단조성(monotonicity) 평가 - 곡선 관계도 가능 |
| kendall Rank-order correlation coefficient | 비모수적 방법(정규성 가정 x), 연속형 & 연속형 변수 사이의 단조 관계 검정, 값에 순위를 매겨 순위에 대한 상관성을 계수로 표현함 - 연속형 변수가 아닌 순서형 변수에도 사용 가능 단조성(monotonicity) 평가. 일반적으로 Spearman의 rho 상관 관계보다 값이 작다. 일치/불일치 쌍을 기반으로 계산하며 오류에 덜 민감 |
상관계수는 -1~1까지이므로 색의 범위를 맞추기 위해 vmin과 vmax로 범위를 조정한다.
fig, ax = plt.subplots(1,1 ,figsize=(7, 6))
sns.heatmap(heart.corr(), ax=ax,
vmin=-1, vmax=1
)
plt.show()

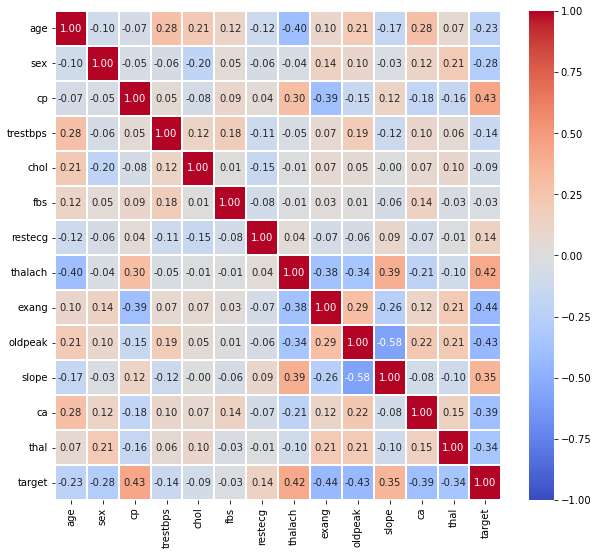
0을 기준으로 상관계수가 음 또는 양의 값을 가지고, 이는 서로 반대의 의미를 가지므로 cmap을 통해 더 가독성이 좋게 시각화할 수도 있다.
fig, ax = plt.subplots(1,1 ,figsize=(10, 9))
sns.heatmap(heart.corr(), ax=ax,
vmin=-1, vmax=1, center=0,
cmap='coolwarm'
)
plt.show()
annot와 fmt를 사용하면 실제 값에 들어갈 내용을 작성할 수 있다.
linewidth를 사용하여 칸 사이를 나눌 수 있고, square를 사용하여 정사각형을 사용할 수도 있다.
fig, ax = plt.subplots(1,1 ,figsize=(10, 9))
sns.heatmap(heart.corr(), ax=ax,
vmin=-1, vmax=1, center=0,
cmap='coolwarm',
annot=True, fmt='.2f',
linewidth=0.1,
)
plt.show()
대칭인 경우나 특정 모양에 따라 필요없는 부분을 mask로 지울 수도 있다.
fig, ax = plt.subplots(1,1 ,figsize=(10, 9))
mask = np.zeros_like(heart.corr())
mask[np.triu_indices_from(mask)] = True
sns.heatmap(heart.corr(), ax=ax,
vmin=-1, vmax=1, center=0,
cmap='coolwarm',
annot=True, fmt='.2f',
linewidth=0.1, square=True, cbar=False,
mask=mask
)
plt.show()
Seaborn Advanced
Joint Plot
Distribution API에서 결합확률 분포를 시각화할 수 있는데, joint plot은 그런 두 개의 Feature의 결합확률 분포와 함께 각각의 분포도 살필 수 있는 시각화를 제공한다.
sns.jointplot(x='math score', y='reading score',data=student,
hue='gender'
)
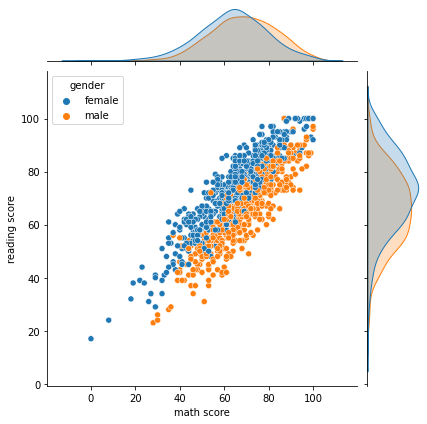
kind 파라미터에 설정할 값을 정해서 원하는 형태의 분포를 그릴 수 있다.
Pair Plot
데이터셋의 pair-wise 관계를 시각화하는 함수이다.
sns.pairplot(data=iris, hue='Species')
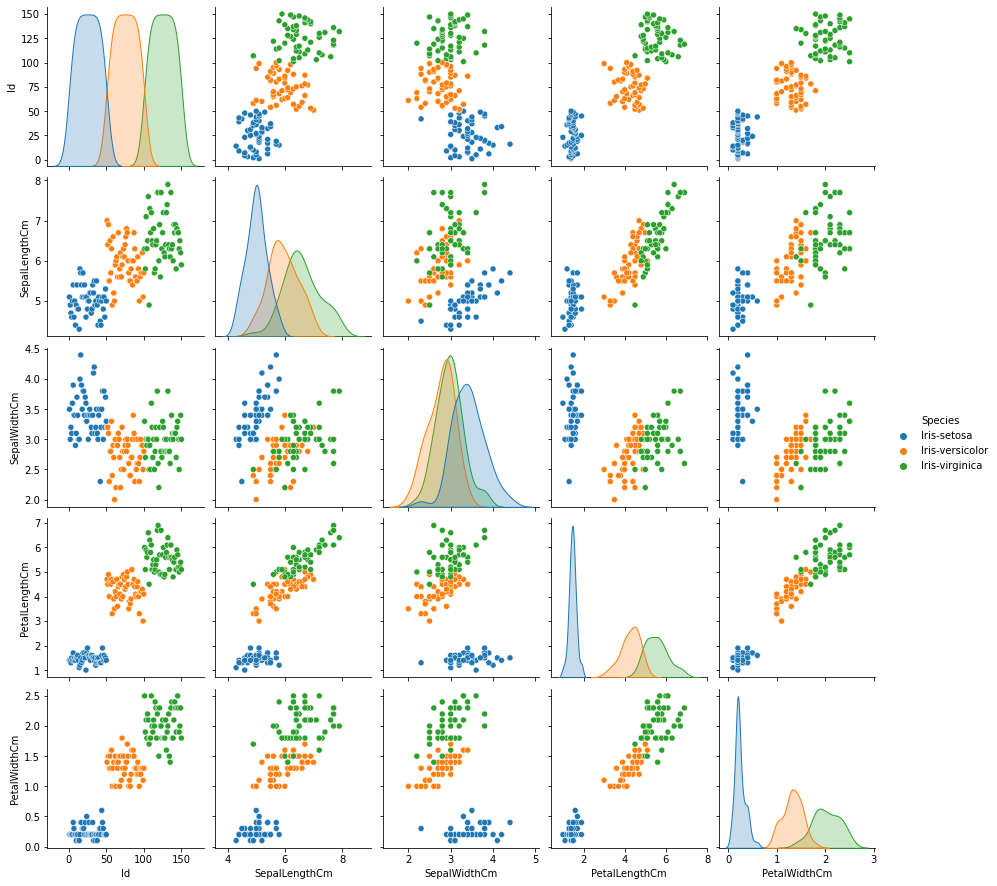
kind는 전체 서브플롯, diag_kind는 대각 서브플롯을 조정한다.
kind: {‘scatter’, ‘kde’, ‘hist’, ‘reg’}diag_kind: {‘auto’, ‘hist’, ‘kde’, None}
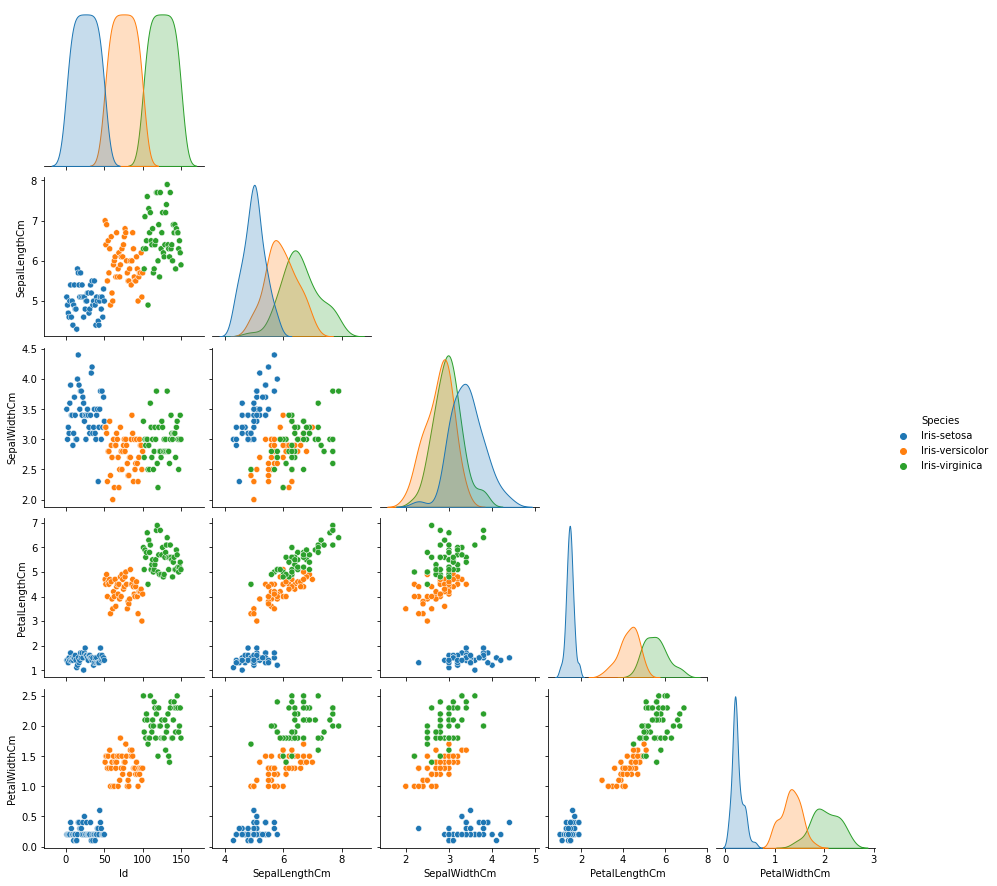
corner = True를 설정하면 상삼각행렬에 해당되는 분포만 볼 수 있다.
sns.pairplot(data=iris, hue='Species', corner=True)
Facet Grid
pairplot과 같이 다중 패널을 사용하는 시각화를 뜻한다.
다만 pairplot은 feature-feature 사이를 살폈다면, Facet Grid는 feature-feature 뿐만이 아니라 feature's category-feature's category의 관계도 살펴볼 수 있다.
총 4개의 큰 함수가 Facet Grid를 기반으로 만들어진다.
catplot: Categoricaldisplot: Distributionrelplot: Relationallmplot: Regression
catplot
catplot은 다음 방법론을 사용할 수 있다.
- Categorical scatterplots:
stripplot()(withkind="strip"; the default)swarmplot()(withkind="swarm")
- Categorical distribution plots:
boxplot()(withkind="box")violinplot()(withkind="violin")boxenplot()(withkind="boxen")
- Categorical estimate plots:
pointplot()(withkind="point")barplot()(withkind="bar")countplot()(withkind="count")
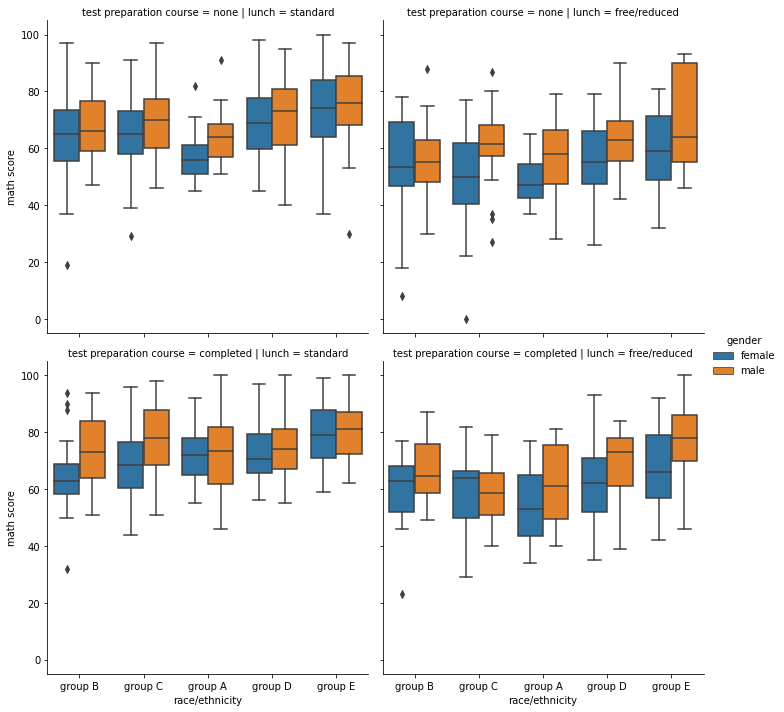
sns.catplot(x="race/ethnicity", y="math score", hue="gender", data=student,
kind='box', col='lunch', row='test preparation course'
)
displot
displot은 다음 방법론을 사용할 수 있다.
histplot()(withkind="hist"; the default)kdeplot()(withkind="kde")ecdfplot()(withkind="ecdf"; univariate-only)
sns.displot(x="math score", hue="gender", data=student,
col='race/ethnicity', # kind='kde', fill=True
col_order=sorted(student['race/ethnicity'].unique())
)

relplot
relplot은 다음 방법론을 사용할 수 있다.
scatterplot()(withkind="scatter"; the default)lineplot()(withkind="line")
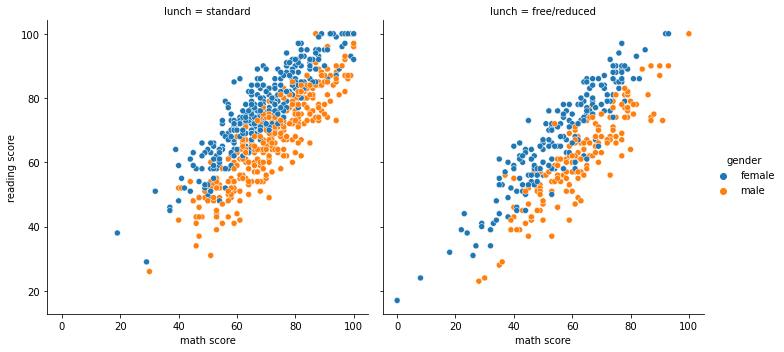
sns.relplot(x="math score", y='reading score', hue="gender", data=student,
col='lunch')
lmplot
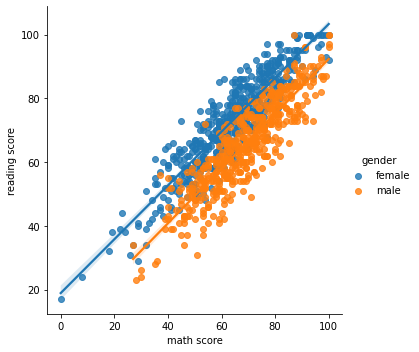
lmplot은 다음 방법론을 사용할 수 있다.
regplot()
sns.lmplot(x="math score", y='reading score', hue="gender", data=student)
'Data Science > 데이터 시각화' 카테고리의 다른 글
| 비정형 데이터 셋에서의 데이터 시각화 (0) | 2022.02.18 |
|---|---|
| Interactive(인터렉티브) 시각화 (0) | 2022.02.18 |
| Matplotlib 모듈로 Chart를 그리기 위한 팁 (0) | 2022.02.15 |
| Matplotlib 모듈로 그린 Chart에서 Facet 사용하기 (0) | 2022.02.15 |
| Matplotlib 모듈로 그린 Chart에서 Color 사용하기 (0) | 2022.02.15 |
Contents
소중한 공감 감사합니다.